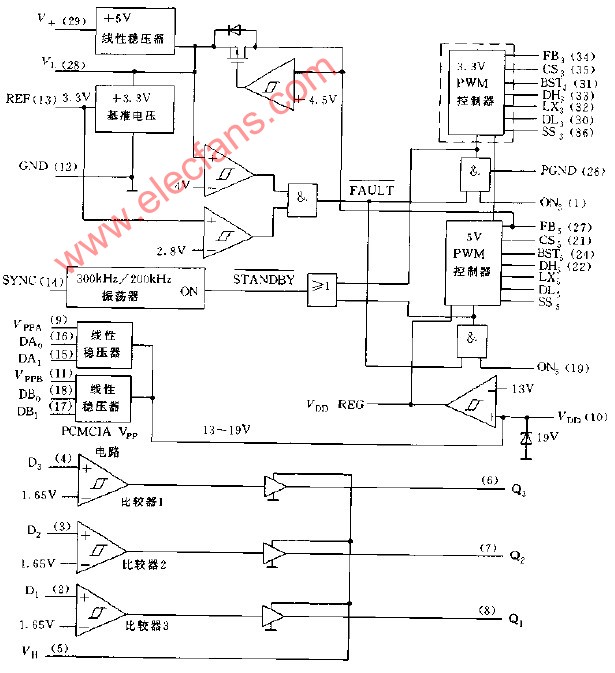
 PFN模型整体结构和分区过滤编码器内部结构
PFN模型整体结构和分区过滤编码器内部结构

01 前情提要
关系抽取目前的算法大概可以分为以下几种:
先抽实体,再判关系,比如陈丹琦大神的《A Frustratingly Easy Approach for Joint Entity and Relation Extraction 》
●Joint Entity and Realtion Extraction:
联合模型,目前我看过的有这么几种方式:
■将联合任务看做是一个填表问题,比如:table sequence,TPlinker
■将联合任务看做是一个序列标注问题,比如:ETL Span,PRGC
■将联合任务看做是一个seq2seq问题,比如:SPN4RE
这篇论文:Parition Filter Network(PFN,分区过滤网络)是一个联合模型,他们把问题定义为一个填表问题。
他们在总结之前论文的encoding层的时候,把之前的论文的encoding层分成了两类:
●sequential encoding:串行,先生成一个task的特征(一般都是NER),再生成另一个task的feature(一般就是关系抽取),而后面这个task的特征,是不会影响到前面那个task的特征的。
●parallel encoding:并行,两个task的特征是并行生成的,互不影响,只在input层面共享信息。
他们认为task间的信息没有得到很好的交互,(但其实Table sequence还是有交互的),其实现在很多算法里都在讲交互,比如NLU里面的SF-ID/Bi-Model。同时,之前也有论文(比如Table sequence和陈丹琦那篇论文)发现了关系预测和实体抽取有可能有些特征是不共享的(Table sequence为了解决这个问题,直接用了俩encoder,陈丹琦大佬那一篇直接是pipeline方法,本身就是俩模型)。而这篇论文想在一个Encoder中完成两个task的特征抽取,所以他们提出了一个分区和过滤的思路,找出“只与NER相关的特征”“只与关系预测相关的特征”和“与NER和关系预测都相关的特征”。
这里插一句,他们这篇论文效果是不错的,同时也得出了一个结论,这里提前贴一下,虽然之前有些模型论证关系抽取的特征部分是对NER有害的,但他们发现关系Signal对NER是有益的(或者说是部分有益的,因为他们做了分区)。
废话不多说了,下面介绍模型: 02 问题定义 给定一个文本,也就是一个输入序列:,其中表示下标是i的单词,L是句子的长度,目的是找到: ●找到所有的实体:,用token pairs的方式(填表),其中分别是这个实体的头和尾字,e是实体类型 ●找到所有的关系:,依然是token pairs的方式(填表),其中分别是subject的首字和object的首字,r是关系类型。 03 模型——PFN
模型主要包含两个部分:分区过滤编码器(Paritition Filter Encoder, PFE) 和 两个Task Unit (NER Unit 和 RE Unit),如下图(图中其实还有一个Global Feature,这个按照论文中的解释可以算在Encoder里面)
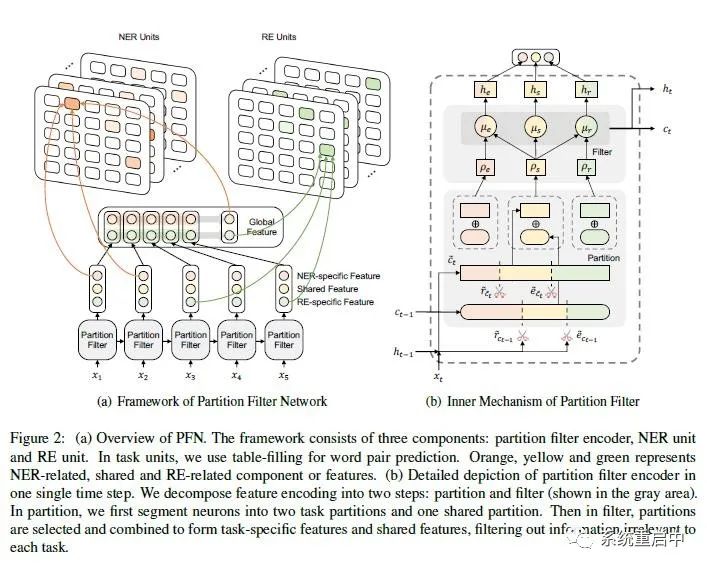
模型整体结构和分区过滤编码器内部结构 >>> 3.1分区过滤编码器(PFE)
PFE是一个循环特征编码器,类似于LSTM。在每一个time step,PFE都会把特征拆分成为三个分区:entity partition/ relation partition/ shared partition,其中entity partition是仅与实体抽取相关的分区,relation partition是仅与relation相关的分区,shared partition是与两个任务都相关的分区。然后通过合并分区, 就会过滤走与特定task无关的特征(比如合并entity partition和shared partition,就可以过滤掉特征中仅与relation相关的特征)。
上面的流程会被拆分成两个部分:
●分区(Partition) :拆分成三个分区
●过滤(Filter):合并分区
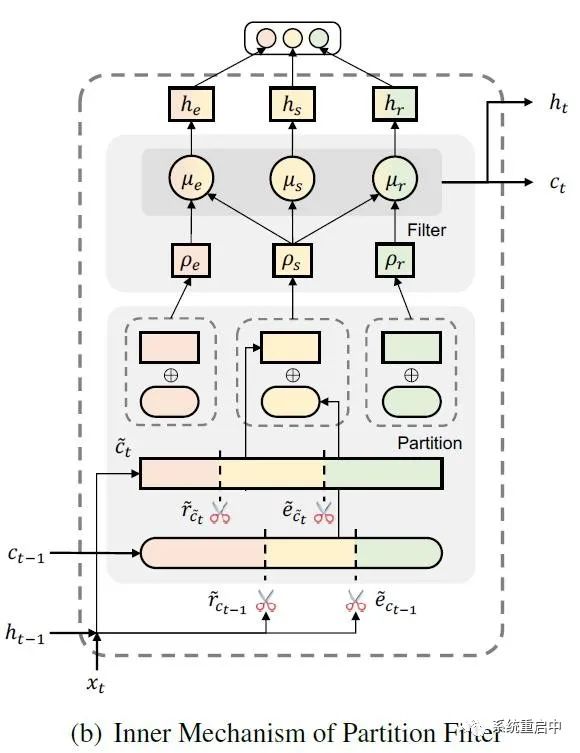
分区过滤编码器
3.1.1 分区操作
如上图所示,PFN中类似LSTM,也定义了cell state(这个是历史信息)和 hidden state ,此外还定义了candidate cell state(就是候选分区的信息),relation gate,entity gate。 每个时间步t,分区操作流程如下: 首先计算candidate cell state:
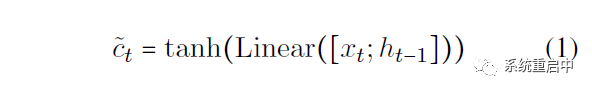
然后计算relation gate和entity gate:
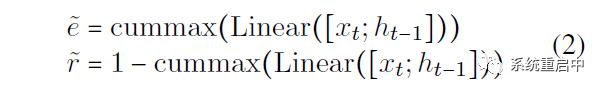
其中, 虽然这里只列了两个式子,但实际看上面的图就知道,这里的要生成两层分区,我叫他们“候选分区层”(负责对candidate cell state进行分区)和“历史分区层”(负责对 t-1 时间步的cell state进行分区),每层对应两个gate,我叫他们“候选relation gate”“候选entity gate”以及“历史relation gate”“历史entity gate”。
然后再在每层利用刚刚计算到的两个gate,生成三个分区(两层就是6个分区):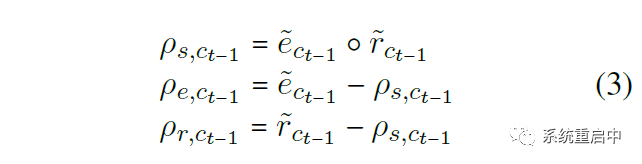
图中为t-1时间步的历史分区,用t-1时间步的历史gate生成,t时间步的候选分区一个道理 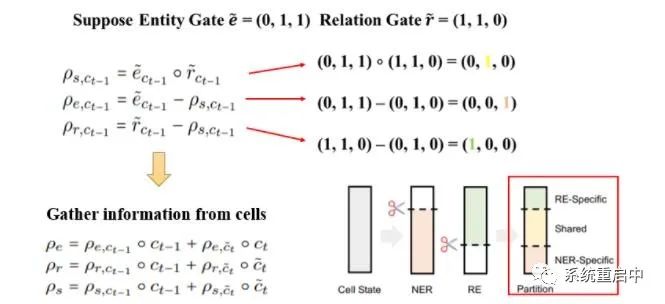 这张图可以解释一下上面这个分区,图片来自官方代码的git
这张图可以解释一下上面这个分区,图片来自官方代码的git
最后根据 t-1 时间步的 历史gate 和 历史信息cell state,和 t 时间步的 候选gate 和 候选信息candidate cell state,生成 t 时间步的三个分区的information:
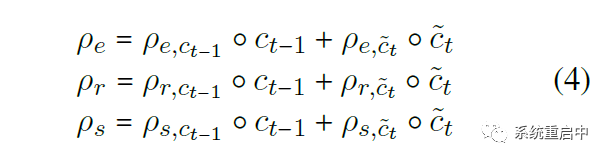
这部分看代码可能更清晰:
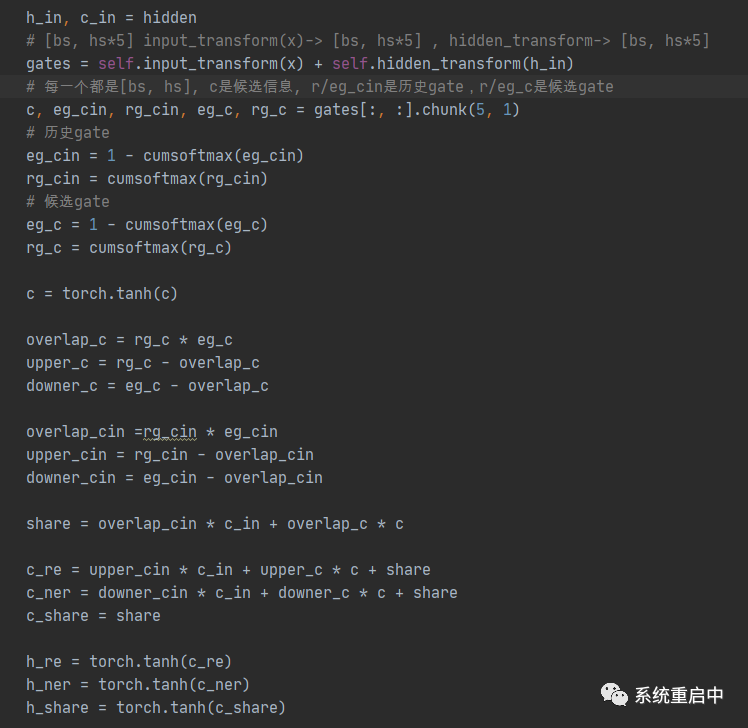 到这里,如果类比LSTM的话,cell state 和 hidden state 怎么更新,我们还不知道,同时得到三个分区信息按理说是互不重叠的。所以接下来我们让他们交互,同时看如果更新那两个state。 这里有一些问题,就是为什么有要用cummax操作,这是个什么玩意?? 这里主要是因为这篇论文在这里的gate设计上面参考了Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks中的设计。 这里我参考这篇论文简单说一下我的理解,需要对信息进行排序,切分,所以正好用一个二值gate 来描述,我们来计算这个gate。 假设我们用一个 表示g中某个位置出现第一个1的概率,看起来像是几何分布,但并不是,因为不是伯努利试验,所以算起来比较麻烦。 我们计算gate g中第k个位置是1的概率,就可以用累计分布函数: 。这样的话,我们就可以表示二值gate g每个位置为1的概率了,而因为二值gate g每个位置都是离散的,也不好用,所以就用概率来代替它,可以作为它的期望。 然后用这个概率去定义两个gate,一个单调增的cummax,一个单调减的cummax,防止冲突。
到这里,如果类比LSTM的话,cell state 和 hidden state 怎么更新,我们还不知道,同时得到三个分区信息按理说是互不重叠的。所以接下来我们让他们交互,同时看如果更新那两个state。 这里有一些问题,就是为什么有要用cummax操作,这是个什么玩意?? 这里主要是因为这篇论文在这里的gate设计上面参考了Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks中的设计。 这里我参考这篇论文简单说一下我的理解,需要对信息进行排序,切分,所以正好用一个二值gate 来描述,我们来计算这个gate。 假设我们用一个 表示g中某个位置出现第一个1的概率,看起来像是几何分布,但并不是,因为不是伯努利试验,所以算起来比较麻烦。 我们计算gate g中第k个位置是1的概率,就可以用累计分布函数: 。这样的话,我们就可以表示二值gate g每个位置为1的概率了,而因为二值gate g每个位置都是离散的,也不好用,所以就用概率来代替它,可以作为它的期望。 然后用这个概率去定义两个gate,一个单调增的cummax,一个单调减的cummax,防止冲突。
3.1.2 过滤操作
首先,根据上一步生成的三个分区的信息,交互得到生成三个memory,以达到过滤的效果:实体相关/关系相关/shared
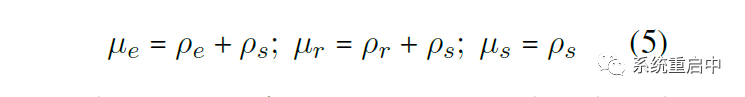
这里就达到了过滤的效果,实体部分过滤掉了仅与relation相关的,relation部分过滤掉了仅与实体相关的,shared部分包含了task间的信息,可以认为是平衡两个task 然后,三个memory分别过tanh得到相应的三个hidden state,直接从当前时间步的cell中输出,当做是 NER-specific Feature/ Relation-specific Feature/ Shared Feature,用于下一阶段的运算
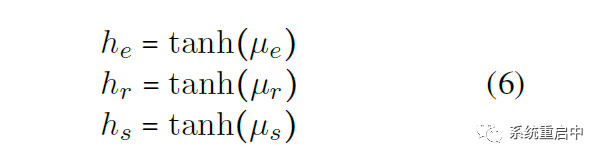
最后,更新cell state 和 hidden state,三个memory拼接在一起过线性映射得到 t 时间步的 cell state,t 时间步的 cell state 过 tanh 得到 t 时间步的 hidden state
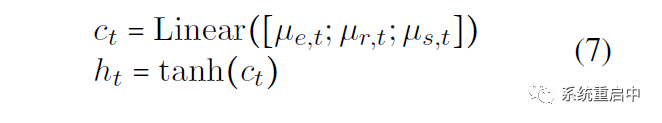
到这里,一个PFE 的 cell 就讲完了。
>>> 3.2 Global Representation
上面的 PFE Cell 其实是一个单向编码器,但一般嘛,大家都用双向的编码器,哪怕你用个BILSTM呢,也是双向的呀,本文为了代替双向编码器中的后向编码器,就提出了这个Global Representation。
具体来说就是获得两个task-specific全局的表征:分别用每个时间步的 entity-specific feature 和 relation-specific feature 拼接 shared feature,过线性映射和tanh,然后做个maxpooling over time,就获得了两个task-specific feature:
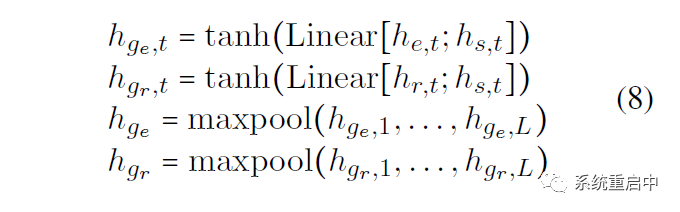
>>> 3.3Task Unit
Task Unit 包含两个Unit:entity Unit 和 Relation Unit,分别是两个填表任务
● Entity Unit
如果句子输入长度是L,那么表格的长度是L*L,表格中的(i, j)位置表示以第i个位置开始和第j个位置结束的span的Entity-Sepcific 表征,这个表征的为拼接:第i个位置和第j个的entity-specific feature,以及entity-specific global representation,过Linear以及ELU激活函数
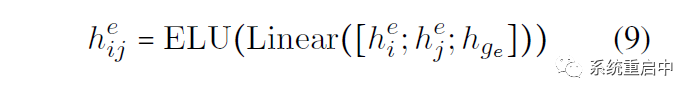
接下来就是输出层:就是一个线性映射,映射到entity type数目的维数上,然后每维做sigmoid,判断是不是其代表的entity type(之所以采用这种多标签分类的方式,是为了解决overlapping问题)
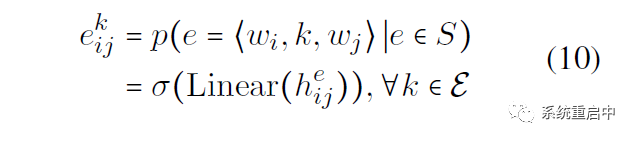
● Relation Unit
如果一个句子长度是L,那么表格长度是L*L,表格中的 (i, j) 位置标示以第i个位置为首字的span,和以第j个位置为首字的span的 关系表征,这个表征的和Entity Unit差不多,拼接:第i个位置和第j个的relation-specific feature,以及relation-specific global representation,过Linear以及ELU激活函数
然后一样做多标签分类
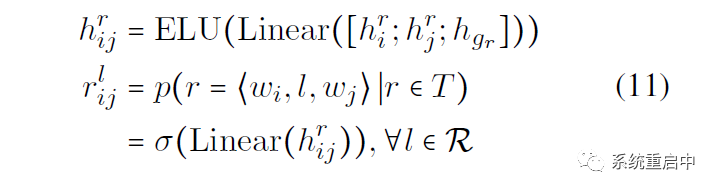
>>> 3.4 训练和推断
●损失函数:两个BCE

●推断的时候有两个超参数阈值:实体阈值和关系阈值,都设置为0.5
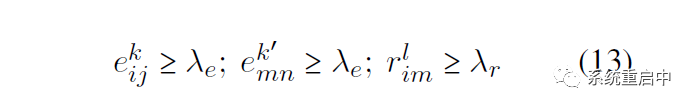
04 实验 >>> 4.1 主要结果
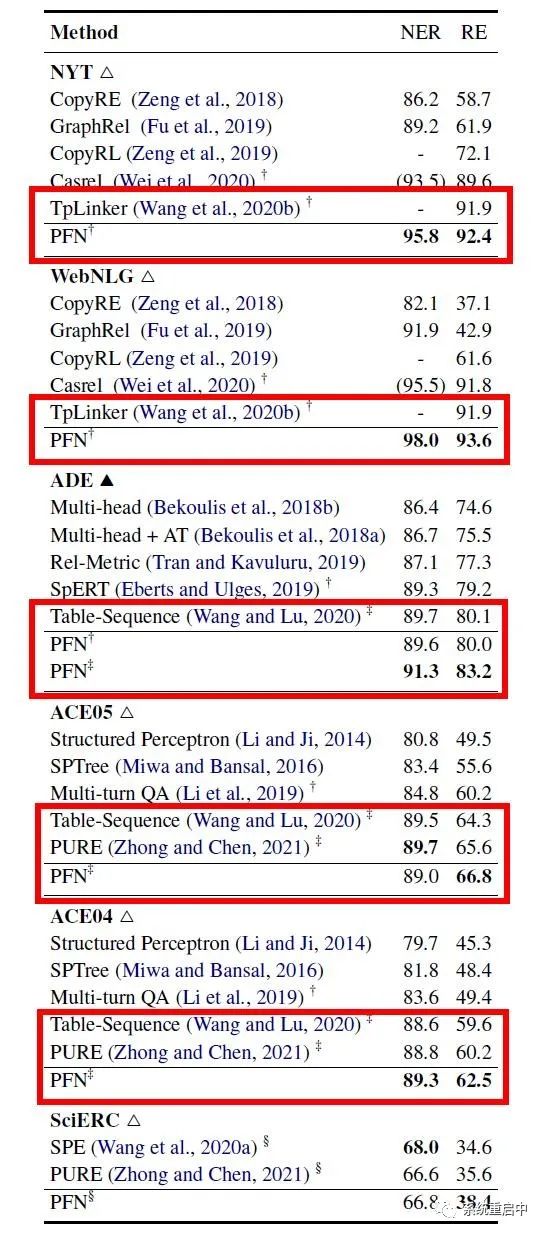

可以看到,在使用同样的预训练模型的情况下,效果是要比TPLiner和Table Sequence要好的(Table Sequence是有一些交互的哟),同时这篇论文在WebNLG上的结果也比同时EMNLP2021论文的PRGC要好一点点(PFN-93.6, PRGC-93.0, TPLinker-91.9) >>> 4.2 消融实验
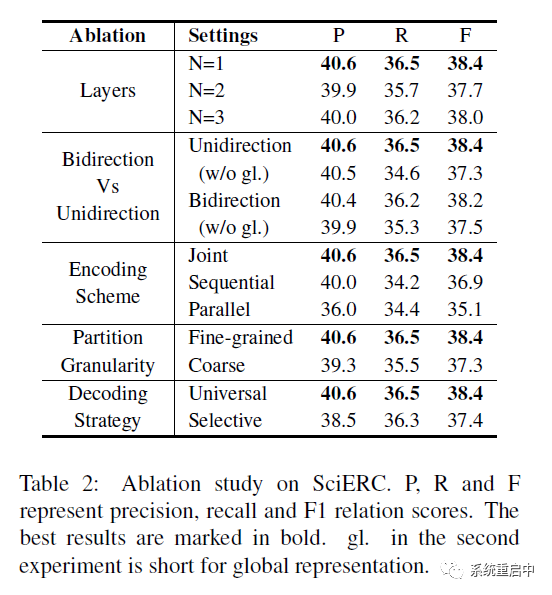
他们的消融实验主要进行了如下几个:
●编码器的层数实验:1层效果就很好 ●双向编码器Vs单向编码器:主要是为了证明他们的Global Representation的作用,结果发现效果真不戳,在他们的这一套里面,全局表征完全可以代替后向编码器,甚至效果更好 ■前向+G>双向+G>双向>单向 ●编码器的结果:他们换成了两个LSTM,发现他们的效果好 ■对于并行模式:entity 和 relation 分别过一个LSTM,只在input级别共享 ■对于串行模式:先过第一个LSTM,hidden state 用于entity预测,同时 hidden state会被送到第二层LSTM中去,结果用于预测relation ●分区粒度:这个我觉得实验设置一定是他们的好,没必要单拎出来讲 ●解码策略:两种,一种是relation只考虑entity prediction 结果的(解码时级联,relation不考虑所有单词,仅考虑candidate set),一种是他们这种两张表都填的(relation考虑所有单词) ■他们发现后者效果更好,原因可能有二:a. 前一种有误差传递;b. 第二种表中的负例多,有点对比学习的意思,因此学到的正例的表征更牛逼。
>>> 4.3 关系抽取的signal对NER的影响
之所以做这个实验,是因为之前有论文认为关系抽取的特征对NER在Joint模型中是有害的,因为两者需要的特征不同。他们只是部分同意这个观点,也就是说,关系抽取的特征部分是对NER有害的,但也有一部分对NER有益的,他们这篇论文其实就是识别出来哪部分有益,哪部分有害,并对有益部分加以利用。
4.3.1 关系内和关系外的实体抽取的差别
在主要实验中,ACE05里面他们的NER效果拉垮了,他们认为是关系外的实体很多,统计了一下有64%的实体都是关系外实体。
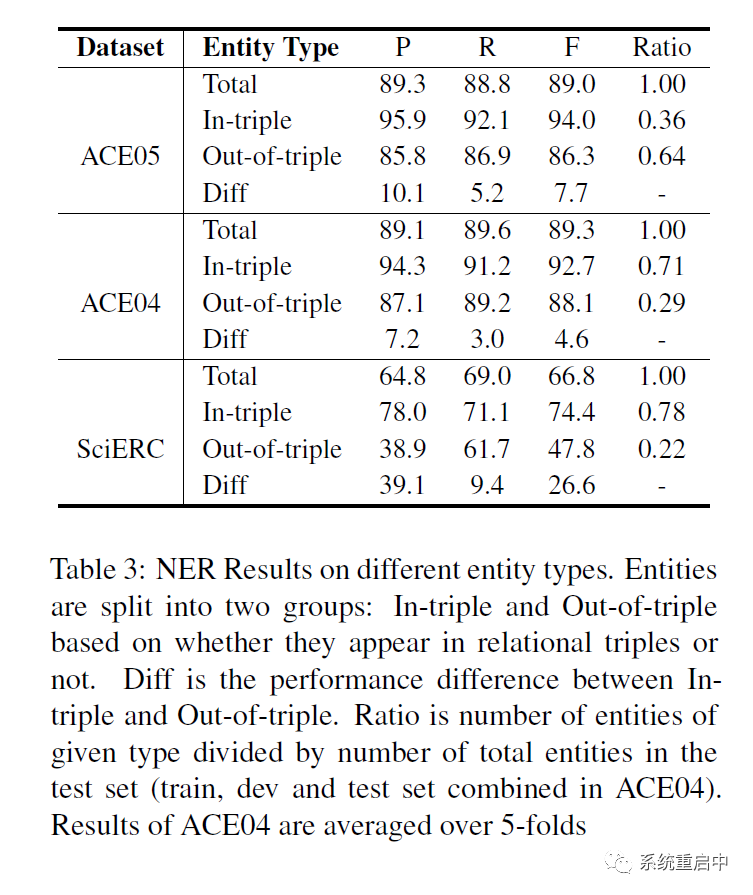
他们做了三个数据集上面的,关系内的实体识别效果F1都要好于关系外的。(SciERC中gap超大,因为SciERC中的实体专业程度更强,也更长,有关系效果更好),此外,precision的gap尤其大,证明失去了relation信息的,模型在entity上就会过拟合。
同时看到:关系外实体的占比 与 NER的效果是负相关的。这有可能是因为joint model的一个缺点:考虑到关系内和关系外的实体的推断逻辑是不一样的(一个有relation影响,一个没有),那么joint model有可能对关系外的NER的效果是有害的。
但我这里弱弱的问一句,这是不是说对于类外实体,如果gate可以做的更好,就可以效果依然棒呢,其他两个比它好的论文里面(Table Sequence也是交互的啊,PURE我还没看,回头看看)。
4.3.2 NER鲁棒性分析
他们与纯NER算法做对比,进行了鲁棒性的分析,发现他们的NER的鲁棒性还是不错的,可能的原因就是relation signals对实体进行了约束,从而让鲁棒性更强。
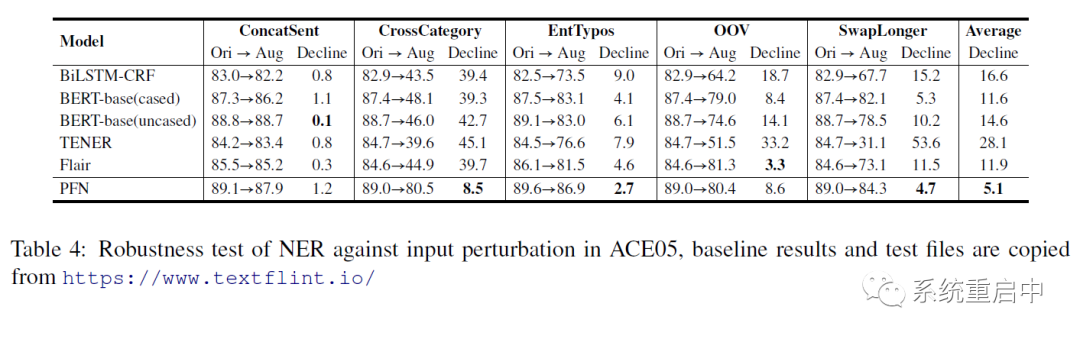
所以通过上面两部分,他们认为关系信息对NER效果是有帮助的。此外,提一嘴,他们反驳了陈丹琦大佬论文《A Frustratingly Easy Approach for Joint Entity and Relation Extraction》关于关系信息对NER的帮助比较小的结论,认为那篇论文是在ACE2005上面做的实验,类外实体太多了,所以效果不明显。
-
编码器
+关注
关注
45文章
4011浏览量
143368 -
模型
+关注
关注
1文章
3818浏览量
52269 -
代码
+关注
关注
30文章
4976浏览量
74384
原文标题:复旦提出PFN: 关系抽取SOTA之分区过滤网络
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
[转帖]光耦内部结构原理
变频器内部结构_变频器内部结构图
基于双编码器网络结构的CGAtten-GRU模型


磁性编码器结构及原理




评论