 如何将PP-OCRv3英文识别模型部署在Corstone-300虚拟硬件平台上
如何将PP-OCRv3英文识别模型部署在Corstone-300虚拟硬件平台上

项目概述
经典的深度学习工程是从确认任务目标开始的,我们首先来简单地介绍一下 OCR 中的文本识别任务以及本期部署实战课程中我们所使用的工具和平台。
1.1 文本识别任务
文本识别是 OCR 的一个子任务,其任务为识别一个固定区域的文本内容。在 OCR 的两阶段方法里,它接在文本检测后面,将图像信息转换为文字信息。在卡证票据信息抽取与审核、制造业产品溯源、政务医疗文档电子化等行业场景中应用广泛。

1.2 PP-OCRv3
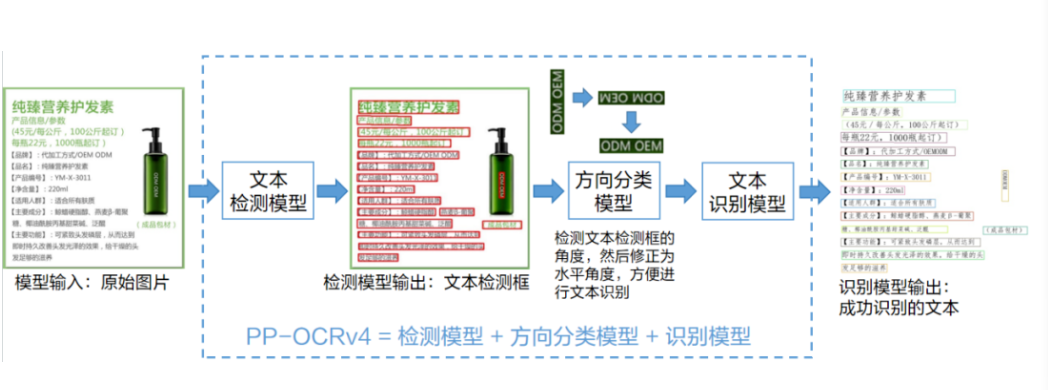
如下图所示,PP-OCRv3 的整体框架示意图与 PP-OCRv2 类似,但较 PP-OCRv2 而言,针对检测模型和识别模型进行了进一步地优化。例如:文本识别模型在 PP-OCRv2 的基础上引入 SVTR,并使用 GTC 指导训练和模型蒸馏。
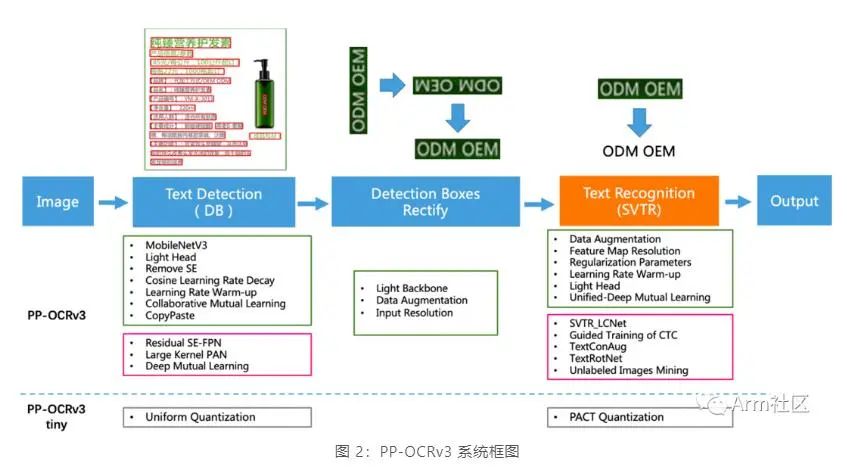
更多关于 PP-OCRv3 的特征及优化策略,可查看 PP-OCRv3 arXiv 技术报告[5]。
1.3 Arm 虚拟硬件 (Arm Virtual Hardware, AVH)
作为 Arm 物联网全面解决方案的核心技术之一,AVH 很好地解决了实体硬件所面临的难扩展、难运维等痛点。AVH 提供了简单便捷并且可扩展的途径,让 IoT 应用的开发摆脱了对实体硬件的依赖并使得云原生开发技术在嵌入式物联网、边缘侧机器学习领域得到了应用。尤其是在芯片紧张的当今时代,使用 AVH 开发者甚至可以在芯片 RTL 之前便可接触到最新的处理器 IP。
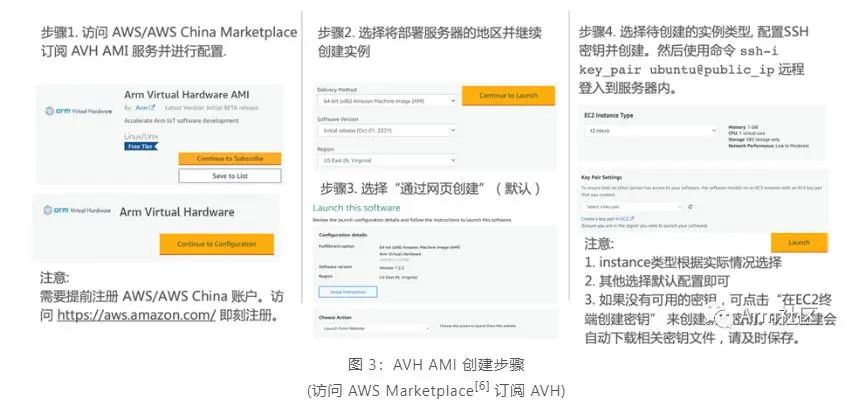
目前 AVH 提供两种形式供开发者使用。一种是托管在 AWS 以及 AWS China 上以亚马逊机器镜像 AMI 形式存在的 Arm Corstone 和 Cortex CPU 的虚拟硬件,另外一种则是由 Arm 以 SaaS 平台的形式提供的 AVH 第三方硬件。本期课程我们将使用第一种托管在 AWS 以及 AWS China 上以亚马逊机器镜像 AMI 形式存在的 Corstone 和 Cortex CPU 的虚拟硬件。
由于目前 AWS China 账号主要面向企业级开发者开放,个人开发者可访问 AWS Marketplace 订阅 AVH 相关服务。参考下图步骤创建 AVH AMI 实例。
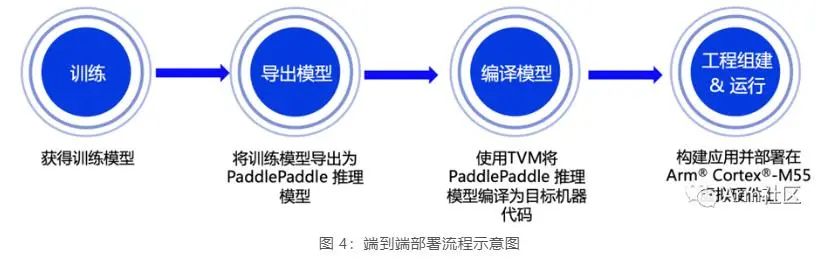
端到端部署流程
接下来小编将重点向大家展示从模型训练到部署的全流程,本期课程所涉及的相关代码已在 GitHub 仓库开源,欢迎大家下载体验!
(位于 PaddleOCR 的 dygraph 分支下 deploy 目录的 avh 文件目录中)
https://github.com/PaddlePaddle/PaddleOCR/tree/dygraph/deploy/avh
2.1 模型训练
PaddleOCR 模型使用配置文件 (.yml) 管理网络训练、评估的参数。在配置文件中,可以设置组建模型、优化器、损失函数、模型前后处理的参数,PaddleOCR 从配置文件中读取到这些参数,进而组建出完整的训练流程,完成模型训练。在需要对模型进行优化时,可以通过修改配置文件中的参数完成配置 (完整的配置文件说明可以参考文档:配置文件内容与生成[7]),使用简单且便于修改。
为实现与 Cortex-M 的适配,在模型训练时我们需要修改所使用的配置文件[8]。去掉不支持的算子,同时为优化模型,在模型调优部分使用了 BDA (Base Data Augmentation),其包含随机裁剪,随机模糊,随机噪声,图像反色等多个基础数据增强方法。相关配置文件可参考如下代码。
# Example: PP-OCRv3/en_PP-OCRv3_rec.yml Global: debug: false use_gpu: true epoch_num: 500 log_smooth_window: 20 print_batch_step: 10 save_model_dir: ./output/rec save_epoch_step: 3 eval_batch_step: [0, 2000] cal_metric_during_train: true pretrained_model: checkpoints: save_inference_dir: use_visualdl: false infer_img: doc/imgs_words/ch/word_1.jpg character_dict_path: ppocr/utils/en_dict.txt max_text_length: &max_text_length 25 infer_mode: false use_space_char: true distributed: true save_res_path: ./output/rec/predicts_ppocrv3_en.txt Optimizer: name: Adam beta1: 0.9 beta2: 0.999 lr: name: Cosine learning_rate: 0.001 warmup_epoch: 5 regularizer: name: L2 factor: 3.0e-05 Architecture: model_type: rec algorithm: SVTR Transform: Backbone: name: MobileNetV1Enhance scale: 0.5 last_conv_stride: [1, 2] last_pool_type: avg Neck: name: SequenceEncoder encoder_type: reshape Head: name: CTCHead mid_channels: 96 fc_decay: 0.00002 Loss: name: CTCLoss PostProcess: name: CTCLabelDecode Metric: name: RecMetric main_indicator: acc Train: dataset: name: LMDBDataset data_dir: MJ_ST ext_op_transform_idx: 1 transforms: - DecodeImage: img_mode: BGR channel_first: false - RecAug: - CTCLabelEncode: - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: - image - label - length loader: shuffle: true batch_size_per_card: 128 drop_last: true num_workers: 4 Eval: dataset: name: LMDBDataset data_dir: EN_eval transforms: - DecodeImage: img_mode: BGR channel_first: false - CTCLabelEncode: - RecResizeImg: image_shape: [3, 32, 320] - KeepKeys: keep_keys: - image - label - length loader: shuffle: false drop_last: false batch_size_per_card: 128 num_workers: 4
我们使用网上开源英文数据集 MJ+ST 作为训练测试数据集,并通过以下命令进行模型训练。模型训练周期与训练环境以及数据集大小等均密切相关,大家可根据自身需求进行配置。
# Example training command python3 tools/train.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global. save_model_dir=output/rec/ Train.dataset.name=LMDBDataSet Train.dataset.data_dir=MJ_ST Eval.dataset.name=LMDBDataSet Eval.dataset.data_dir=EN_eval
2.2 模型导出
模型训练完成后,还需要将训练好的文本识别模型转换为 Paddle Inference 模型,才能使用深度学习编译器 TVM 对其进行编译从而获得适配在 Cortex-M 处理器上运行的代码。可以参考以下命令导出 Paddle Inference 模型。
# Example exporting model command python3 tools/export_model.py -c configs/rec/PP-OCRv3/en_PP-OCRv3_rec.yml -o Global.pretrained_model=output/rec/best_accuracy.pdparams Global.save_inference_dir=output/rec/infer
Inference 模型导出后,可以通过以下命令使用 PaddleOCR 进行推理验证。为便于各位开发者可直接体验和部署,大家可以通过https://paddleocr.bj.bcebos.com/tvm/ocr_en.tar链接直接下载我们训练完成并导出的英文文本识别 Inference 模型。
# Example infer command python3 tools/infer/predict_rec.py --image_dir="path_to_image/word_116.png" --rec_model_dir="path_to_infer_model/ocr_en" --rec_char_dict_path="ppocr/utils/en_dict.txt" --rec_image_shape="3,32,320"
我们使用与后续部署中相同的图进行验证,如下图所示。预测结果为如下,与图片一致且具有较高的置信度评分,说明我们的推理模型已经基本准备完毕了。
Predicts of /Users/lilwu01/Desktop/word_116.png:('QBHOUSE', 0.9867456555366516)

2.3 模型编译
为实现在 Cortex-M 上直接完成 PaddlePaddle 模型的部署,我们需要借助深度学习编译器 TVM 来进行相应模型的转换和适配。TVM 是一款开源的深度学习编译器, 主要用于解决将各种深度学习框架部署到各种硬件设备上的适配性问题。
如下图所示,他可以接收由 PaddlePaddle 等经典的深度学习训练框架编写的模型并将其转换成可在目标设备上运行推理任务的代码。
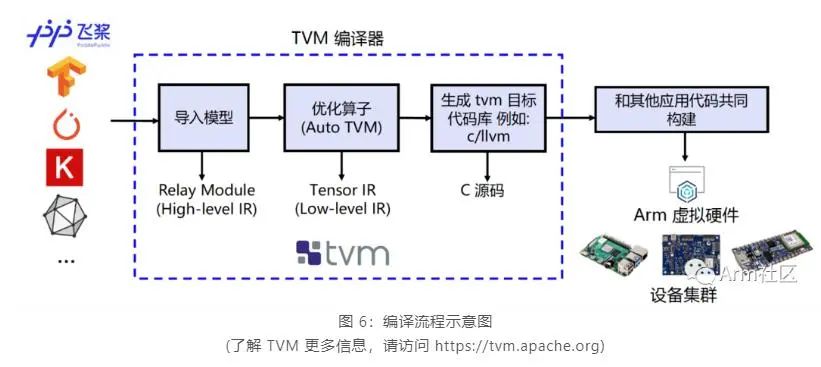
我们使用 TVM 的 Python 应用程序 tvmc 来完成模型的编译。大家可参考如下命令对 Paddle Inference 模型进行编译。通过指定 --target=cmsis-nn,c 使得模型中 CMSIS NN[9] 库支持的算子会调用 CMSIS NN 库执行,而不支持的算子则会回调到 C 代码库。
# Example of Model compiling using tvmc python3 -m tvm.driver.tvmc compile path_to_infer_model/ocr_en/inference.pdmodel --target=cmsis-nn,c --target-cmsis-nn-mcpu=cortex-m55 --target-c-mcpu=cortex-m55 --runtime=crt --executor=aot --executor-aot-interface-api=c --executor-aot-unpacked-api=1 --pass-config tir.usmp.enable=1 --pass-config tir.usmp.algorithm=hill_climb --pass-config tir.disable_storage_rewrite=1 --pass-config tir.disable_vectorize=1 --output-format=mlf --model-format=paddle --module-name=rec --input-shapes x:[1,3,32,320] --output=rec.tar
更多关于参数配置的具体说明,大家可以直接输入 tvmc compile --help 来查看。编译后的模型可以在 –output 参数指定的路径下查看 (此处为当前目录下的 rec.tar 压缩包内)。
2.4 模型部署
参考图 3 所示的 AVH AMI 实例 (instance) 创建的流程并通过 ssh 命令远程登录到实例中去,当看到如下所示的提示画面说明已经成功登入。


2.1-2.3 中所述的模型训练、导出、编译等步骤均可以选择在本地机器上完成或者在 AVH AMI 中完成,大家可根据个人需求确定。为便于开发者朋友更直观地体验如何在 AVH 上完成 PaddlePaddle 模型部署,我们为大家提供了部署的示例代码来帮助大家自动化的完成环境配置,机器学习应用构建以及在含有 Cortex-M55 的 Corstone-300 虚拟硬件上执行并获取结果。
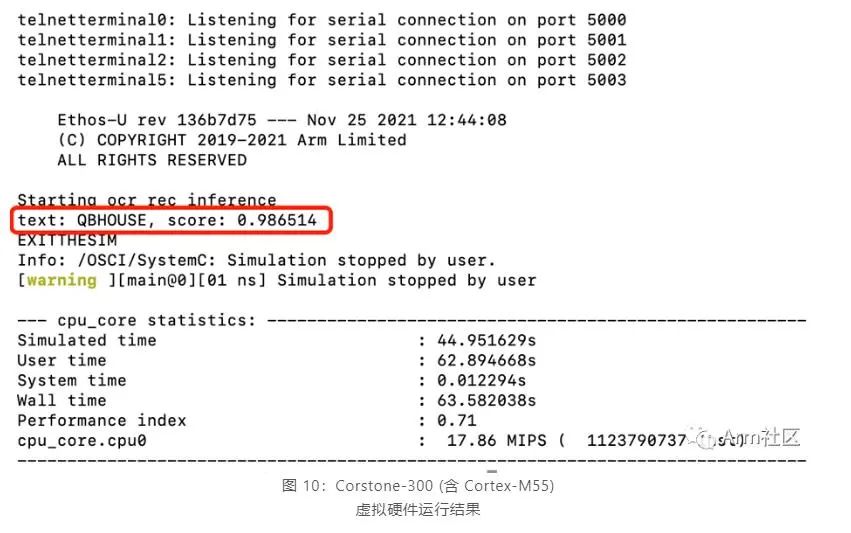
登入 AVH AMI 实例后,可以输入以下命令来完成模型部署和查看应用执行结果。run_demo.sh[11] 脚本将会执行以下 6 个步骤来自动化的完成应用构建和执行,执行结果如图 10 所示。
$ git clone https://github.com/PaddlePaddle/PaddleOCR.git $ cd PaddleOCR $ git pull origin dygraph $ cd deploy/avh $ ./run_demo.sh

不难看出,该飞桨英文识别模型在含有 Cortex-M55 处理器的 Corstone-300 虚拟硬件上的推理结果与 2.2 章节中在服务器主机上直接进行推理的推理结果高度一致,说明将 PaddlePaddle 模型直接部署在 Cortex-M55 虚拟硬件上运行良好。
总结
本期课程,小编带领大家学习了如何将 PP-OCRv3 中发布的英文识别模型 (完成算子适配后) 部署在 Corstone-300 的虚拟硬件平台上。在下期推送中,我们将以计算机视觉领域的目标检测任务 (Detection) 为目标,一步步地带领大家动手完成从模型训练优化到深度学习应用部署的整个端到端的开发流程。
-
开源
+关注
关注
3文章
4431浏览量
46606 -
硬件平台
+关注
关注
0文章
26浏览量
12206 -
识别模型
+关注
关注
0文章
5浏览量
6871
原文标题:AVH 动手实践 (二) | 在 Arm 虚拟硬件上部署 PP-OCR 模型
文章出处:【微信号:Ithingedu,微信公众号:安芯教育科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
PP-OCRv3优化策略详细解读
如何将PP-PicoDet 目标检测模型部署在Corstone-300虚拟硬件平台上
如何在Arm虚拟硬件的虚拟树莓派4上完成图像识别应用的部署
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型
使用OpenVINO C# API轻松部署飞桨PP-OCRv4模型
如何在C#中部署飞桨PP-OCRv4模型

用ROCm部署PP-StructureV3到AMD GPU上
【EASY EAI Orin Nano开发板试用体验】PP-OCRV5文字识别实例搭建与移植
介绍一种Arm ML嵌入式评估套件
如何用Arm虚拟硬件在Arm Cortex-M上部署PaddlePaddle
如何将pytorch的模型部署到c++平台上的模型流程
一键搞定!PP-OCRv5模型转ONNX格式全攻略,解锁多平台无缝部署




评论