 表示学习中7大损失函数的发展历程及设计思路
表示学习中7大损失函数的发展历程及设计思路

表示学习的目的是将原始数据转换成更好的表达,以提升下游任务的效果。在表示学习中,损失函数的设计一直是被研究的热点。损失指导着整个表示学习的过程,直接决定了表示学习的效果。这篇文章总结了表示学习中的7大损失函数的发展历程,以及它们演进过程中的设计思路,主要包括contrastive loss、triplet loss、n-pair loss、infoNce loss、focal loss、GHM loss、circle loss。
1. Contrastive Loss
Dimensionality Reduction by Learning an Invariant Mapping(CVPR 2006)提出contrastive loss,模型中输入两个样本,经过相同的编码器得到两个样本的编码。如果两个样本属于同一类别,则优化目标为让两个样本在某个空间内的距离小;如果两个样本不属于同一类别,并且两个样本之间的距离小于一个超参数m,则优化目标为让两个样本距离接近m。损失函数可以表示为:
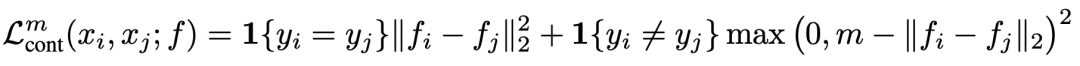
Contrastive Loss是后面很多表示学习损失函数的基础,通过这种对比的方式,让模型生成的表示满足相似样本距离近,不同样本距离远的条件,实现更高质量的表示生成。
2. Triplet Loss
FaceNet: A unified embedding for face recognition and clustering(CVPR 2015)提出triplet loss,计算triplet loss需要比较3个样本,这3个样本分别为anchor、position和negtive。其目标为让anchor和positive样本(类别相同)的距离尽可能近,而和negtive样本(类别不同)的距离尽可能远。因此triplet loss设计为,让anchor和positive样本之间的距离比anchor和negtive样本要小,并且要小至少一个margin的距离才不计入loss。
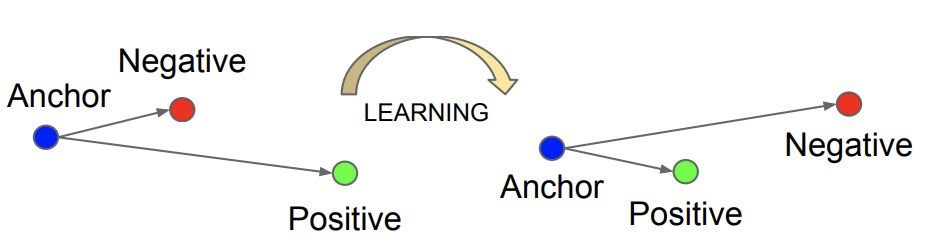
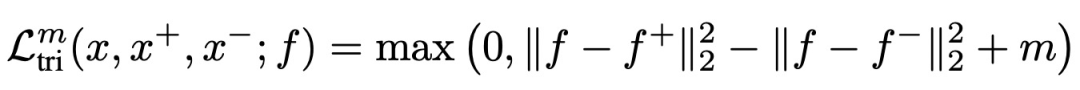
3. N-pair Loss
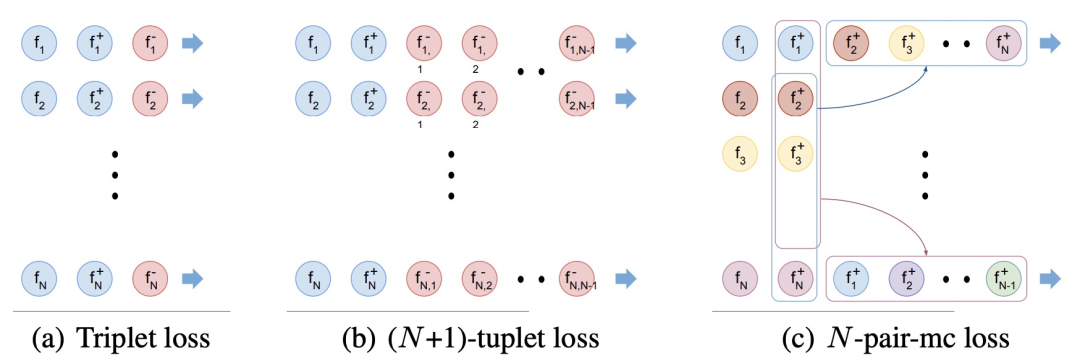
Improved Deep Metric Learning with Multi-class N-pair Loss Objective(NIPS 2016)提出N-pairLoss。在之前提出的contrastive loss和triplet loss中,每次更新只会使用一个负样本,而无法见到多种其他类型负样本信息,因此模型优化过程只会保证当前样本的embedding和被采样的负样本距离远,无法保证和所有类型的负样本都远,会影响模型收敛速度和效果。即使多轮更新,但是这种情况仍然会导致每轮更新的不稳定性,导致学习过程持续震荡。
为了解决这个问题,让模型在每轮更新中见到更多的负样本,本文提出了N-pair loss,主要改进是每次更新的时候会使用多个负样本的信息。N-pair loss可以看成是一种triplet loss的扩展,两个的关系如下图,当我们有1个正样本和N-1个负样本时,N-pair loss的计算方式:
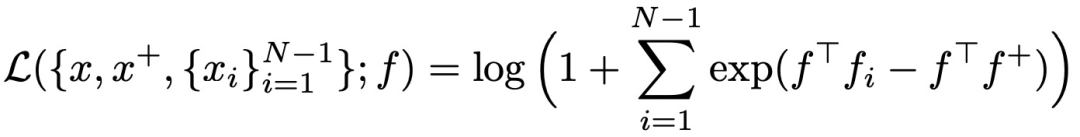
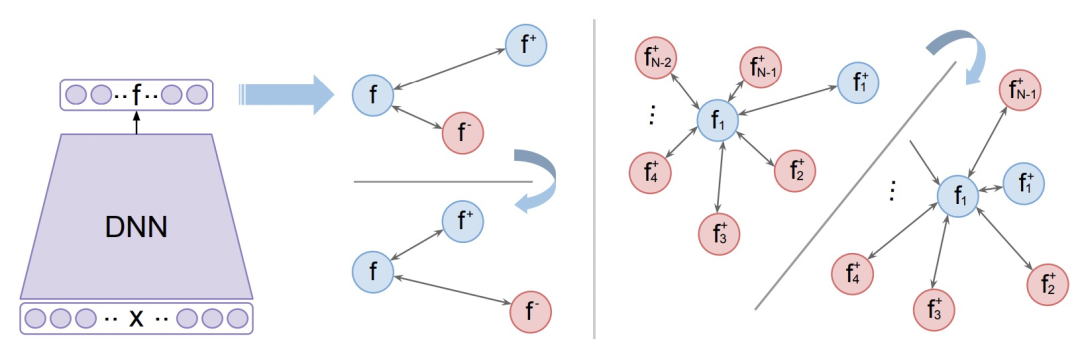
扩大负样本数量的问题在于,原来每个batch内只需要计算N*3个样本,现在需要计算N*(N+1)个样本,运算量大幅度提高,难以实现。为了解决这个问题,文中提出将一个batch内不同样本的负样本数据共享,这样只需要计算3*N个样本的embedding即可,实现了效率提升。
4. InfoNceLoss
Representation learning with contrastive predictive coding(2018)提出infoNce loss,是对比学习中最常用的loss之一,它和softmax的形式很相似,主要目标是给定一个query,以及k个样本,k个样本中有一个是和query匹配的正样本,其他都是负样本。当query和正样本相似,并且和其他样本都不相似时,loss更小。InfoNCE loss可以表示为如下形式,其中r代表temperature,采用内积的形式度量两个样本生成向量的距离,InfoNCE loss也是近两年比较火的对比学习中最常用的损失函数之一:
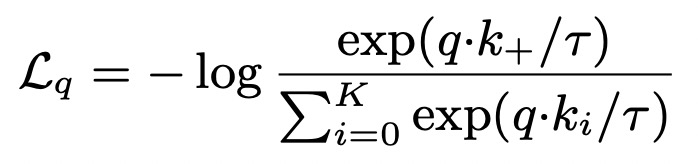
相比softmax,InfoNCE loss使用了temperature参数,以此将样本的差距拉大,提升模型的收敛速度。
5. Focal Loss
Focal Loss for Dense Object Detection(2018)提出Focal Loss,最开始主要是为了解决目标检测中的问题,但是在很多其他领域也可以适用。Focal Loss解决的核心问题是,当数据中有很多容易学习的样本和较少的难学习样本时,如何调和难易样本的权重。如果数据中容易的样本很多,难的样本很少,容易的样本就会对主导整体loss,对难样本区分能力弱。
为了解决这个问题,Focal Loss根据模型对每个样本的打分结果给该样本的loss设置一个权重,减小容易学的样本(即模型打分置信的样本)的loss权重。在交叉熵的基础上,公式可以表示如下:
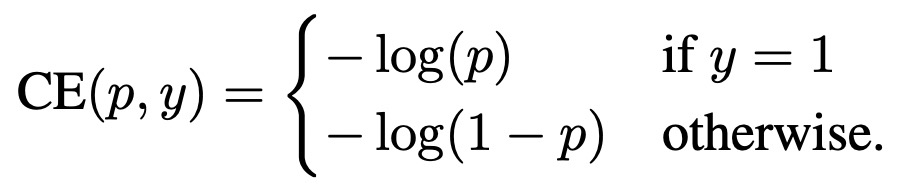
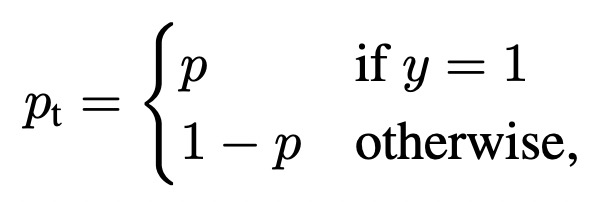
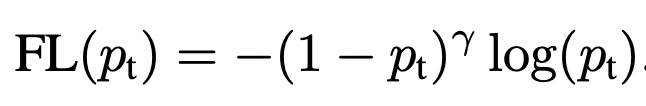
其中pt表示,当label为1时模型的预测值,当label为0时1-模型的预测值。通过对这个loss公式的分析可以看出,对于label为1的样本,且模型预测值接近1,这个时候该样本分类正确且容易预测,则第一项权重接近0,显著减小了这种易分类样本的loss权重。当label为0,模型预测值接近1时,属于预测错误,loss的权重也是接近1的,对该样本的loss基本没有影响。
6. GHM Loss
在Focal Loss中强制让模型关注难分类的样本,但是数据中可能也存在一些异常点,过度关注这些难分类样本,反而会让模型效果变差。Gradient Harmonized Single-stage Detector(AAAI 2019)提出了GHM Loss,
首先分析了一个收敛的目标检测模型中,所有样本梯度模长的分布情况。梯度模长衡量了一个样本对模型梯度的影响大小(不考虑方向),反映了一个样本的难以程度,g越大模型因为此样本需要更新的梯度越大,预测难度越大。基于交叉熵和模型输出,梯度模长g定义如下:
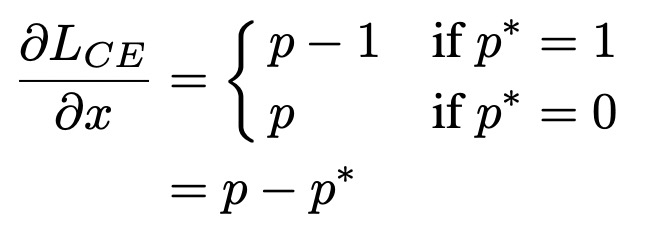
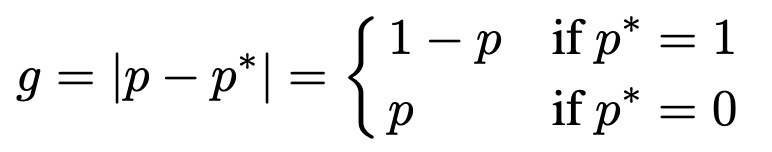
一个收敛的目标检测模型的梯度模长分布如下,简单样本(即g很小的样本)占绝大多数,这部分样本是我们希望减小其loss权重的;同时还有很多难样本,它们的g非常大,这部分可以被视作异常点,因为它们的梯度不符合大多数样本,对于这部分极难样本也应该减小权重。
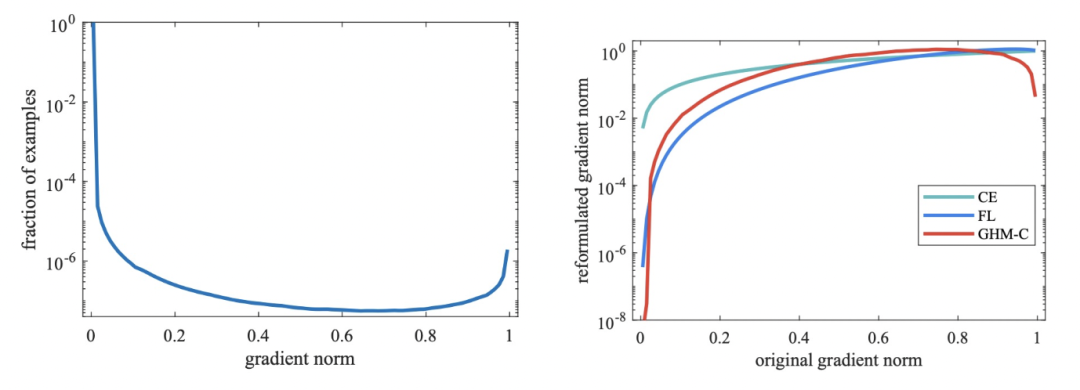
为了同时减小易学习样本和异常点样本的权重,文中引入了梯度密度的概念(GD),衡量单位梯度模长的样本密度。这个梯度密度用来作为交叉熵loss中的样本权重,公式如下:
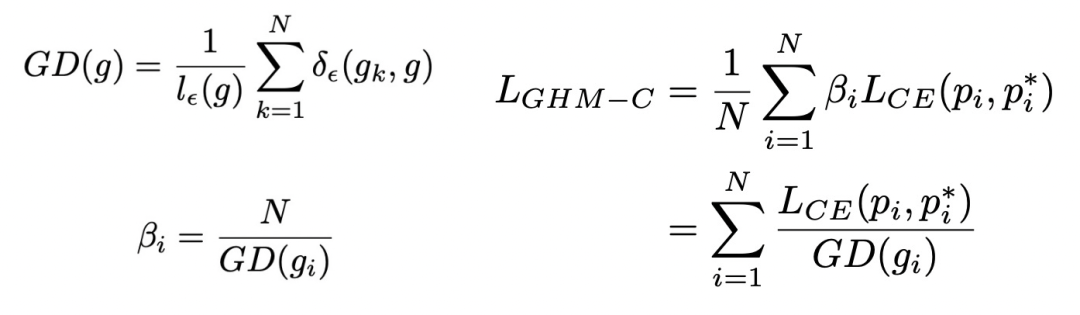
上面右侧的图对比了各种loss对不同梯度模长样本的影响情况,可以看到GHM对于简单样本和困难样本都进行了一定的loss抑制,而Focal Loss只能对简单样本进行loss抑制,普通loss对这两类样本都没有抑制作用。
7. Circle Loss
Circle Loss: A Unified Perspective of Pair Similarity Optimization(CVPR 2020)提出circle loss,从一个统一的视角融合了class-level loss和pair-wise loss。这两种优化目标,其实都是在最小化sn-sp,其中sn表示between-class similarity,即不同类别的样本表示距离应该尽可能大;sp表示within-class similarity,即相同类别的样本表示距离尽可能小。因此,两种类型的loss都可以写成如下统一形式:
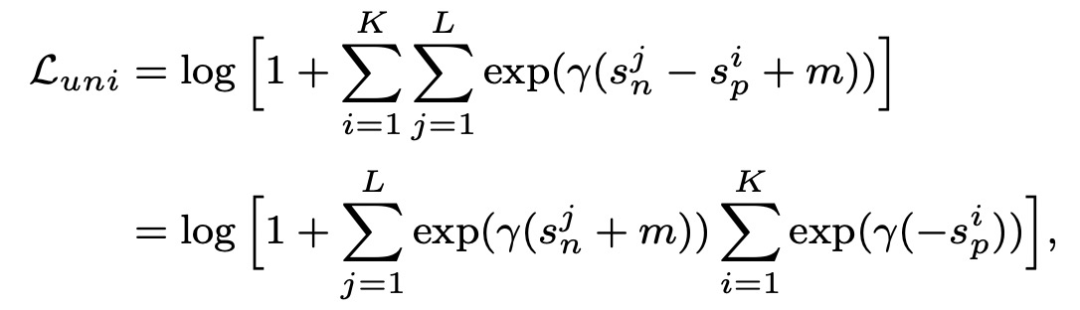
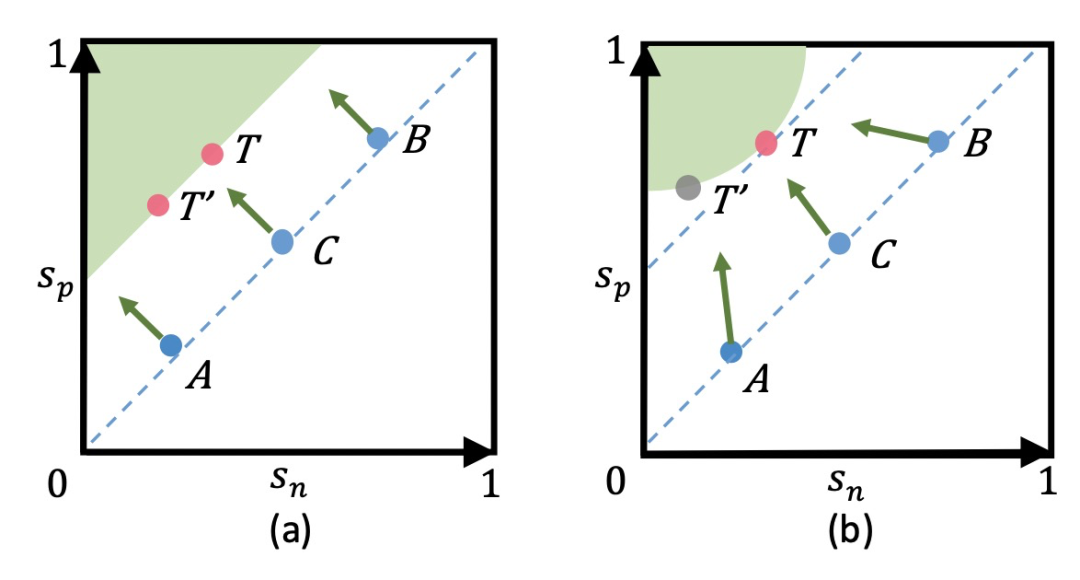
基于sn-sp这种loss存在的问题是,优化过程中对sn和sp的惩罚力度是一样的。例如下面左图中,A点的sn已经很小了,满足要求了,而sp还不够大,sn-sp这种优化方法让sn和sp的更新幅度相同。而更好的方法是多更新一些sp,少更新一些sn。此外,这种loss在优化过程中也会导致模棱两可的情况,导致收敛状态不明确。例如T和T'这两个点,都满足给定margin的情况下的优化目标,但却存在不同的优化点。
为了解决这个问题,circle loss在sn和sp分别增加了权重,用来动态确定sn和sp更新的力度,实现sn和sp以不同步调学习,circle loss的公式如下。当sn或sp相似度结果距离各自的最优点较远时,会以一个更大的权重进行更新。同时,在这种情况下loss不再是对称的,需要对sn和sp分别引入各自的margin。
8. 总结
损失函数是影响表示学习效果的关键因素之一,本文介绍了表示学习中7大损失函数的发展历程,核心思路都是通过对比的方式约束模型生成的表示满足相似样本距离近,不同样本距离远的原则。 审核编辑:郭婷
-
编码器
+关注
关注
45文章
4011浏览量
143368
原文标题:表示学习中的7大损失函数梳理
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ASPICE 的起源与发展历程(二)
【「芯片设计基石——EDA产业全景与未来展望」阅读体验】--EDA了解与发展概况
C语言回调函数原来这么简单
激活函数ReLU的理解与总结
新思科技在中国30周年的发展历程回顾
移动机器人技术的发展历程
晶体管的基本结构和发展历程
【精选直播】无感FOC控制中滑模观测器估算转子角度思路分享

宝马集团车载总线技术的发展历程
FPGA在机器学习中的具体应用
鸿蒙发展历程
智能氮气柜的发展历程和前景展望




评论