 AMD处理器和加速器全面助力人工智能 (AI) 训练与高性能计算
AMD处理器和加速器全面助力人工智能 (AI) 训练与高性能计算

根据世界经济论坛2022年《全球风险报告》显示,“气候行动失败”是未来5-10年内全球最主要的长期风险之一。这不仅是未来的挑战,而且相关问题已经显现。作为微处理器设计厂商,在技术飞速发展的今天,我们有责任保护地球,也有机会帮助大家节约能源和减少温室气体排放。
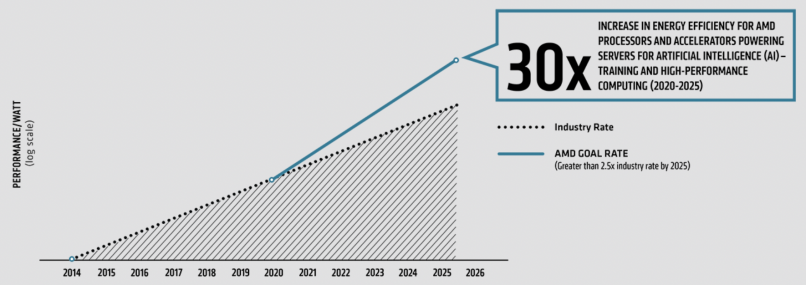
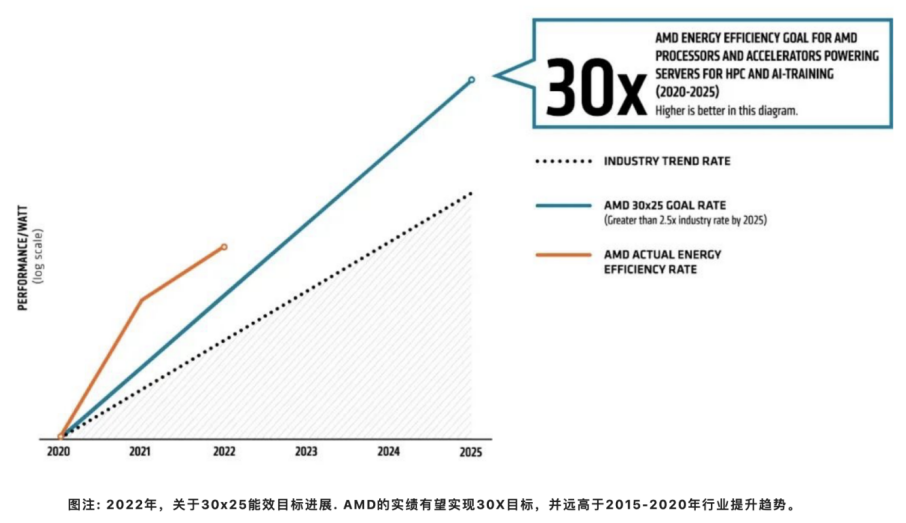
AMD面向未来绘制了更加宏伟的蓝图,在25x20能效计划实施的基础上,制定了一项新的能效目标——30x25目标。从2020年到2025年,将AMD 处理器和加速器的能效提高 30 倍,全面助力人工智能 (AI) 训练与高性能计算。我们的目标相当于到 2025 年将计算的能耗减少97%。如果全球所有的人工智能和高性能计算服务器节点都能实现相似的提升,相对于行业基准趋势,从2021年到2025 年,最多可节省510亿千瓦时的电力,相当于62 亿美元的节电量和 6 亿棵生长 10 年的树木的碳减排量。
AMD EPYC(霄龙)处理器和AMD Instinct 加速器
AMD EPYC(霄龙) 7003系列产品是性能出类拔萃的x86服务器处理器,其不仅能带来出色的性能,而且能够充分降低数据中心运营对环境的影响,进一步降低能源成本,同时推动实现公司的可持续发展目标。
经过全新设计的AMD Instinct 加速器,可以轻松应对高性能计算和人工智能工作负载,无论是单服务器解决方案,还是世界先进的超级计算机,AMD Instinct 系列加速器可为各种规模的数据中心带来卓越性能。全新的AMD Instinct 加速器采用创新性 AMD CDNA 2 架构、AMD Infinity Fabric 技术以及先进的封装技术,助力百亿亿级计算系统加速探索发现,让科学家能够轻松应对各种紧迫的挑战。
基于AMD EPYC(霄龙)CPU和AMD Instinct加速器,AMD可以为AI训练和HPC应用程序中那些世界上增长最快的计算需求而服务。这些应用程序可用于:
-气候预测、基因组学和药物发现等方面的科学研究
我们相信通过架构创新,可以为这些及其他加速计算节点的应用程序优化能源。
接近2022年中期,AMD正朝着实现30x25的目标前进,仅通过使用基于一颗第三代AMD EPYC CPU和四个AMD Instinct MI250x GPU的加速节点,便可以在2020年的基准水平之上提高6.79倍能效。我们的进度报告采用的测量方法2经过著名的计算能效研究专家Jonathan Koomey博士的验证。
保护地球人人有责,AMD将持续通过提高产品能效,助力可持续发展的低碳经济加速转型,实现节约能源和减少温室气体排放的目标,对全社会产生积极的作用。
1、该情景基于全球所有人工智能和高性能计算服务器节点实现 AMD 30 倍目标的提升,相对于 2020 年的基线趋势,从 2021 年到 2025 年,累计节省高达 514 亿千瓦时的电力。假设每千瓦时 0.12 美分 x 514 亿千瓦时 = 620 万美元。CO2e 排放量(公吨)以及植树当量的估算值来自 2021 年 12 月 1 日将节电量输入美国 EPA 温室气体计算器后得出的结果。https://www.epa.gov/energy/greenhouse-gas-equivalencies-calculator
2、 AMD 在四加速器 CPU 主机配置中对用于人工智能训练和高性能计算的高性能 AMD CPU 和 GPU 加速器进行计算节点效能功耗比测量。
- 高性能计算工作负载的性能基于具有 4k 矩阵大小的 Linpack DGEMM kernel FLOPS。人工智能训练的性能基于在 4k 矩阵上运行的低精度训练浮点数学 GEMM kernel,例如 FP16 或 BF16 FLOPS。
-功耗基于一个典型的加速计算节点(包括 CPU 主机 + 内存以及 4 个 GPU 加速器)的热设计功耗 (TDP)。
为了使该目标与全球能源使用量密切相关,AMD 与 Koomey Analytics 合作评估可用的研究和数据,其中包括 GPU 高性能计算 (HPC) 和机器学习 (ML) 等特定领域数据中心能源使用效率 (PUE)。AMD CPU 和 GPU 节点功耗包含特定领域使用(活动与空闲)百分比,并乘以 PUE 来确定实际总能耗,从而能够计算出效能功耗比。
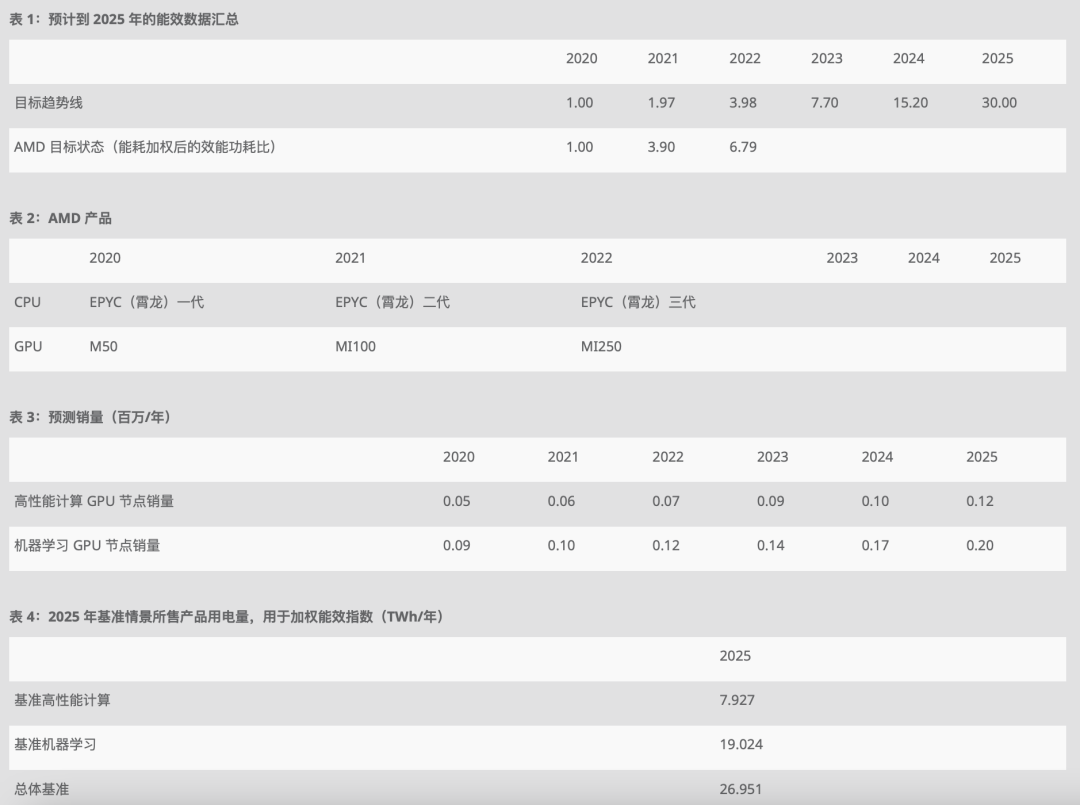
能耗基准采用 2015-2020 年数据中观察到的行业单位作业能耗提升率,并根据这一变化率推测至 2025 年。AMD 目标趋势线(表 1)显示到 2025 年实现能效提升 30 倍目标所需的指数级提升。AMD 实际发布产品(表 2)是表 1 AMD 目标能效提升的来源。
2020 年到 2025 年各领域单位作业能耗提升值是由全球预计销量加权得出(根据 IDC - Q1 2021 TrackerHyperion- Q4 2020 Tracker,Hyperion 高性能计算市场分析,2021 年 4 月)。将这些销量换算到机器学习训练和高性能计算市场,会得出如下表 3 所示的节点量。然后将这些节点量乘以 2025 年各计算领域的典型能源消耗 (TEC)(表 4),得出一个有意义的全球实际能源使用提升的总体指标。
原文标题:AMD EPYC(霄龙) 处理器和AMD Instinct 加速器为高能效添能助力
文章出处:【微信公众号:AMD中国】欢迎添加关注!文章转载请注明出处。
审核编辑:刘清
-
加速器
+关注
关注
2文章
836浏览量
39712 -
AMD处理器
+关注
关注
2文章
60浏览量
13694 -
人工智能
+关注
关注
1813文章
49741浏览量
261564
原文标题:AMD EPYC(霄龙) 处理器和AMD Instinct 加速器为高能效添能助力
文章出处:【微信号:AMD中国,微信公众号:AMD中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
边缘计算中的AI加速器类型与应用

【今晚7点半】正点原子 x STM32:智能加速边缘AI应用开发!今晚正点原子B站直播间等你
瑞萨电子RZ/V系列微处理器助力边缘AI开发

关于人工智能处理器的11个误解
AMD嵌入式处理器为您的应用添能助力
芯原可扩展的高性能GPGPU-AI计算IP赋能汽车与边缘服务器AI解决方案
Banana Pi 发布 BPI-AI2N & BPI-AI2N Carrier,助力 AI 计算与嵌入式开发
支持实时物体识别的视觉人工智能微处理器RZ/V2MA数据手册
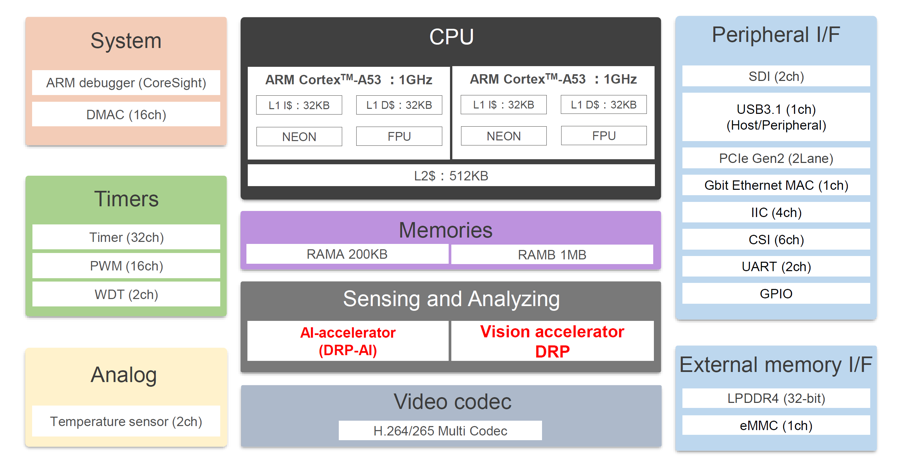
嵌入式AI加速器DRP-AI 详细介绍
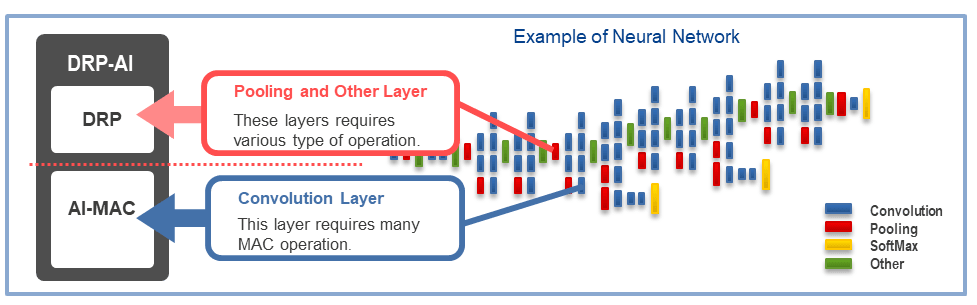
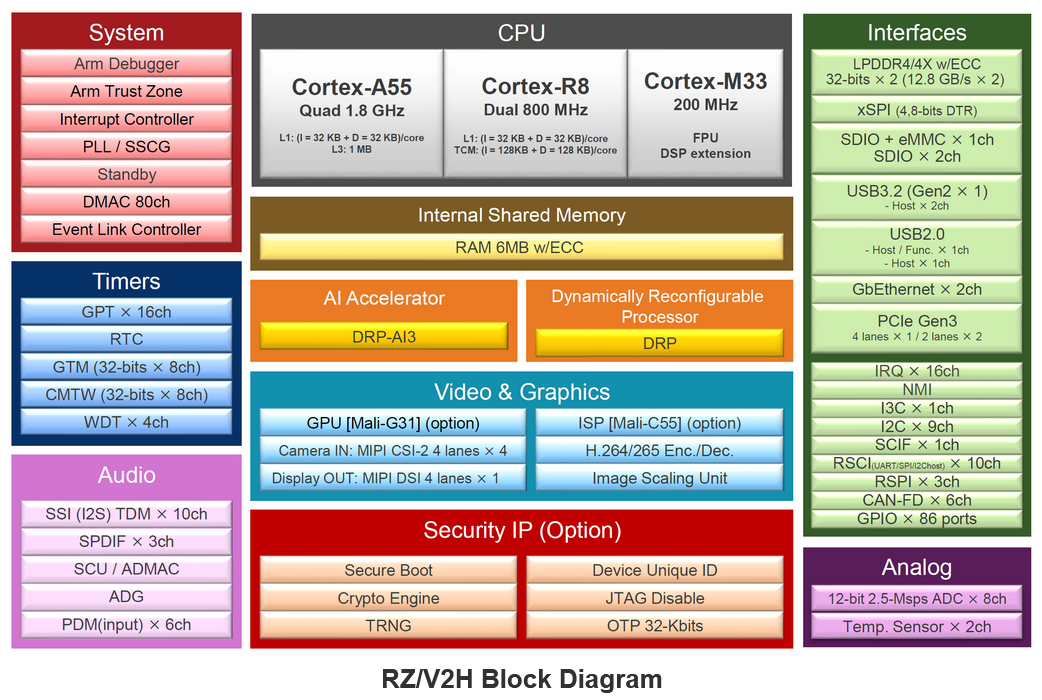
AI MPU# 瑞萨RZ/V2H 四核视觉 ,采用 DRP-AI3 加速器和高性能实时处理器





 工商网监
工商网监
评论