 用于弱监督大规模点云语义分割的混合对比正则化框架
用于弱监督大规模点云语义分割的混合对比正则化框架

为了解决大规模点云语义分割中的巨大标记成本,我们提出了一种新的弱监督环境下的混合对比正则化(HybridCR)框架,该框架与全监督的框架相比具有竞争性。具体而言,HybridCR是第一个利用点一致性,并以端到端方式来使用对比正则化和伪标记的框架。从根本上说,HybidCR明确有效地考虑了局部相邻点之间的语义相似性和3D类的全局特征。我们进一步设计了一个动态点云增强器来生成多样且鲁棒的样本视图,其转换参数与模型训练联合优化。通过大量实验,HybridCR在室内和室外数据集(如S3DIS、ScanNet-V2、Semantic3D和SemanticKITTI)上都比SOTA方法取得了显著的性能改进。
引言
学习大规模点云的精确语义,是机器智能理解复杂3D场景的基本感知任务。现有的基于深度学习的方法严重依赖于用于训练的标记点云数据的可用性和数量[5,21,22,29]。然而,3D point-wise标记既耗时又费力。因此,我们的目标是探索弱监督学习,以最大限度地提高数据效率并减少标记3D点云的工作量。 最近,出现了几种3D点云弱监督语义分割方法,通常可分为三类:
一致性正则化,在随机修改输入或模型function后,利用预测分布的一致性约束。
伪标记,也称为自训练,使用模型预测作为监督。
对比预训练,侧重于模型预训练,然后使用较少的标签对下游任务进行微调。
虽然现有方法取得了令人鼓舞的成果,但仍有一些局限性有待解决。首先,他们没有充分考虑大规模场景中相邻类的语义属性和3D类的全局特征,未能充分利用有限但有价值的标记[33]。其次,许多pipelines [33,38]使用固定/人工的数据增强来获得多视图表示,导致次优的学习,因为增强的强度和类型强烈依赖于模型和数据集大小。此外,在fixed增强中忽略了样本的形状复杂度。第三,现有方法[9,37]通常涉及多个阶段的预训练和微调,与端到端训练方案相比,这增加了训练和部署的难度。 为了解决上述缺点,我们探索分别在标记空间和特征空间中同时利用一致性和对比性。受最近3D PSD[38]和2D FixMatch[27]的启发,我们将伪标签和一致性正则化策略结合到大规模点云的端到端训练方案中。为了更好地使用对比信息,我们重新设计了锚点的正对和负对。一个关键的观察结果是,高级语义场景理解不仅需要局部几何特征,而且还需要全局几何特征,使得点云实例的对比更加充分。此外,受分类任务中的PointAugment[15]的点云实例对比启发,我们进一步引入动态点云增强器,以提供一致性和对比正则化的转换,并进行联合优化。 为了实现上述思想,我们提出了一种新的范式,称为混合对比正则化(HybridCR),用于大规模点云的弱监督语义分割,该范式包括局部和全局指导的对比学习以及动态点云变换。如图1所示,局部引导对比正则化迫使不同视图的数据样本靠近其相邻点,远离其他点。对于全局引导对比正则化,每个样本都被要求靠近其类原型,远离不同类原型。从根本上讲,HybridCR显式有效地考虑了局部相邻点之间的语义相似性和3D点云类的全局特征。此外,所提出的动态点云增强器使用多层感知机(MLP)和高斯噪声来丰富上下文位移中的数据多样性,其中增强器的参数可以与模型训练联合优化。大量实验表明,HybridCR在室内场景(即S3DIS[1]和ScanNet-V2[6])和室外场景(即Semantic3D[8]和SemanticKITTI[2])中都达到了SOTA性能,证明了提出的框架的有效性。 总之,贡献有四个方面: • 提出了框架HybridCR,第一个以端到端的方式利用点一致性和对比特性进行弱监督点云语义分割。 • 引入了局部和全局引导对比正则化,以促进high-level的3D语义场景理解任务。 • 设计了一种新的动态点云增强器,用于转换不同且稳健的样本视图,并在整个训练过程中对其进行了联合优化。 • 与最近的弱监督方法相比,HybridCR取得了显著的性能,在室内和室外数据集中,AP分别提高了平均2.4%和1.0%。 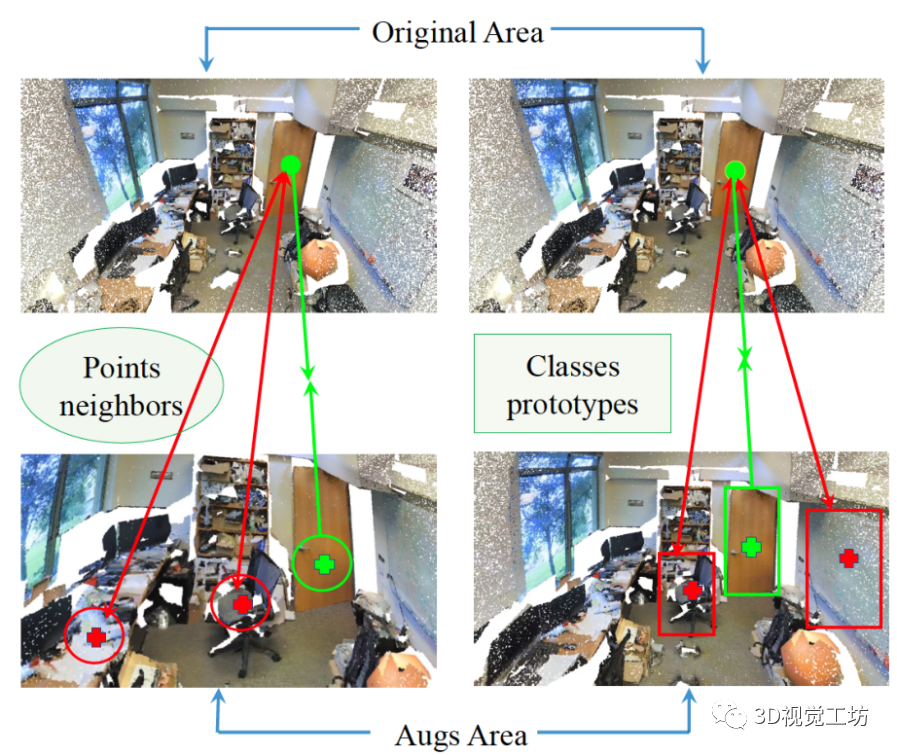 图1. 局部和全局的混合对比正则化。 1)左图:鼓励锚点与匹配的正点及其相邻点(绿色圆圈)相似,而与负点及其相邻点(红色圆圈)不同。 2)右图:鼓励锚点与匹配的正点和属于同一类别的其他点(绿色框中)相似,而与不同类别的负点(红色框中)不同。
图1. 局部和全局的混合对比正则化。 1)左图:鼓励锚点与匹配的正点及其相邻点(绿色圆圈)相似,而与负点及其相邻点(红色圆圈)不同。 2)右图:鼓励锚点与匹配的正点和属于同一类别的其他点(绿色框中)相似,而与不同类别的负点(红色框中)不同。
2、相关工作
2.1、弱监督点云分割
弱监督学习是降低高人工成本的有效方法。一些弱标记方法已经做了初步尝试,例如标记一小部分点[18、33、38]或语义类[31]。现有方法使用各种手段来提高模型的表达能力。它们可以大致分为三类: 一致性正则化 在弱监督图像分类中实现了透视性能[28、36、40]。Xu等人[33]介绍了一种点云特征的多分支监督方法,且采用了两种类型的点云增强和一致性正则化。Zhang等人[38]通过扰动自蒸馏为隐式信息传播提供了额外的监督。Shi等人[26]研究了label-efficient学习,并引入了基于 super-point的主动学习策略。尽管受益于不同网络分支的一致性,但它们没有考虑特征空间中的对比特性。 伪标记 根据由邻域图[11]或自训练[19,35]指定的训练模型[14,24]的预测创建监督。在弱监督环境中。Zhang等人[37]提出了一种基于转移学习的方法,并引入稀疏伪标签来正则化网络学习。Hu等人[18]提出了一种自训练策略,以利用伪标签来提高网络性能。Cheng等人[4]利用动态标签传播方案基于构建的超点图生成伪标签。然而,它们只使用伪标签来获得更多的监督信号,而忽略了标签空间中的一致性属性。 对比预训练 首先由谢等人[32]提出,并通过提出点云场景的对比学习框架来启动这项工作。然而,它主要关注具有100%标签的下游任务。Hou等人[9]利用场景的内在属性来扩展网络可转移性。Li等人[12]提出了引导点对比损失,并利用伪标记学习区分特征。然而,它们只在特征空间中进行point-level的对比,而忽略了点云的内在属性,即几何结构和类语义。 HybridCR重新设计了大规模点云的局部和全局的正负对,并充分探索了如何以端到端的方式利用且增强一致性和对比性。
2.2、点云增强
现有网络中的数据增强[33,38]主要包括随机旋转、缩放和抖动,这些都是在整个训练过程中手工/固定的。Li等人[15]提出了一种利用对抗学习策略的自动增强框架。Chen等人[3]通过实例之间的插值来说明这一点。Kim等人[13]利用局部加权变换产生非刚性变形。但是,他们只关注 object-level的点云。此外,在实际应用中实现它们很复杂,这在训练期间给调整参数带来了困难,并且仅关注object-level点云。我们引入了一个动态点云增强器,在训练期间为大规模点云生成各种变换。 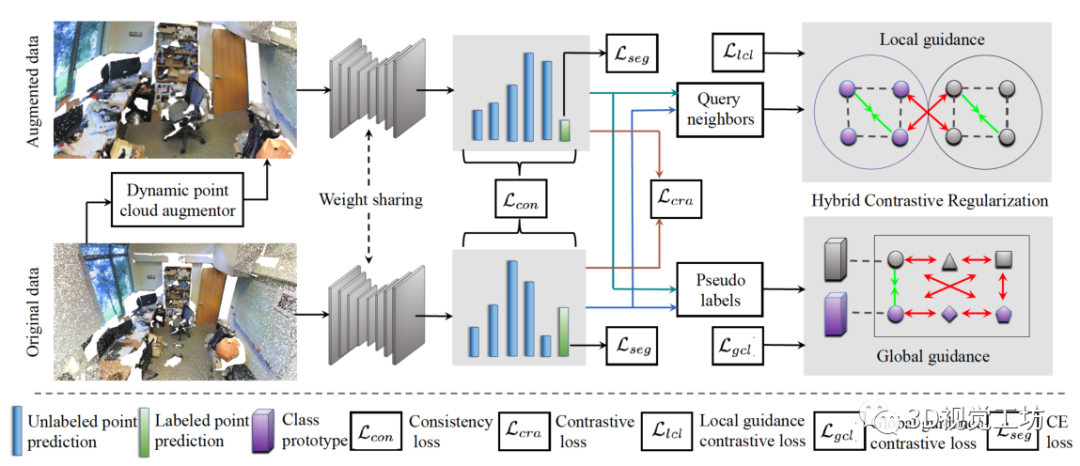 图2. 原始点云首先被输入动态增强器以生成增强点。然后,原始点和增强点通过Siamese网络生成模型对所有点的预测,以及高置信度的未标记点的伪标签。Point-level的一致性损失Lcon和对比损失Lcra用于所有点的预测,而softmax交叉熵损失Lseg用于有标记点的监督。同时,伪标签用于计算每个类的原型。最后,HybridCR从局部和全局两个角度进行,以形成局部和全局引导对比损失(即Llcl和Lgcl),为特征学习提供正则化。通过这种方式,HybridCR为端到端训练方案中的弱监督框架服务。
图2. 原始点云首先被输入动态增强器以生成增强点。然后,原始点和增强点通过Siamese网络生成模型对所有点的预测,以及高置信度的未标记点的伪标签。Point-level的一致性损失Lcon和对比损失Lcra用于所有点的预测,而softmax交叉熵损失Lseg用于有标记点的监督。同时,伪标签用于计算每个类的原型。最后,HybridCR从局部和全局两个角度进行,以形成局部和全局引导对比损失(即Llcl和Lgcl),为特征学习提供正则化。通过这种方式,HybridCR为端到端训练方案中的弱监督框架服务。
3、方法
在本部分中,我们首先描述了第3.1节中的符号和预备知识。然后,我们在第3.2节中介绍了具有局部和全局引导对比正则化的HybridCR的一般框架。接下来,我们在3.3节中介绍动态点云增强器。最后,我们在第3.4节中介绍了training的总体目标。
3.1、预备知识
问题设置和符号。

点级一致性和对比。点级一致性[33,38]已广泛用于弱监督点云语义分割,它将具有不同增强的关联点对强制到Siamese网络中,以具有相同的特征表示。形式上,点级一致性损失公式为
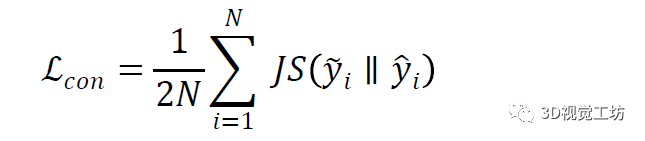


高级语义场景理解任务不仅需要局部信息,还需要全局信息,仅在point-level直接对比3D实例是不够的[17,32]。因此,这促使我们探索更有效的对比策略,以充分利用点云在几何结构和类语义中的固有特性。
3.2、混合对比正则化
如图2所示,我们为大规模点云提出了一个紧凑的弱监督语义分割框架,该框架包含新型混合对比正则策略(HybridCR),且具有有效的动态点云增强器。原始点云首先被输入到动态点云增强器,以生成不同的变换。然后,原始输入点和增强点通过Siamese网络,使用模型对未标记点的预测来生成伪标签。通过使用不同变换的匹配3D点对,鼓励模型在训练期间学习相似和鲁棒的特征。同时,生成的伪标签用于计算每个类的原型。最后,在局部和全局引导的角度上,进行HybridCR,以学习未标记点和标记点之间的特征关系,这也利用了标记点的传统分割损失,且具有点级一致性和对比损失。 3.2.1 局部引导对比正则化 局部邻域信息对于点云对象的特征学习至关重要。例如,遮挡和孔洞始终存在于室内和室外场景的对象中。如果模型从其他完整对象中学习局部结构信息(球体、角点等),则可以在训练期间增强模型对不完整对象的鲁棒性。而点云的局部特征主要来自于点及其邻域,这启迪我们通过提出的局部引导对比正则化,来建模点云的局域信息。为了实现这一点,我们首先查询锚点的相邻点,然后促使每个点的不同增强视图靠近其相邻点,远离其他点。

事实上,提出的局部引导对比损失更一般化为等式2。注意,如果K设置为1,等式4退化为等式2。 3.2.2 全局引导对比正则化

3.3、动态点云增强器
数据增强器是所提出的HybridCR中一个重要的组成部分,它生成各种锚点、正负样本,并通过在输入中添加特定噪声来提取不变表示。受[15]的启发,我们使用MLP和高斯噪声来实现可学习的动态点云增强器,它丰富了上下文位移中的数据多样性,并在同一场景中生成不同的变换。

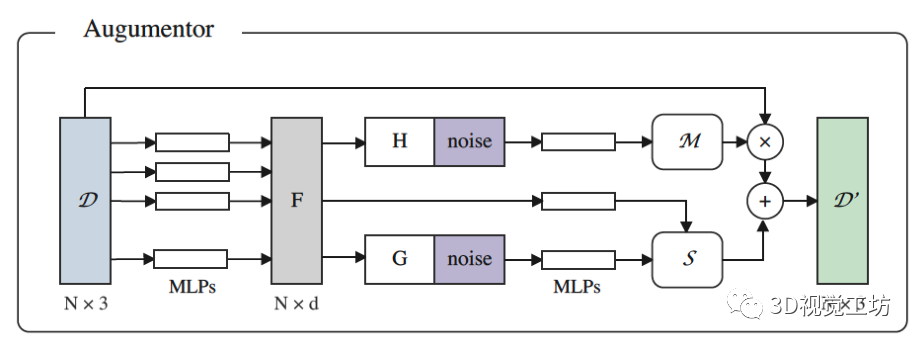 图3. 动态点云增强器的架构。与[33,38]中采用的传统增强器相比,在训练期间进行了联合优化。
图3. 动态点云增强器的架构。与[33,38]中采用的传统增强器相比,在训练期间进行了联合优化。
3.4、总体目标
如上所述,在端到端地训练方案中,HybridCR可以作为弱监督点云语义分割框架的有效对比正则化策略。网络的总体目标如下:

4、实验
4.1、实验设置
实验数据集包含S3DIS[1]、ScanNetV2[6]、Semantic3D[8]和SemanticKITTI[2]。S3DIS是用于语义分割的常用室内3D点云数据集。它有271个点云场景,跨越6个区域,共13个类别。ScanNet-V2也是一个室内三维点云数据集,包含1613个三维扫描,共20个类别。整个数据集被分成训练集(1201个扫描)、验证集(312个扫描)和测试集(100个扫描)。Semantic3D是一个室外数据集,它提供了一个具有超过40亿个点的大规模标记3D点云。它涵盖了一系列不同的城市场景,原始3D点有8类,包含多种信息,如3D坐标、RGB信息和强度。SemanticKITTI是一个大型户外点云数据集,用于自动驾驶场景中的3D语义分割,共有19个类。数据集包含22个序列,这些序列被划分为训练集(10个序列,有19k帧)、验证集(1个序列,有4k帧)和测试集(11个序列,有20k帧)。 实现细节。我们使用初始学习率为0.001、动量为0.9的Adam优化器,在NVIDIA RTX Titan GPU上为所有数据集训练100个epochs。相邻点的数量K为16,batch-size为6,初始学习率为0.01,衰减率为0.98,每个epoch的迭代steps设置为500。注意,由于其有效性和效率,我们选择基于点的backbone PSD[38]作为baseline。 评估协议。我们评估原始测试集中所有点的最终性能。为了进行定量比较,我们使用平均交并比(mIoU)作为度量标准。我们实验研究了两种类型的弱标记:1pt和1%设置。此外,我们将HybridCR扩展到全监督的方式。 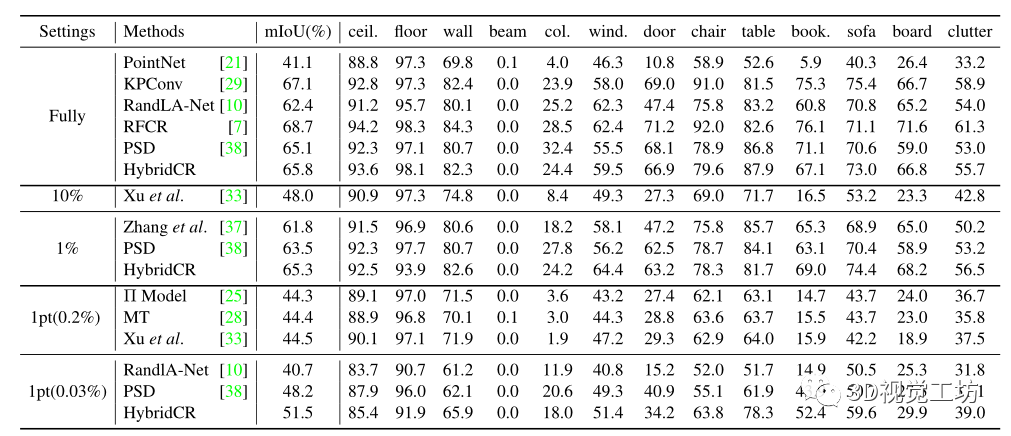 表1 . S3DIS区域5的定量结果。“*”表示我们使用官方代码训练的方法的结果。请注意,我们的1pt表示整个空间中每个类别仅有一个标记点,而不是Xu等人[33]的小块(例如1×1米)。在我们的1pt设置中,标记点的数量占总点的0.03%,在Xu等人[33]中约为0.2%。
表1 . S3DIS区域5的定量结果。“*”表示我们使用官方代码训练的方法的结果。请注意,我们的1pt表示整个空间中每个类别仅有一个标记点,而不是Xu等人[33]的小块(例如1×1米)。在我们的1pt设置中,标记点的数量占总点的0.03%,在Xu等人[33]中约为0.2%。
4.2、与SOTA方法比较
在S3DIS和ScanNet-V2上的定量结果。首先,我们将HybridCR与S3DIS Area-5上的SOTA方法进行了比较,其定量结果在表1中总结。显然,与Zhang等人[37]、PSD[38]、Π模型[25]、MT[28]、Xu等人[33]和RandLA Net[10]相比,我们所提出的HybridCR在1pt和1%的设置下实现了最高的mIoU。例如,在1pt(0.03%)的设置时,我们的方法比PSD和RandLA Net分别高出3.3%和10.8%。此外,与Xu等人[33]相比,我们的方法还实现了7.0%的性能增益,Xu等人利用了约0.2%的更多点标记。在1pt(0.03%)设置下的特定类方面,我们的方法显著提高了性能,相对于PSD,“椅子”、“桌子”和“沙发”分别提高了8.7%、16.4%和8.9%。 对于1%的设置,我们的方法比PSD baseline获得1.8%的mIoU增益,甚至超过Xu等人在设置为10%时[33]。为了解释这一点,我们的方法通过添加所提出的hydrid对比正则化,从大规模点云数据中学习不同的几何结构。基于此,我们的方法仅使用1%的点来优于全监督的RandLA-Net和PSD。为了进行公平的比较,我们还扩展了在 6-fold设置时、基于S3DIS数据集与其他方法的比较,其结果如表2所示。对于ScanNet-V2,与基于场景或者subcloud-level标注的WyPR[23]和MPRM[31]相比,HybridCR在测试集上的1%设置下实现了56.8%的最高mIoU。同时,在相同数量的标注下,HybridCR比Zhang等人实现了5.7%的mIoU增益。此外,在全监督的情况下,我们的方法比RandLA-Net实现了2.1%的mIoU增益。 S3DIS和ScanNet-V2的定性结果。 我们分别在图4和图5中展示了S3DIS的定性结果和Scanne-V2的定量结果。在S3DIS上,与PSD相比,HybridCR在“板”和“椅子”上实现了更好的分割。此外,HybridCR的分割结果与真实情况非常一致。在ScanNet-V2上,我们观察到HybridCR获得了良好且真实的分割结果。在ScanNet-V2上,与PSD相比,HybridCR在“沙发”和“书桌”上表现良好。原因可能是,HybridCR可以有效地利用动态点云增强器生成的各种变换来提高表示能力并提高分割性能。 Semantic3D和SemanticKITTI的定量结果。我们进一步评估了在室外大型点云数据集Semantic3D(reduced-8)和SemanticKITTI上的HybridCR,并将结果分别显示在表2中。对于Semantic3D,与Zhang等人[37]和PSD相比,我们的方法在1%的设置下也实现了更好的性能,mIoU改善了4.2%和1.0%。对于SemanticKITTI,我们的方法在1%的设置下,在验证和测试数据集上报告的结果分别为51.9%和52.3%。可以看出,我们的方法在标注有限的情况下大大优于其他基于点的方法。 Semantic3D和SemanticKITTI的定性结果。 我们分别在图6和图7中给出了Semantic3D和SemanticKITTI的定性结果。在Semantic3D上,我们的方法是对PSD的改进,特别是实现了对“建筑物”的精确分割。在SemanticKITTI上,可以看出,我们的方法实现了与ground-truth的一致性分割结果,特别是在“道路”和“汽车”中,这两个场景在自动驾驶应用中很难区分,但在稀疏的室外场景中很关键。结果证明了该方法在室外数据集上的有效性。 全监督设置的结果。 基于室内和室外数据集,我们进一步扩大了与当前SOTA方法的全监督设置上的比较,其定量结果在表2中总结。可以看出,HybridCR在它们之间具有竞争力。例如,HybridCR在S3DIS和ScanNet-V2上分别以0.7%和2.1%的mIoU改进超过了RandLA Net,在SemanticKITTI上获得0.1%mIoU改善。此外,在mIoU中,HybridCR在Semantic3D上比KPConv高1.8%。 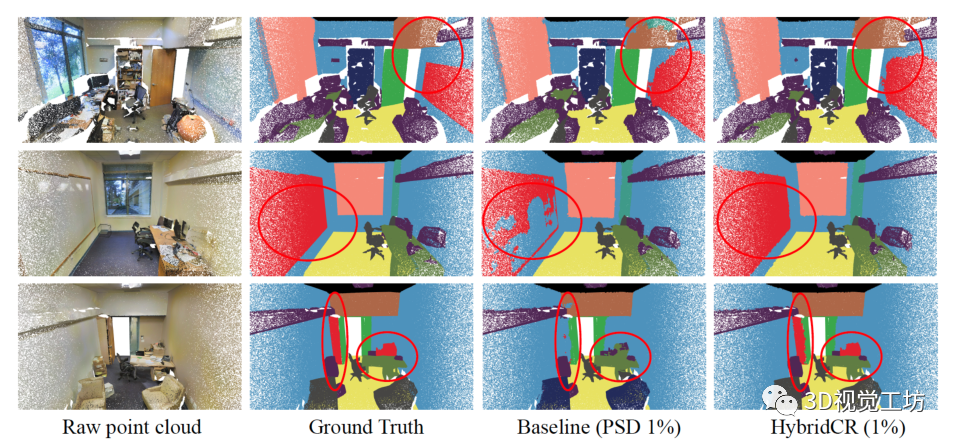 图4. S3DIS Area-5测试集的可视化结果。原始点云、语义标签、baseline结果和我们的结果,分别从左到右显示。
图4. S3DIS Area-5测试集的可视化结果。原始点云、语义标签、baseline结果和我们的结果,分别从左到右显示。 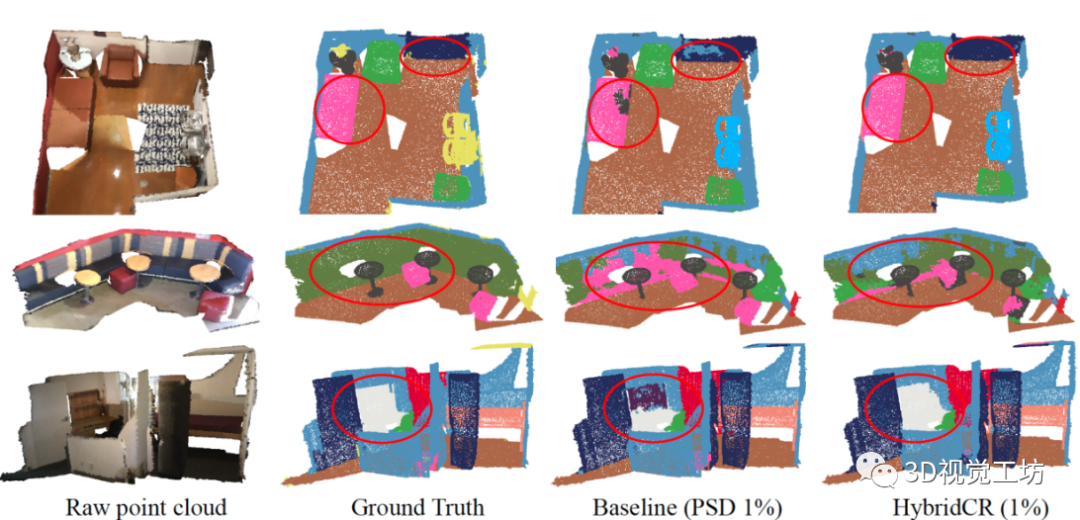 图5. ScanNetV2验证集的可视化结果。原始点云、语义标签、基线结果和我们的结果,分别从左到右显示。
图5. ScanNetV2验证集的可视化结果。原始点云、语义标签、基线结果和我们的结果,分别从左到右显示。 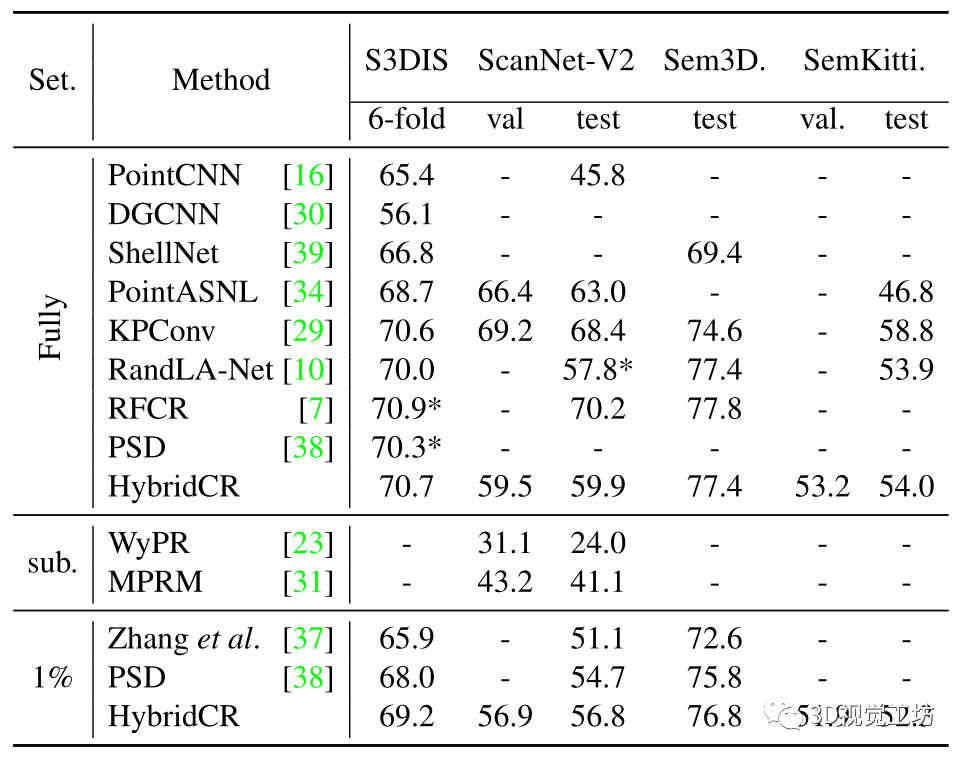 表2. S3DIS 6-fold、ScanNetV2验证集、Semantic3D(reduced-8)和SemanticKITTI验证集的定量结果(mIoU(%)),带有完全标记数据和1%标记数据。特别地是,在100%标记数据的实验中,我们的混合对比损失用作辅助特征学习损失。“*”表示我们使用官方代码训练的方法的结果。
表2. S3DIS 6-fold、ScanNetV2验证集、Semantic3D(reduced-8)和SemanticKITTI验证集的定量结果(mIoU(%)),带有完全标记数据和1%标记数据。特别地是,在100%标记数据的实验中,我们的混合对比损失用作辅助特征学习损失。“*”表示我们使用官方代码训练的方法的结果。 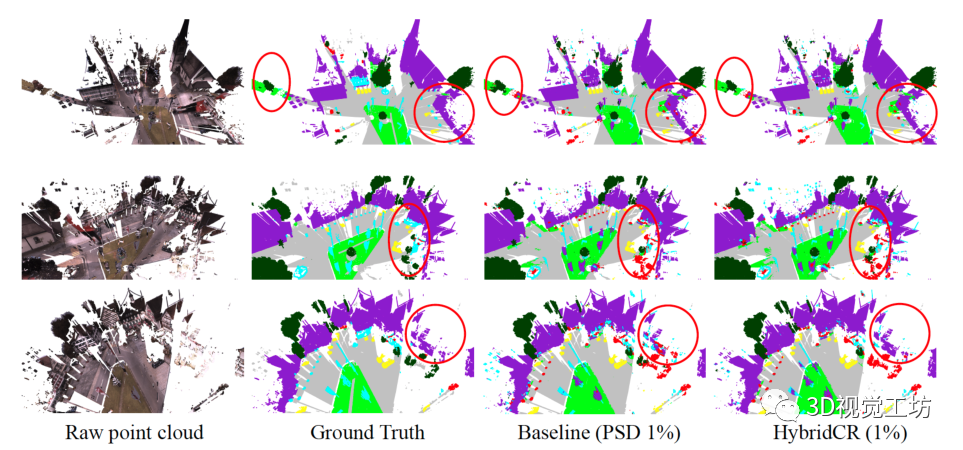 图6. Semantic3D验证集的可视化。原始点云、语义标签、基线结果和我们的结果,从左到右分别显示。
图6. Semantic3D验证集的可视化。原始点云、语义标签、基线结果和我们的结果,从左到右分别显示。 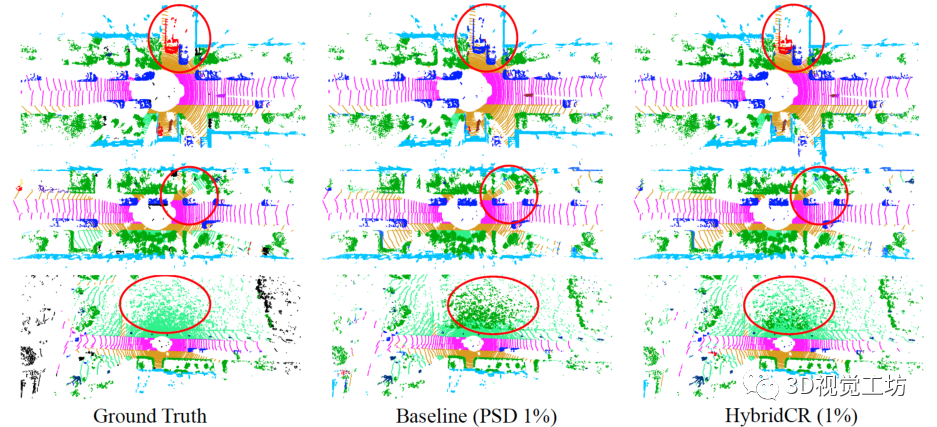 图7. SemanticKITTI验证集的可视化结果。语义标签、基线结果和我们的结果,从左到右分别显示。
图7. SemanticKITTI验证集的可视化结果。语义标签、基线结果和我们的结果,从左到右分别显示。
4.3、消融研究
我们进一步评估消融研究的基本组件的有效性,包括动态点云增强器和局部/全局引导对比正则化。所有实验均在S3DIS Area-5上进行,结果如表3所示。请注意,#1由PSD报告,而#8由HybridCR报告,我们使用平均值和标准偏差(5 runs)报告结果。 动态数据增广器的有效性。为了验证数据增广带来的改进,我们比较了Base。在带有数据增强时,进行相比,在1pt和1%的设置下,#1和#2分别获得了2.5%和1.0%的增益。对于#5和#8,在1pt和1%设置下,其分别比HybridCR获得了0.4%和0.3%的增益。结果表明,通过不同的转换,HybridCR从数据增强中获得了许多好处。 局部引导对比损失的有效性。在1pt和1%设置下,从#1和#3的比较来看,它在mIoU方面分别比Base 优于1.6%和0.4%。对于#7和#8,其分别比HybridCR提高0.5%和0.2%。这些结果表明。这进一步提高了性能,因为它在增强特征学习的同时,利用了模型训练期间的相邻信息。 全局引导对比损失的有效性。类似地,从#1和#4的比较来看,它优于Base。在1pt和1%的设置下分别增加2.0%和0.5%。对于#6和#8,它分别比HybridCR获得1.3%和0.6%的增益。结果表明,全局引导利用类原型有效地提高了弱监督语义分割任务的性能。 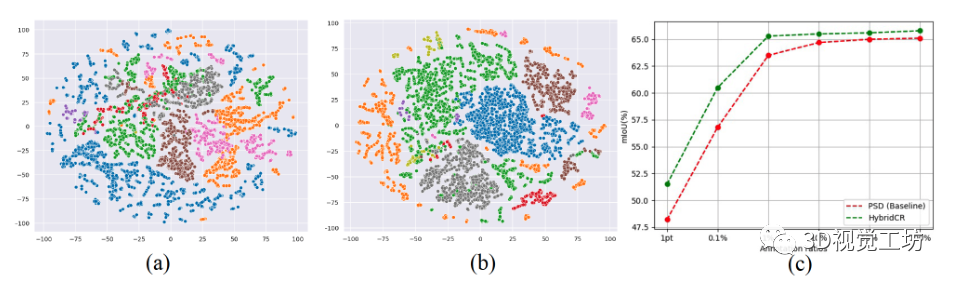 图8. 1%设置下点embedding的可视化。(a) 是PSD的embedding,(b)是HybridCR的embedding。从S3DIS的测试集中随机选择场景。(c)是标记点的数量与性能之间的关系。
图8. 1%设置下点embedding的可视化。(a) 是PSD的embedding,(b)是HybridCR的embedding。从S3DIS的测试集中随机选择场景。(c)是标记点的数量与性能之间的关系。
4.4、分析
点embedding的可视化。如图8(a)和(b)所示,与PSD相比,HybridCR学习的点embedding变得更加紧凑和分离。这表明,通过利用局部和全局引导对比损失以及动态点云增强器生成的有效变换,分割网络可以生成更多的区别特征,并产生有前景的结果。 标记点和性能。在图8(c)中,我们进一步讨论了性能与标记比率{1pt,0.1%,1%,10%,50%,100%}之间的关系。随着比率的增加,两种方法的性能都有所提高,增长趋势逐渐放缓。注意,当比率小于1%时,性能略有下降,这表明保持一定量的监督信号是必要的。此外,当比率为10%时的性能接近100%,这表明不需要密集标注来获得良好的分割结果。 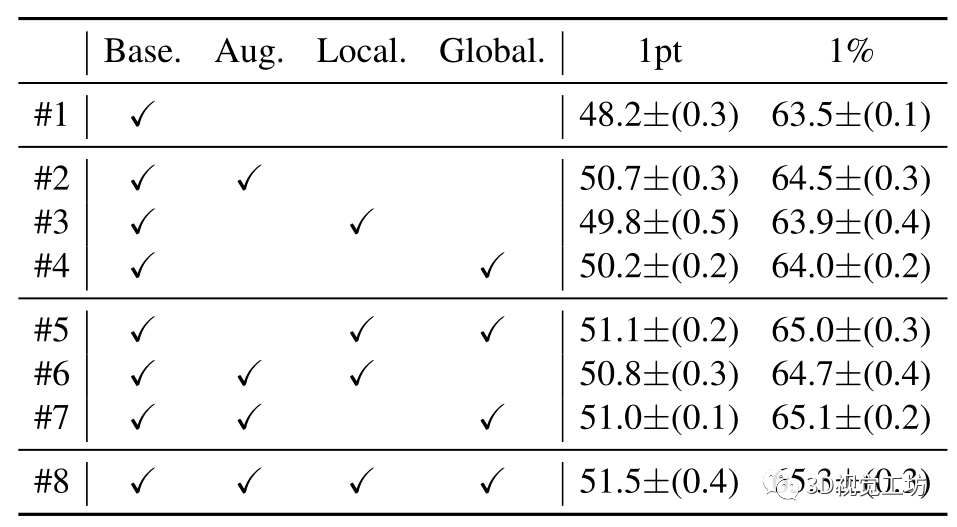 表3. S3DIS Area-5上不同组件的消融实验情况。
表3. S3DIS Area-5上不同组件的消融实验情况。
5、结论
在本文中,我们提出了一种用于弱监督大规模点云语义分割的混合对比正则化框架。利用我们提出的局部和全局引导对比正则化,网络通过利用相邻点和伪标签学习更多的鉴别特征。同时,我们提出了一种动态点云增强器,用于在训练过程中通过联合优化实现更多样的转换,从而有利于对比策略。室内和室外数据集的大量实验结果表明,和SOTA方法相比,HybridCR获得了显著的增益。此外,消融研究验证了引入的关键部件的有效性。结果进一步证明了我们的方法利用有限标记的大规模点云方面的有效性,并提高模型的泛化能力。
-
3D
+关注
关注
9文章
2990浏览量
113814 -
数据
+关注
关注
8文章
7314浏览量
93970 -
深度学习
+关注
关注
73文章
5590浏览量
123900
原文标题:HybridCR:基于混合对比正则化的弱监督3D点云语义分割(CVPR 2022)
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
一种基于机器学习的建筑物分割掩模自动正则化和多边形化方法
van-自然和医学图像的深度语义分割:网络结构
一个benchmark实现大规模数据集上的OOD检测
半监督的谱聚类图像分割


如何缩小弱监督信号与密集预测之间的差距
第一个大规模点云的自监督预训练MAE算法Voxel-MAE
普通视觉Transformer(ViT)用于语义分割的能力
点云分割相较图像分割的优势是啥?
一种在线激光雷达语义分割框架MemorySeg





 工商网监
工商网监
评论