 如何在腾讯云上创建SR1云实例
如何在腾讯云上创建SR1云实例

腾讯 CVM 标准型 SR1 是腾讯云推出的首款搭载 ARM 架构处理器的新一代 CVM 标准型计算实例规格。SR1 基于全核一致主频 3.0GHz 的 Ampere Altra 处理器,实例核数从 1 核到 64 核,并支持 1: 2、1: 4 等多种处理器与内存配比,相对 x86 架构实例为用户提供卓越的性价比。
Ampere 为基于 Ampere Altra 处理器的 SR1 实例提供了优化过的 AI 框架 (Ampere AI),并通过腾讯镜像市场提供免费的镜像给客户使用。本文将介绍如何在腾讯云上创建 SR1 实例,并基于 TensorFlow 对计算机视觉分类性能进行评测。
用 CPU 做推理
现下 AI 推理应用的算力来源主要有三种方式,即 CPU+AI 专用芯片,CPU+GPU 和单纯的 CPU 推理。根据 Statista 和麦肯锡之前发布的AI硬件洞察报告,基于 CPU 的推理目前仍占 50% 以上。相比其他两种模式,采用 CPU 推理的主要原因有几点:
更加灵活便利,软件主导,对应用方来说对专用硬件的依赖性低。
涉及操作系统、驱动程序、运行时组件库等的复杂性较低。
CPU 上 AI 模型算法(例如稀疏性、量化等)的持续优化创新可以提供接近 GPU 的高吞吐量。
更容易实现横向扩展并与其他软件堆栈进行集成。
更重要的是在 CPU 上搭建推理应用可以方便的将 AI 集成到业务逻辑模块,融入微服务云原生体系。
本文将介绍如何在腾讯云上创建 SR1 云实例,基于 SR1 所搭载的 Ampere Altra CPU,以 TensorFlow 为例对计算机视觉分类性能进行评测。
创建 SR1 实例
我们将创建一个 16vCPU 的 SR1 实例 SR1.4XLARGE32 来进行评测,该实例配置 16 个 Ampere Altra 物理核和 32GB 内存。
首先登录腾讯云的控制台,在“实例”类别下选择“新建”,将进入实例创建页面。由于 SR1 目前只在广州六区有售,所以需要选择“广州”->“广州六区”->”标准型 SR1”。
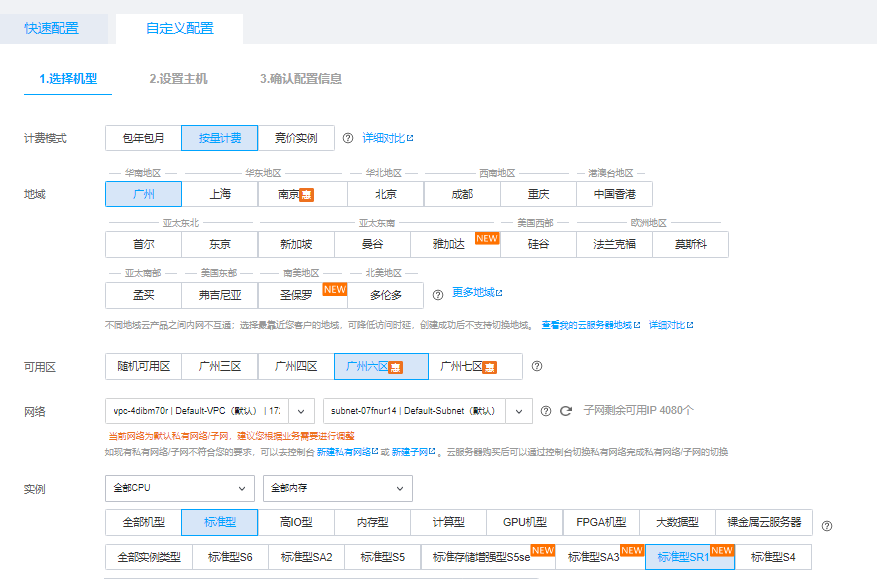
然后将看到不同规格的 SR1 实例,这里我们选择 SR1.4XLARGE32 规格的实例。
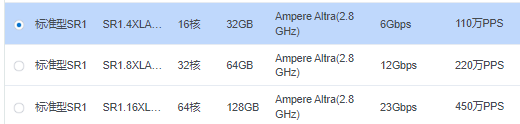
镜像选择“镜像市场”-> “从镜像市场选择”,然后搜索“Ampere”,选取“Ampere Optimized TensorFlow - Ubuntu 20.04”镜像即可免费使用 Ampere 针对 SR1 优化过的 TensorFlow 2.7 以及各种示例程序。

设置好其它的实例配置,就可以确认配置信息并开通实例了。

启动并连接到实例
实例创建完就可以启动并登录了。实例的 IP 地址可以从控制台获取,取决于创建时设置的登录方式,可以使用密码或密钥的方式登录实例。

登录后将看到下面的 Ampere AI 的欢迎界面。
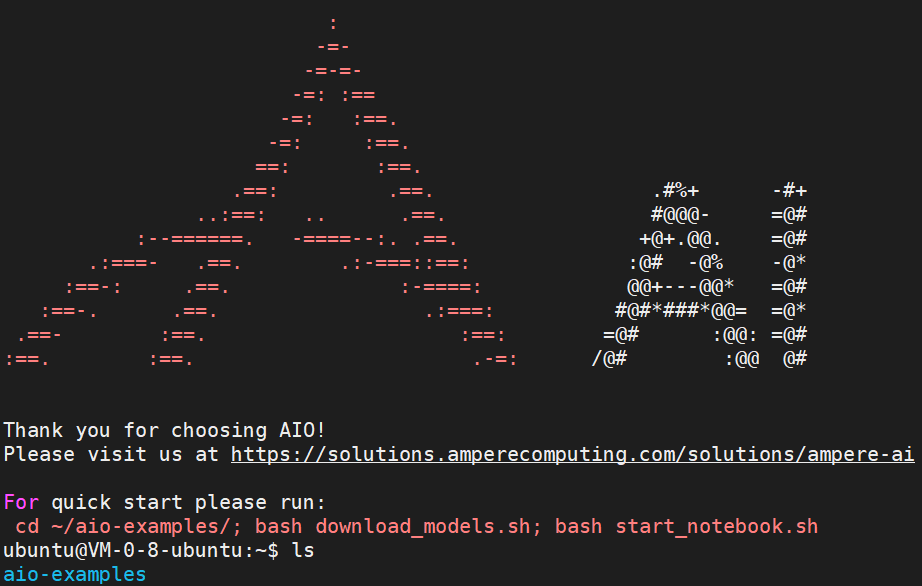
可以看到,这个镜像除了集成了 Ampere 优化的 Tensorflow,也包含 aio-example 的测试代码,该代码也可以从 github 上获取。
运行 TensorFlow AIO 示例
TensorFlow 是一个端到端开源机器学习平台。它拥有一个全面而灵活的生态系统,其中包含各种工具、库和社区资源,可助力研究人员推动先进机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用。
我们创建实例时从镜像市场选择的镜像已经包含了针对 Ampere Altra CPU 优化过的 Tensorflow 2.7。为了运行 aio-example 提供的示例程序,我们需要先下载模型。aio-examples 提供了包括图像分类和对象检测的不同模型,有 32 位的,也有 16 位和 8 位的模型。

取决于网络状况,下载所有的模型将需要几分钟。
我们将用 TensorFlow resnet_50_v15 分类模型来进行测试和评估。ResNet50 是最常用的图像分类模型之一。
由于 Ampere Altra CPU 是单核单线程,SR1 里每一个 vCPU 都对应一个 Altra 物理核,所以在用 SR1.4XLARGE32 测试时,我们指定 AIO_NUM_THREADS 为 16。我们首先测试 FP32 的双精度模型。

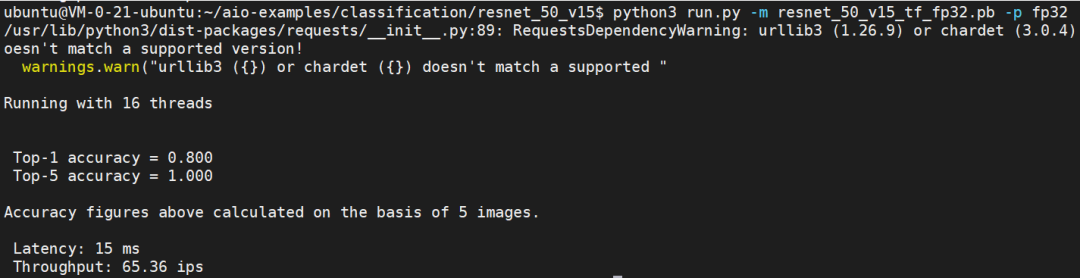
可以看到,使用 16 个核心,resnet_50_v15 可以每秒处理 65.36 张图像(65.36 ips), 延时为 15ms。
下面我们再测试基于 FP16 的模型。

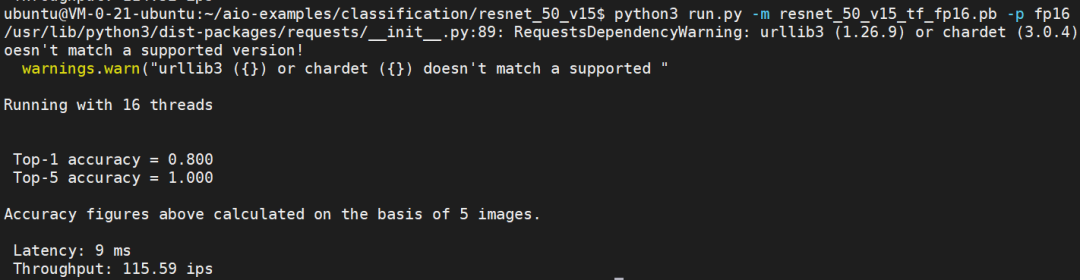
我们看到 FP16 的模型提供了高达 115.59 ips 的吞吐能力,这是因为 Ampere Altra 处理器对 FP16 提供了原生支持。相比 FP32 模型, FP16 模型可以在不影响模型的精度的前提下提供接近 2 倍的图像处理能力。
与其他实例的性能对比
这里的 aio-example 同样可以运行在基于 Intel CPU 和 AMD CPU 的腾讯 CVM 实例上。我们同样创建 16vCPU 的实例 S6.4XLARGE32 和 SA3.4XLARGE32。其中 S6.4XLARGE32 是基于 Intel Xeon Ice Lake 处理器的 16vCPU 实例,SA3.4XLARGE32 是基于 AMD EPYC Milan 处理器的 16vCPU 实例。与 SR1.4XLARGE32 不同的是,这里的 16vCPU 是 16 个线程,而非物理核,实际的物理核为 8。
我们在 S6.4XLARGE32 上运行 intel-tensorflow, 这是 Intel 优化过的 TensorFlow 以充分发挥 AVX-512 指令集的性能。
AMD 也提供了针对 AMD CPU 优化的 ZenDNN,但在腾讯 CVM 里测试的结果并不比 native 的 Tensorflow 更好,所以以下 SA3.4XLARGE32 的数据采用的是 native TensorFlow。
“resnet_50_v15”模型在 3 个平台上的性能表现如下表。

我们可以看到,每秒处理的图像数量(ips),SR1.4xLARGE32 分别比同规格的 S6 和 SA3 实例高出 40% 和 50%;如果再考虑单个实例的价格差异,以相同的价格,SR1.4xLARGE32 可以获得比同规格的 S6 和 SA3 高出 70% 和 40% 的性能。
于此同时,SR1 实例还提供了对 FP16 的支持,可以获得更高的吞吐能力,以及更低的延时特性。
Jupiter Notebook 的可视化示例
aio-example 也提供了 Jupiter Notebook 脚本,方式编辑,调试和实现可视化。
下面将以对象检测模型 SSD Inception v2 为例。首先在 CVM 里启动 Jupiter Notebook。
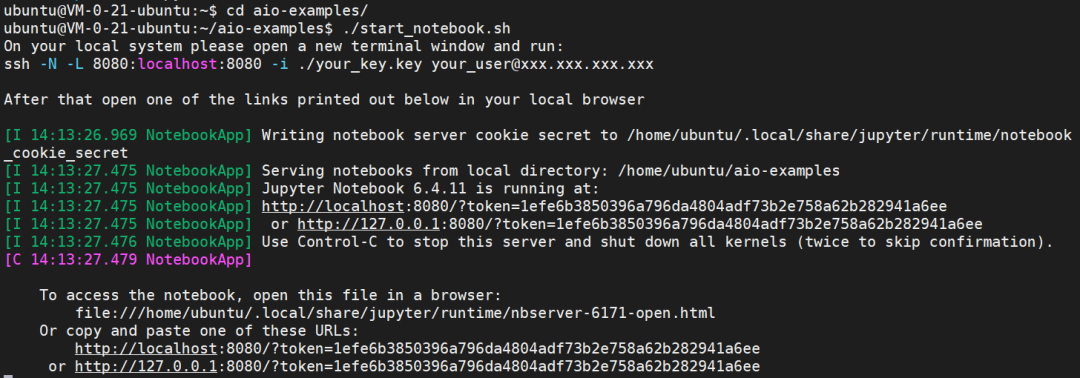
在另外一台有浏览器的机器上,执行以下命令,输入实例的密码,开启 ssh 隧道;然后打开浏览器,输入上面最后一行的地址,就可以看到 AIO 的 Jupiter Notebook 了。

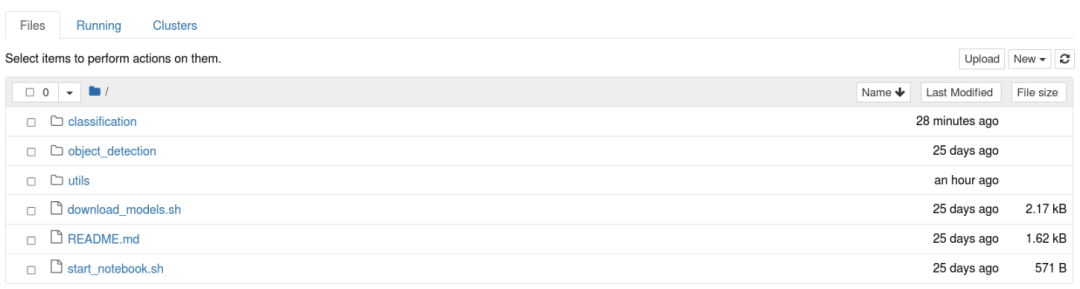
进入“object_detection”,点击“examples.ipynb”,将会看到 Object Detection Examples 的页面。

点击“Cell” -> “Run All”运行。
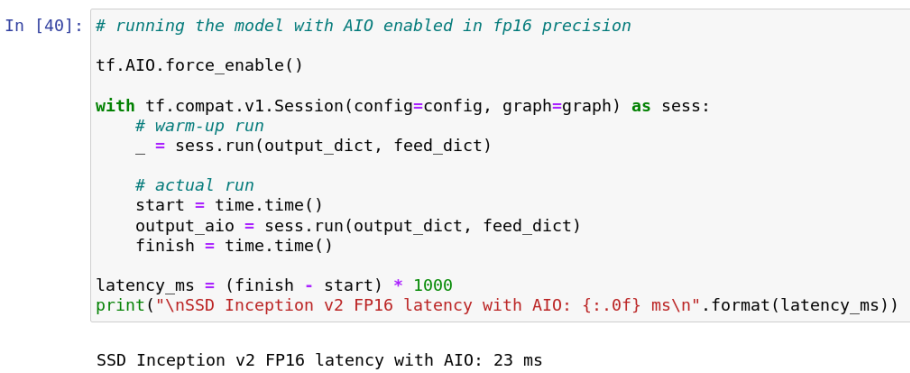
查看运行结果。
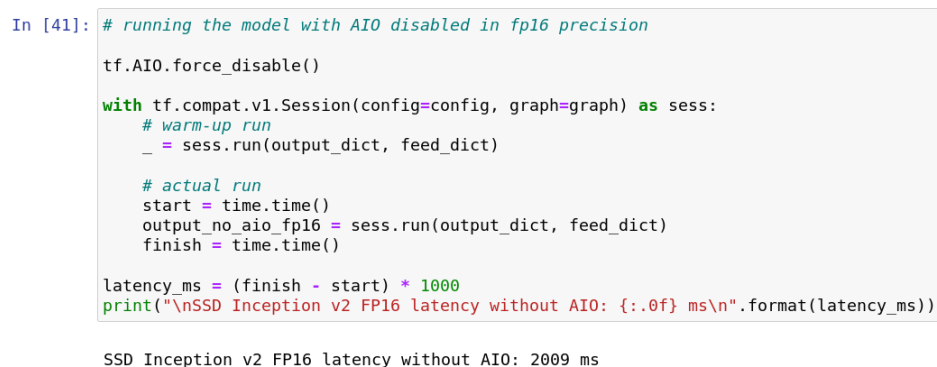
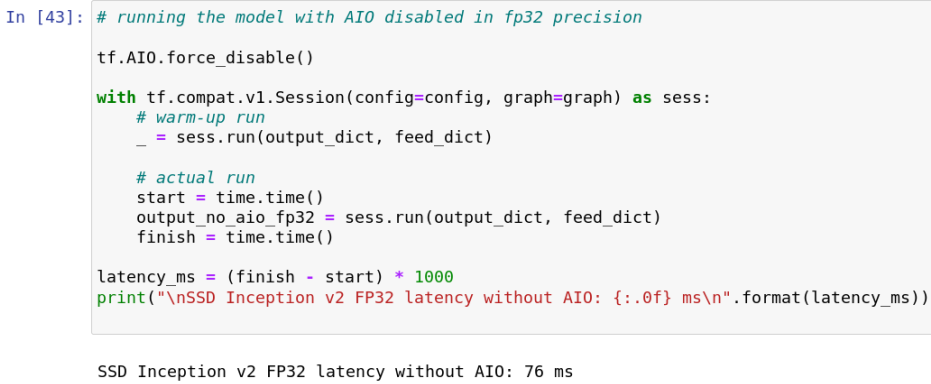



也可以通过同样的方法运行 aio-examples 里面其它的示例。
结 论
采用 Ampere Altra 处理器的腾讯 SR1 实例,充分发挥了单核单线程的性能优势,同时 Ampere AI 优化软件栈将 SR1 在 AI 推理应用中,相对 x86 架构的性价比优势提升到了 70%。
除了腾讯云市场的免费镜像,用户也可以从 Ampere 解决方案网站获取即用型 Docker 映像,包括代码和文档,在接受最终用户许可协议后的进行下载。Docker 映像包含一个标准的 ML 框架(TensorFlow,PyTorch, ONNX等),预装了优化的软件,可以在腾讯 CVM SR1 无需更改即可运行推理脚本。镜像中也提供了图像分类和对象检测等示例模型。
原文标题:安博士讲堂 | 腾讯 Arm 云实例评测系列 - AI 推理
文章出处:【微信公众号:安晟培半导体】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
处理器
+关注
关注
68文章
20333浏览量
255050 -
cpu
+关注
关注
68文章
11331浏览量
225904 -
腾讯云
+关注
关注
0文章
225浏览量
17500 -
Ampere
+关注
关注
1文章
81浏览量
4912
原文标题:安博士讲堂 | 腾讯 Arm 云实例评测系列 - AI 推理
文章出处:【微信号:AmpereComputing,微信公众号:安晟培半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
MediaTek与腾讯云签署战略合作备忘录


什么是企业云服务器-云计算
德明利企业级SSD与OpenCloudOS、腾讯云完成技术兼容互认证




评论