 双塔模型扩量负样本的方法比较
双塔模型扩量负样本的方法比较

之前有一段时间做过双塔的召回模型[1],线上各个指标有了不错的提升。目前双塔模型也是被各大公司钟爱的召回模型。对主流召回模型的分享整理在:总结下自己做过的深度召回模型
双塔模型在训练时是对一个batch内样本训练。一个batch内每个样本 (user和item对)为正样本,该user与batch内其它item为负样本。这样训练的方式可能有以下问题:
负样本的个数不足。训练时负样本个数限制在了batch内样本数减1,而线上serving时需要在所有候选集中召回用户感兴趣的样本。模型只能从当前batch内区分出batch内正样本,无法很好地从所有候选集中区分正样本。
未点击的item没有做负样本。由于batch内的item都是被点击过的,因此没有被点击item无法成为负样本,在线上serving容易它们被召回出来。一种解决方法是之前没被点击过的item不导出到候选集中,然而这样存在的问题是召回的item很多是之前点击的热门item,而很多冷门的item没有机会召回。
最近,有两篇文章提出了双塔模型扩量负样本的方法。这两种方法我也曾尝试过,线下线上指标也有一定的提升。
一、Two Tower Model
再介绍其它方法之前,先回顾一下经典的双塔模型建模过程。
用 表示双塔模型计算的user 和item 的相似性:
是表示user塔,输出user表示向量; 是item,输出item表示向量。最后相似性是两个向量的余弦值。batch内概率计算公式为:表示一个batch的意思。损失函数是交叉熵。
作者在计算user和item的相似度时,用了两个优化方法:
。 可以扩大相似度范围,扩大差距。
。 是item 在随机样本中被采样的概率,也就是被点击的概率。
关于优化2的解释有很多。论文中说热门item出现在batch内概率较大,因此会被大量做负样本。另一种解释是增加对冷门item的相似度。相比热门item,冷门item更能反映用户兴趣。
图1反映了双塔模型的batch采样过程。query也可以表示user。我们采样一个batch的user和对应正样本的item,计算各自的embedding后,通过点乘得到logits(B*B)的矩阵。label矩阵是一个单位矩阵。logit矩阵与label矩阵的每对行向量一起求交叉熵。
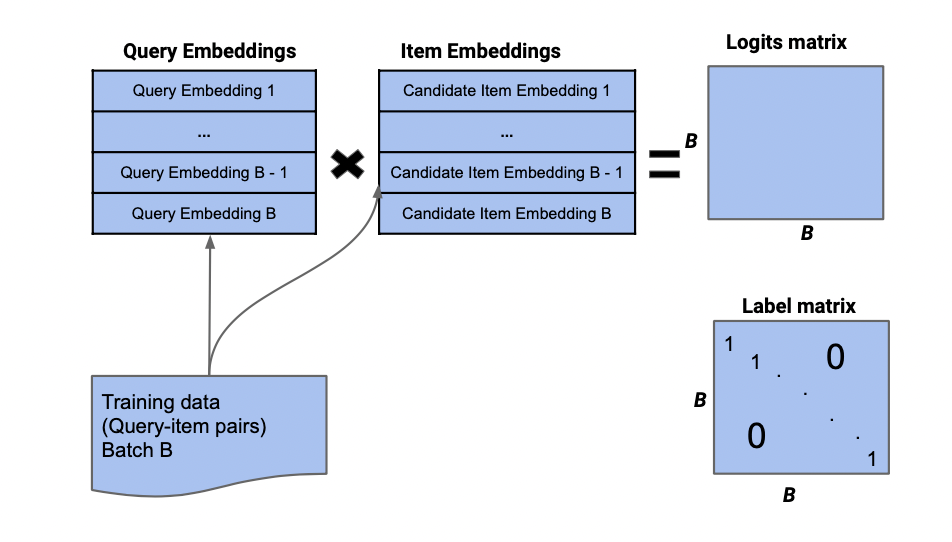
图1:双塔模型batch采样
二、Mixed Negative Samping(MNS)
MNS[2]与双塔模型[1]出自谷歌团队的同一批作者。用一个batch数据训练时,MNS还会在所有的数据集中采样出 个item。这样可以让所有的item参与到训练中,一些曝光未点击的item也会当作负样本。同时,双塔模型中使用的 等于训练样本中的频率加上所有数据集中的频率分布。概率公式重新定义如下:
作者在这里只对负样本的相似性减去了频率的log值。
MNS的batch采样方法见图2。最终计算的logits和label矩阵是一个B*(B+B')维的。其实就是在图1展示的基础上再增加B'列。logits的最后B'列是user与B‘内的item计算的相似性,label的最后B'列是全0矩阵。
相比于每个样本都随机采样出一定量的负样本,为每个batch都采样出B‘个负样本的不仅有先前双塔模型的计算效率,也缓和负样本不足的问题,并且让每个样本均有机会做负样本。
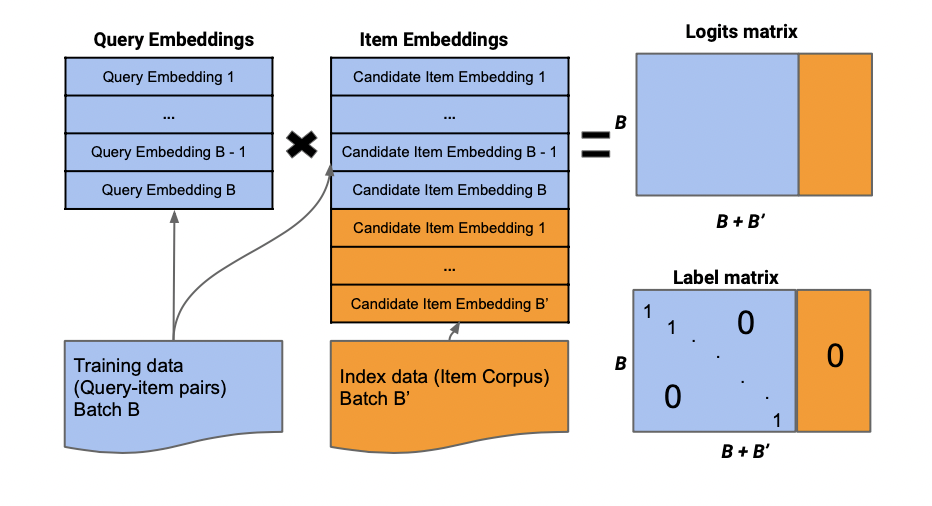
图2:MNS的batch采样
三、Cross Batch Negative Samping(CBNS)
CBNS[2]是清华大学和华为合作提出的方法。文中提到,双塔模型的计算优势在于利用了batch内的负样本,减小的计算量。如果我们想扩大batch内样本个数,加大负样本个数,需要很多的内存。因此,作者提出一个使用之前训练过的item作为负样本的方法。
神经网络训练达到一定轮数后,会对相同的样本产生稳定的向量。作者在论文中定义了这个想法。因此把之前训练过的item作为当前训练的负样本时,模型只需要把这些item的向量拿过来使用,不需要再输出到神经网络中产生新的向量,毕竟这两种向量的差距较小。
作者使用了FIFO(先进先出)队列,item塔输出向量时,会放进FIFO中。当warm-up training达到一定的轮数后,训练模型时,会从FIFO拿出一批向量作为负样本的向量。这样做不仅减少了计算量,在扩充负样本的时候也减少了内存的使用。计算公式与MNS差别不大:
也就是内容一中的优化2。B'在这里是从FIFO中取出的一批向量。
图3展示了CBNS与只用batch内负样本的不同。CBNS维持了一个memory bank。在训练时,会从里面拿出一定量的向量。
然而,CBNS的负样本只有点击过的样本,未点击的样本无法作为负样本。
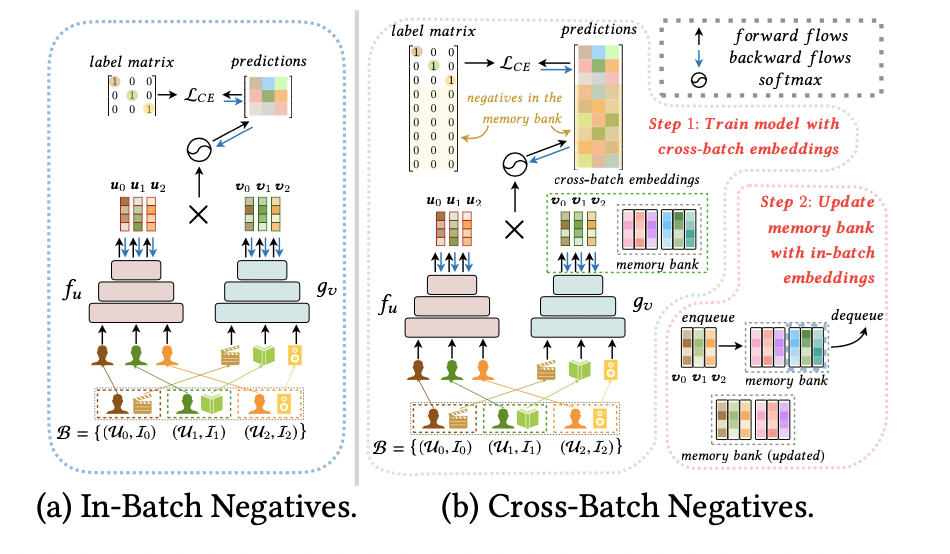
图3:CBNS采样方法
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4842浏览量
108185 -
fifo
+关注
关注
3文章
407浏览量
45907
原文标题:双塔模型如何选择负样本?
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
航空发动机滑油箱负过载腔隔板溢流通道内油液输运行为及对供油能力贡献度量化分析

海光DCU完成Qwen3.5多模态MoE模型全量适配
新一代单目标 AI 跟踪算法,解决典型困难场景下的跟踪稳定性问题

大模型 ai coding 比较
模板驱动 无需训练数据 SmartDP解决小样本AI算法模型开发难题

大模型推理显存和计算量估计方法研究
提高SEA模型PBNR计算精度的方法及策略

碳化硅衬底切割进给量与磨粒磨损状态的协同调控模型



评论