 一种动态环境下的直接视觉里程计
一种动态环境下的直接视觉里程计

引言
大部分SLAM系统都应用了静态环境假设,这使得它们难以在复杂动态环境中部署。此外,传统的基于学习的SLAM方法往往都是利用目标检测或语义分割剔除动态物体上的特征,但这样有两个弊端:其一是实际环境中的动态物体不一定被预训练,另一是算法无法区分"动态物体"和"静止但可能移动的物体"。
2. 摘要
基于学习的视觉里程计(VO)算法在常见的静态场景中取得了显著的性能,受益于高容量模型和大规模注释数据,但在动态、人口稠密的环境中往往会失败。语义分割主要用于在估计相机运动之前丢弃动态关联,但是以丢弃静态特征为代价,并且难以扩展到看不见的类别。
在本文中,我们利用相机自我运动和运动分割之间的相互依赖性,并表明这两者可以在一个单一的基于学习的框架中共同优化。特别地,我们提出了DytanVO,第一个基于监督学习的VO方法来处理动态环境。它实时拍摄两个连续的单目帧,并以迭代的方式预测相机的自我运动。
在真实动态环境中,我们的方法在ATE方面比最先进的VO解决方案平均提高了27.7%,甚至在优化后端轨迹的动态视觉SLAM系统中也具有竞争力。大量未知环境上的实验也证明了该方法的普适性。
3. 算法分析
如图1所示是作者提出的DytanVO的整体架构,整个网络是基于TartanVO开发的。DytanVO由从两幅连续图像中估计光流的匹配网络、基于无动态运动的光流估计位姿的位姿网络和输出动态概率掩码的运动分割网络组成。
匹配网络仅向前传播一次,而位姿网络和分割网络被迭代以联合优化位姿估计和运动分割。停止迭代的标准很简单,即两个迭代之间旋转和平移差异小于阈值,并且阈值不固定,而是预先确定一个衰减参数,随着时间的推移,经验地降低输入阈值,以防止在早期迭代中出现不准确的掩码,而在后期迭代中使用改进的掩码。
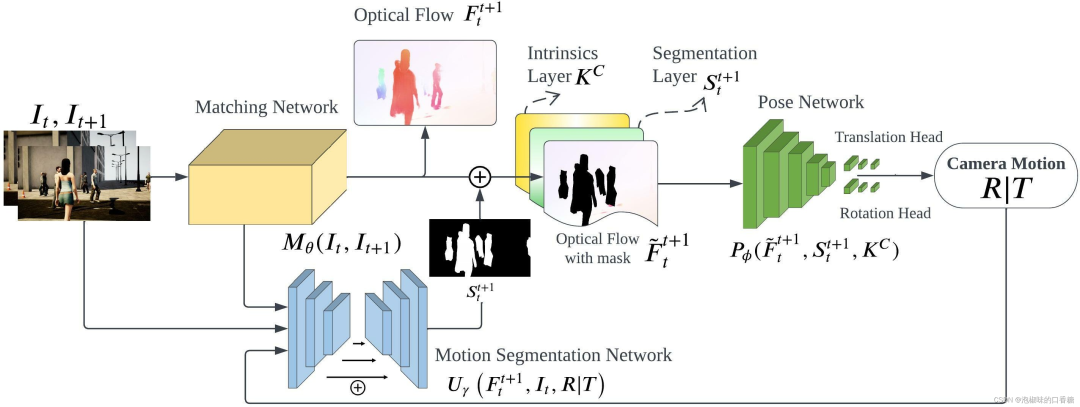
图1 DytanVO架构总览
如图2所示是DytanVO是运行示例,包含两个输入的图像帧、估计的光流、运动分割以及在高动态AirDOS-Shibuya数据集上的轨迹评估结果。结果显示DytanVO精度超越TartanVO达到了最高,并且漂移量很小。
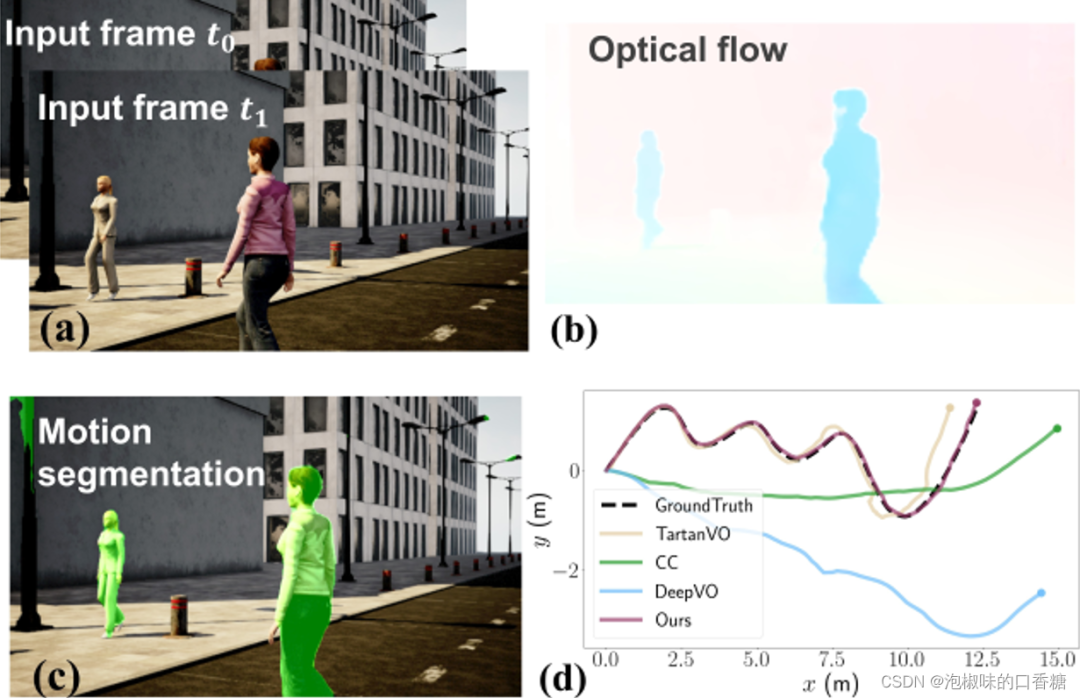
图2 DytanVO运行示例
综上所述,作者提出了第一个基于监督学习的动态环境的VO,主要贡献如下:
(1) 引入了一种新的基于学习的VO来平衡相机自身运动、光流和运动分割之间的相互依赖关系。
(2) 引入了一个迭代框架,其中自我运动估计和运动分割可以在实时应用的时间限制内快速收敛。
(3) 在基于学习的VO解决方案中,DytanVO在真实世界动态场景中实现了最先进的性能,而无需微调。此外,DytanVO甚至可以与优化后端轨迹的视觉SLAM解决方案相媲美。
3.1 运动分割
早期使用运动分割的动态VO方法依赖于由对极几何和刚性变换产生的纯几何约束,因此它们可以阈值化用于考虑运动区域的残差光流。
然而,在两种情况下,它们容易发生严重退化:
(1) 在3D移动中,沿着极线移动的点无法从单目图像中识别出来;
(2) 纯几何学方法对噪声光流和较不准确的相机运动估计没有鲁棒性。
因此,DytanVO通过光学扩展将2D光流升级到3D后,显式地将代价地图建模为分割网络的输入,该网络根据重叠图像块的尺度变化估计相对深度。
3.2 相机运动迭代优化
在推理过程中,匹配网络只前向传播一次,而姿态网络和分割网络进行迭代,共同优化自运动估计和运动分割。在第一次迭代中,使用随机初始化分割掩膜。直觉上会认为,在早期迭代过程中估计的运动不太准确,并导致分割输出(对静态区域赋予高概率)中的误报。然而,由于光流图仍然提供了足够的对应关系,因此相机运动实际上较为合理。在以后的迭代中,估计越来越准确。
在实际应用中,3次迭代足以使相机运动和分割都得到细化。图3所示是迭代过程中的可视化结果,第一次迭代时的掩码包含了大量的假阳性,但在第二次迭代后迅速收敛。这也说明姿态网络对分割结果中的假阳性具有鲁棒性。
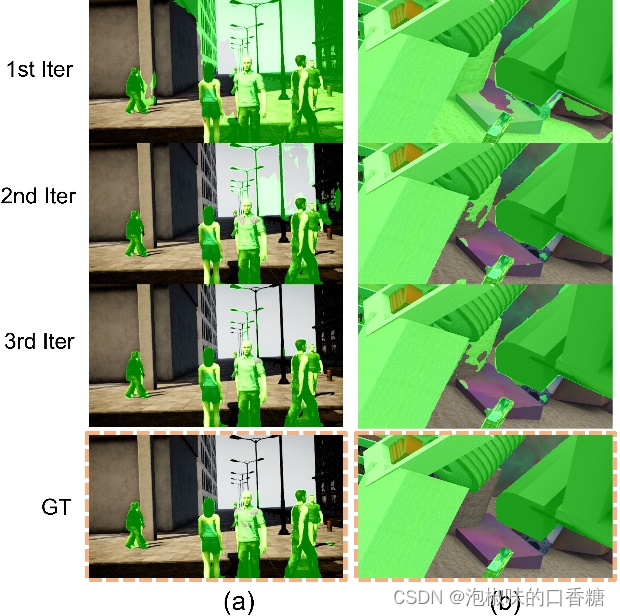
图3 当未见数据上测试时每次迭代的运动分割输出。(a) 使用DytanVO在多人向不同方向移动的情况下,对AirDOS-Shibuya中最难的序列进行推断;(b) 从动态物体占据超过60%面积的FlyingThings3D推断序列。
3.3 损失函数
DytanVO可以以端到端的方式进行训练,损失函数包括光流损失LM,相机运动损失LP和运动分割损失LU。其中LM为预测流和真实流之间的L1范数,而LU是预测概率和分割标签之间的二元交叉熵损失。具体表达形式为:
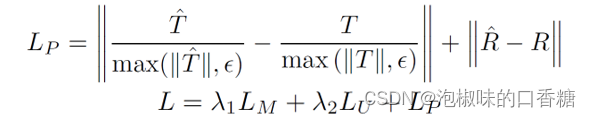
4. 实验
4.1 数据集
DytanVO在TartanAir和SceneFlow上训练,其中前者包含超过40万个数据帧,具有仅在静态环境中的光流和相机姿态真值。后者在高度动态的环境中提供了3.9万帧,每个轨迹具有向后/向前通过、不同的对象和运动特征。虽然场景流不提供运动分割的真值,但可以通过利用其视差、光流和视差变化图来恢复真值。而在评估方面,作者使用AirDOS-Shibuya和KITTI进行测试。
4.2 实施细节
DytanVO使用TartanVO的预训练模型初始化匹配网络,使用来自CVPR论文"Learning to segment rigid motions from two frames"的预训练权重来固定运动分割网络,使用ResNet50作为姿态网络的backbone,并删除了BN层,同时为旋转和平移添加了两个输出头。
DytanVO使用的深度学习框架为PyTorch,并在2台NVIDIA A100上训练。在推理时间方面作者在RTX 2080进行测试,不进行迭代的话推理时间为40ms,进行一次迭代推理时间为100ms,进行两次迭代推理时间为160ms。
4.3 AirDOS-Shibuya数据集测试
如表1所示是关于迭代次数(iter)的消融实验,数据使用来自AirDOS-Shibuya的三个序列。其中姿态网络在第一次迭代后快速收敛,后续迭代显示出较少的改进,这是因为AirDOS-Shibuya上的光流估计已经具有高质量。
表1 关于迭代次数的ATE消融实验
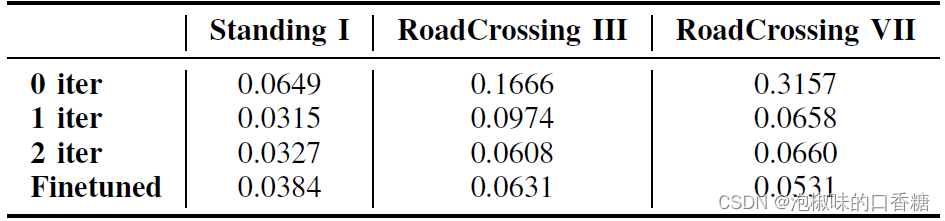
表2所示是在AirDOS-Shibuya的七个序列上,与现有的最先进的VO算法进行的定量对比结果。该基准涵盖了更具挑战性的多种运动模式。这七个序列分为三个难度等级:大多数人站着不动,很少人在路上走来走去,穿越(容易)包含多个人类进出相机的视野,而在穿越道路(困难)中,人类突然进入相机的视野。
除了VO方法之外,作者还将DytanVO与能够处理动态场景的SLAM方法进行了比较。包括DROID-SLAM、AirDOS、VDO-SLAM以及DynaSLAM。
表2 来自AirDOS-Shibuya的动态序列的ATE (m)结果。最佳和次佳VO性能以粗体和下划线显示,"-"来表示初始化失败
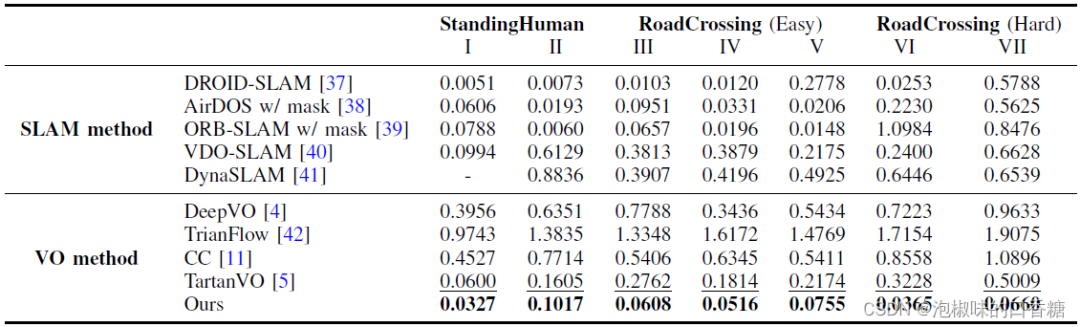
结果显示,DytanVO在VO基线的所有序列中实现了最好的性能,甚至在SLAM方法中也是有竞争力的。DeepVO,TrianFlow和CC在AirDOS-Shibuya数据集上表现很差,因为它们只在KITTI上训练,不能泛化。TartanVO表现更好,但它仍然容易受到动态对象的干扰。
DytanVO优于动态SLAM方法,如AirDOS,VDO-SLAM和dyna SLAM 80%以上。虽然DROID-SLAM在大部分时间都保持竞争力,但一旦行人占据了图像中的大部分区域,它就会跟踪失败。此外,DytanVO的2次迭代每次推理0.16秒,但DROID- SLAM需要额外的4.8秒来优化轨迹。
4.4 KITTI数据集测试
表3所示是DytanVO和其他VO方法在KITTI数据集上的定量对比结果,DytanVO在8个动态序列中的6个中优于其他VO基线,比第二个最好的方法平均提高了27.7 %。注意,DeepVO、TrianFlow和CC是在KITTI中的部分序列上训练的,而DytanVO没有在KITTI上进行微调,纯粹使用合成数据进行训练。
此外,DytanVO在VO和SLAM中的3个序列上实现了最佳的ATE,无需任何优化。图4中提供了关于快速移动的车辆或动态物体在图像中占据大片区域的四个具有挑战性的序列的定性结果。注意,从经过的高速车辆开始的序列01,ORB-SLAM和DynaSLAM都无法初始化,而DROID-SLAM从一开始就跟踪失败。在序列10中,当一辆巨大的货车占据图像中心的显著区域时,DytanVO是唯一保持稳健跟踪的VO。
表3 KITTI里程计动态序列的ATE (m)结果
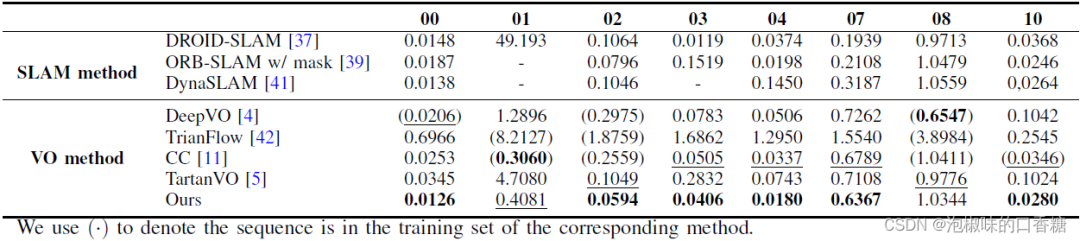
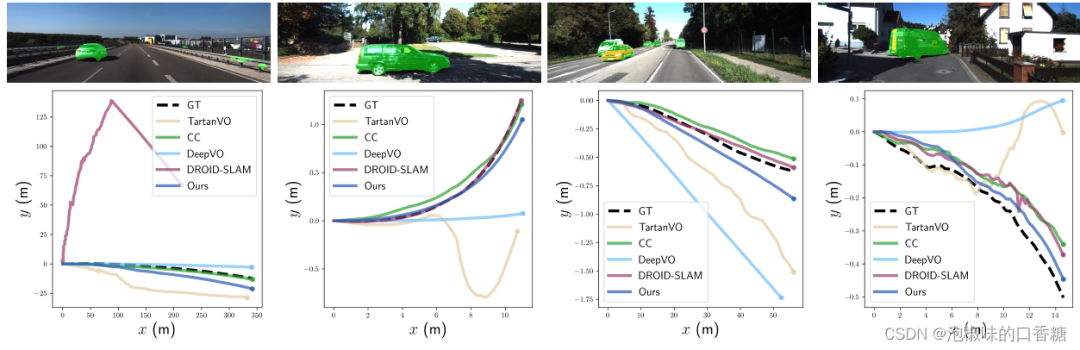
图4 KITTI里程计01、03、04和10中动态序列的定性结果
5. 结论
作者提出了一种基于学习的动态VO (DytanVO),它可以联合优化相机姿态的估计和动态物体的分割。作者证明了自运动估计和运动分割都可以在实时应用的时间约束内快速收敛,并在KITTI和AirDOS-Shibuya数据集上评估了DytanVO,还展示了在动态环境中的一流性能,无需在后端进行微调或优化。DytanVO为动态视觉SLAM算法引入了新的方向。
审核编辑:刘清
-
SLAM
+关注
关注
24文章
456浏览量
33187 -
ATE
+关注
关注
6文章
168浏览量
27764
原文标题:DytanVO:动态环境中视觉里程计和运动分割的联合优化
文章出处:【微信号:GiantPandaCV,微信公众号:GiantPandaCV】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何理解SLAM用到的传感器轮式里程计IMU、雷达、相机的工作原理与使用场景?精选资料分享
如何去实现一种送餐机器人产品设计
基于全景视觉与里程计的移动机器人自定位方法

视觉里程计的详细介绍和算法过程
视觉语义里程计的详细资料说明

计算机视觉方向简介之视觉惯性里程计
基于单个全景相机的视觉里程计
轮式移动机器人里程计分析
介绍一种基于编码器合成里程计的方案

基于相机和激光雷达的视觉里程计和建图系统
在城市地区使用低等级IMU的单目视觉惯性车轮里程计
用于任意排列多相机的通用视觉里程计系统
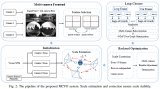
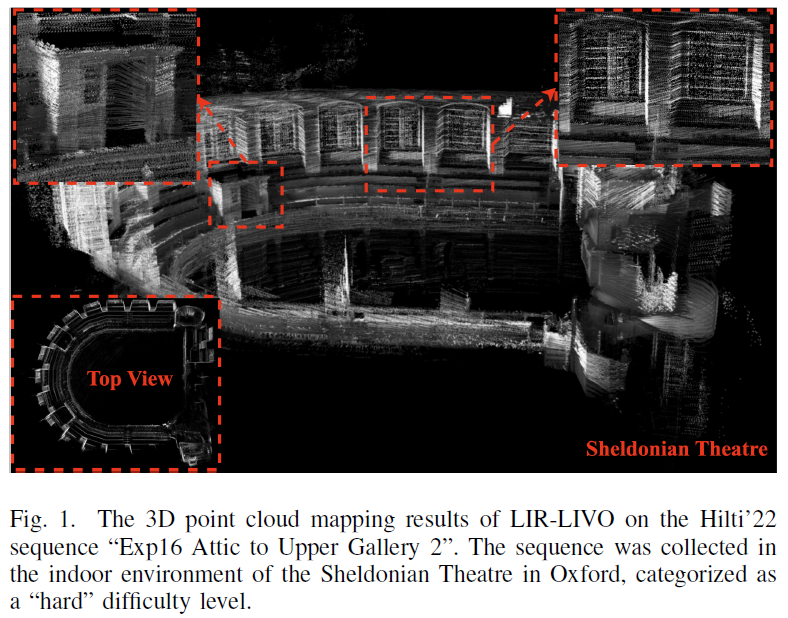
一种新型激光雷达惯性视觉里程计系统介绍





 工商网监
工商网监
评论