 刷SOTA一般通用的trick
刷SOTA一般通用的trick

一般通用的trick都被写进论文和代码库里了
像优秀的优化器,学习率调度方法,数据增强,dropout,初始化,BN,LN,确实是调参大师的宝贵经验,大家平常用的也很多。
这里主要有几个,我们分成三部分,稳定有用型trick,场景受限型trick,性能加速型trick。
稳定有用型trick
0.模型融合
懂得都懂,打比赛必备,做文章没卵用的人人皆知trick,早年模型小的时候还用stacking,直接概率融合效果也不错。
对抗训练
对抗训练就是在输入的层次增加扰动,根据扰动产生的样本,来做一次反向传播。以FGM为例,在NLP上,扰动作用于embedding层。给个即插即用代码片段吧,引用了知乎id:Nicolas的代码,写的不错,带着看原理很容易就明白了。
#初始化 fgm=FGM(model) forbatch_input,batch_labelindata: #正常训练 loss=model(batch_input,batch_label) loss.backward()#反向传播,得到正常的grad #对抗训练 fgm.attack()#在embedding上添加对抗扰动 loss_adv=model(batch_input,batch_label) loss_adv.backward()#反向传播,并在正常的grad基础上,累加对抗训练的梯度 fgm.restore()#恢复embedding参数 #梯度下降,更新参数 optimizer.step() model.zero_grad()
具体FGM的实现
importtorch
classFGM():
def__init__(self,model):
self.model=model
self.backup={}
defattack(self,epsilon=1.,emb_name='emb.'):
#emb_name这个参数要换成你模型中embedding的参数名
forname,paraminself.model.named_parameters():
ifparam.requires_gradandemb_nameinname:
self.backup[name]=param.data.clone()
norm=torch.norm(param.grad)
ifnorm!=0andnottorch.isnan(norm):
r_at=epsilon*param.grad/norm
param.data.add_(r_at)
defrestore(self,emb_name='emb.'):
#emb_name这个参数要换成你模型中embedding的参数名
forname,paraminself.model.named_parameters():
ifparam.requires_gradandemb_nameinname:
assertnameinself.backup
param.data=self.backup[name]
self.backup={}
2.EMA/SWA
移动平均,保存历史的一份参数,在一定训练阶段后,拿历史的参数给目前学习的参数做一次平滑。这个东西,我之前在earhian的祖传代码里看到的。他喜欢这东西+衰减学习率。确实每次都有用。
#初始化 ema=EMA(model,0.999) ema.register() #训练过程中,更新完参数后,同步updateshadowweights deftrain(): optimizer.step() ema.update() # eval前,apply shadow weights;eval之后,恢复原来模型的参数 defevaluate(): ema.apply_shadow() #evaluate ema.restore()
具体EMA实现,即插即用:
classEMA():
def__init__(self,model,decay):
self.model=model
self.decay=decay
self.shadow={}
self.backup={}
defregister(self):
forname,paraminself.model.named_parameters():
ifparam.requires_grad:
self.shadow[name]=param.data.clone()
defupdate(self):
forname,paraminself.model.named_parameters():
ifparam.requires_grad:
assertnameinself.shadow
new_average=(1.0-self.decay)*param.data+self.decay*self.shadow[name]
self.shadow[name]=new_average.clone()
defapply_shadow(self):
forname,paraminself.model.named_parameters():
ifparam.requires_grad:
assertnameinself.shadow
self.backup[name]=param.data
param.data=self.shadow[name]
defrestore(self):
forname,paraminself.model.named_parameters():
ifparam.requires_grad:
assertnameinself.backup
param.data=self.backup[name]
self.backup={}
这两个方法的问题就是跑起来会变慢,并且提分点都在前分位,不过可以是即插即用类型
3.Rdrop等对比学习方法
有点用,不会变差,实现起来也很简单
#训练过程上下文 ce=CrossEntropyLoss(reduction='none') kld=nn.KLDivLoss(reduction='none') logits1=model(input) logits2=model(input) #下面是训练过程中对比学习的核心实现!!!! kl_weight=0.5#对比loss权重 ce_loss=(ce(logits1,target)+ce(logits2,target))/2 kl_1=kld(F.log_softmax(logits1,dim=-1),F.softmax(logits2,dim=-1)).sum(-1) kl_2=kld(F.log_softmax(logits2,dim=-1),F.softmax(logits1,dim=-1)).sum(-1) loss=ce_loss+kl_weight*(kl_1+kl_2)/2
大家都知道,在训练阶段。dropout是开启的,你多次推断dropout是有随机性的。
模型如果鲁棒的话,你同一个样本,即使推断时候,开着dropout,结果也应该差不多。好了,那么它的原理也呼之欲出了。用一张图来形容就是:

随便你怎么踹(dropout),本AI稳如老狗。
KLD loss是衡量两个分布的距离的,所以说他就是在原始的loss上,加了一个loss,这个loss刻画了模型经过两次推断,抵抗因dropout造成扰动的能力。
4.TTA
这个一句话说明白,测试时候构造靠谱的数据增强,简单一点的数据增强方式比较好,然后把预测结果加起来算个平均。
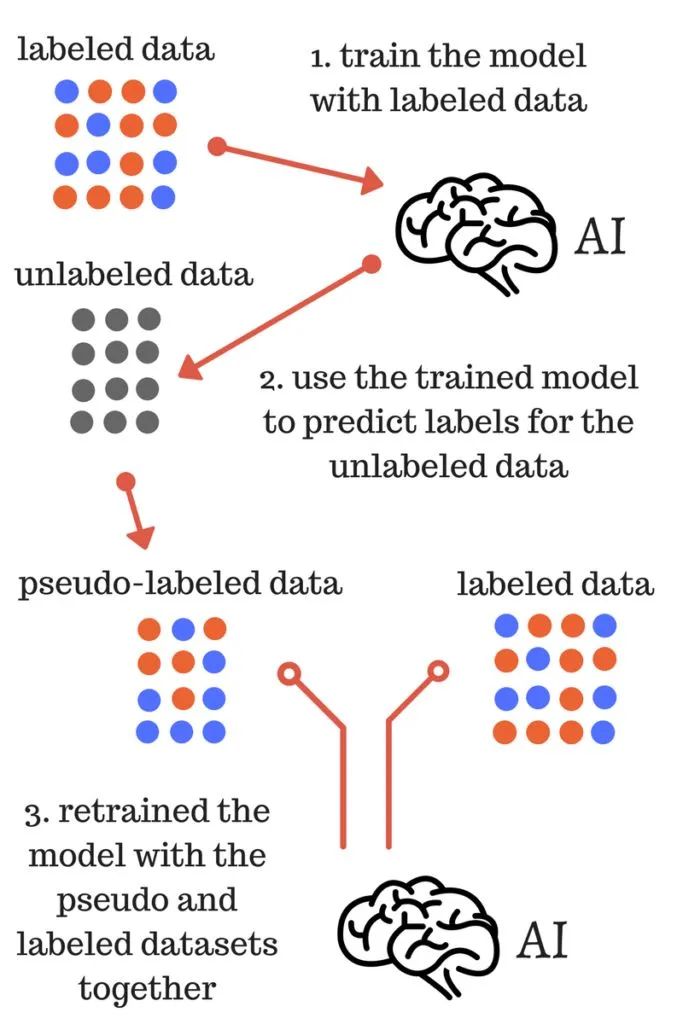
5.伪标签
代码和原理实现也不难,代价也是训练变慢,毕竟多了一些数据一句话说明白,就是用训练的模型,把测试数据,或者没有标签的数据,推断一遍。构成伪标签,然后拿回去训练。注意不要leak。
听起来挺离谱的,我们把步骤用伪代码实现一下。
model1.fit(train_set,label,val=validation_set)#step1 pseudo_label=model.pridict(test_set)#step2 new_label=concat(pseudo_label,label)#step3 new_train_set=concat(test_set,train_set)#step3 model2.fit(new_train_set,new_label,val=validation_set)#step4 final_predict=model2.predict(test_set)#step5
用网上一个经典的图来说就是。
6.神经网络自动填空值
表数据在NN上的trick,快被tabnet 集大成了,这个方法是把缺失值的位置之外的地方mask,本身当成1这样可以学习出一个参数,再加回这个feature的输入上。可以看看他文章的实现。
场景受限型trick
有用但场景受限或者不稳定
1.PET或者其他prompt的方案
在一些特定场景上有用,比如zeroshot,或者小样本的监督训练,在数据量充足情况下拿来做模型融合有点用,单模型不一定干的过硬怼。
2.Focalloss
偶尔有用,大部分时候用处不大,看指标,在一些对长尾,和稀有类别特别关注的任务和指标上有所作为。
3.mixup/cutmix等数据增强
挑数据,大部分数据和任务用处不大,局部特征比较敏感的任务有用,比如音频分类等
4人脸等一些改动softmax的方式
在数据量偏少的时候有用,在工业界数据量巨大的情况下用处不大
5.领域后预训练
把自己的数据集,在Bert base上用MLM任务再过一遍,代价也是变慢,得益于huggingface可用性极高的代码,实现起来也非常简单,适用于和预训练预料差别比较大的一些场景,比如中药,ai4code等,在一些普通的新闻文本分类数据集上用处不大。
6.分类变检索
这算是小样本分类问题的标准解法了,类似于人脸领域的baseline,在这上面有很多围绕类间可分,类内聚集的loss改进,像aa-softmax,arcface,am-softmax等
在文本分类,图像分类上效果都不错。
突破性能型trick
1.混合精度训练
AMP即插即用,立竿见影。
2.梯度累积
在优化器更新参数之前,用相同的模型参数进行几次前后向传播。在每次反向传播时计算的梯度被累积(加总)。不过这种方法会影响BN的计算,可以用来突破batchsize上限。
3.Queue或者memery bank
可以让batchsize突破天际,可以参考MoCo用来做对比学习的那个实现方式
4.非必要不同步
多卡ddp训练的时候,用到梯度累积时,可以使用no_sync减少不必要的梯度同步,加快速度。
审核编辑:刘清
-
PET
+关注
关注
1文章
47浏览量
19208 -
电源优化器
+关注
关注
0文章
11浏览量
5536
发布评论请先 登录
贴片电容的电容量一般多大?

光缆的使用年限一般是好久呢
FCC认证周期一般多久?

FCC认证周期一般多久
测量绝缘电阻一般用什么仪器
功率分析仪的校准周期一般是多久?
电能质量在线监测装置硬件故障检测的一般流程是什么?
AURIX tc367通过 MCU SOTA 更新逻辑 IC 闪存是否可行?
求助,关于TC387使能以及配置SOTA 中一些问题求解
一般光耦的开关电路设计
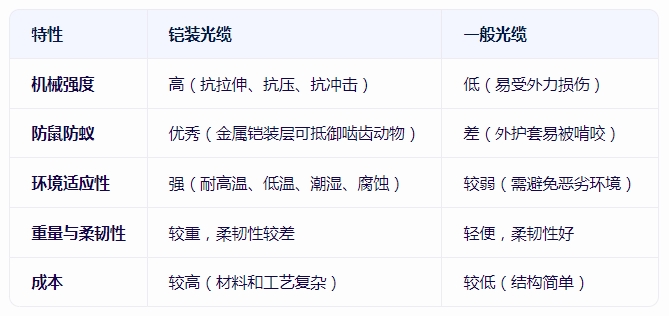
铠装光缆和一般光缆区别对比分析
人脸识别门禁终端的一般故障排查方法




评论