 用AI和高性能计算应对边缘数据挑战
用AI和高性能计算应对边缘数据挑战
未来十年,科学仪器的灵敏度和分辨率将提高 10-100 倍,因此需要相应的存储和处理规模。这些增强型仪器产生的数据将达到摩尔定律无法充分解决的极限,它将挑战仅基于数据中心 HPC 的传统运营模式。
边缘计算 依赖 AI 和 高性能计算 ( HPC )来跟上这些增强功能的时代已经到来。
5 月 30 日, NVIDIA 超尺度和 HPC 计算副总裁伊恩·巴克博士在德国汉堡的 国际超级计算大会 ( ISC )特别演讲中回应了这种观点。在介绍此 边缘计算背景下 HPC 和 AI 本质的视角转变 的同时,特别演讲还介绍了一个旨在解决边缘 HPC 数据密集型工作负载这一难题的平台: NVIDIA Holoscan 。
介绍用于 HPC Edge 的 NVIDIA Holoscan 平台
NVIDIA Holoscan 平台已经扩展,以满足 DevOps 工程师、性能工程师、数据科学家和研究人员在这些不可思议的边缘仪器上工作的特定需求。
现代实时、边缘人工智能应用正日益成为多模式应用。它们涉及高速 IO 、视觉 AI 、成像 AI 、图形、流媒体技术等。创建和维护这些应用程序非常困难。扩展它们甚至更加困难。
NVIDIA 正在构建流式反应式框架( SRF ),以应对这些挑战。
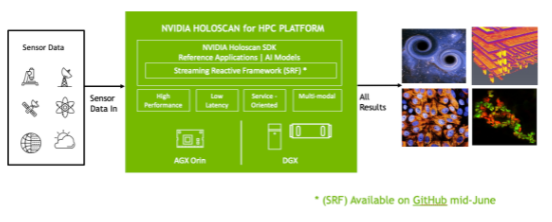
图 1 :。 NVIDIA Holoscan for HPC 工作流
虽然Holoscan最初是针对医疗保健,但它是一个通用的计算和成像平台,旨在实现高性能,同时满足边缘的尺寸重量和功率(SWaP)限制。
现在, Holoscan 平台得到了扩展,这得益于一个易于使用的软件框架,该框架通过确保最大的流数据性能和计算,最大限度地提高了开发人员的生产率。该平台是云本机平台,支持边缘位置和数据中心之间的混合计算和数据管道。它的体系结构还考虑了可伸缩性,使用了网络感知优化和异步计算。
扩展的 Holoscan 平台提供了一个灵活的软件堆栈,可以在基于 NVIDIA Jetson AGX Xavier 或 Jetson AGX Orin 。 还有一个云本机版本,运行在常见的高性能硬件上,以加速边缘的数据分析和可视化工作流。
介绍 NVIDIA 流式反应式框架
HPC 和 AI 研究领域最优秀的人才正在不断开发更快更好的算法,以解决当今最具挑战性的问题。然而,许多开发人员发现,将他们的模型和代码移植到全速率生产是一项挑战,尤其是在面临高速流输入和严格的吞吐量和延迟要求时。
一个有效的解决方案需要各种技能:从数据科学家到性能工程师的人才,同时跨越多种软件语言、硬件和软件架构、位置和缩放规则。因此, NVIDIA 创建了流式反应式框架( SRF ),以减轻对生产的研究负担,同时保持光速性能。
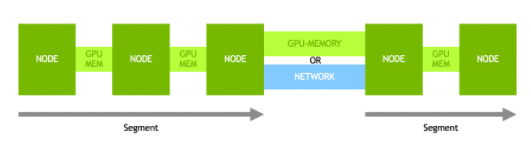
图 2 :。在 Holoscan 中, HPC 流式数据管道使用 SRF 进行了标准化,以便为传感器数据构建模块化和可重用的管道
NVIDIA SRF 是一个网络感知、灵活且面向性能的流式数据框架,它为 C ++和 Python 开发人员标准化并简化了从云到边缘的生产 HPC 和 AI 部署。
构建 NVIDIA SRF 管道时,请指定应用程序数据流。以及缩放和放置逻辑。放置逻辑指示数据流运行的硬件,缩放逻辑表示需要多少并行拷贝才能满足性能要求。
NVIDIA SRF 可以轻松地与 C ++和 Python 代码以及特定于域的 SDK 的 NVIDIA 目录集成。
NVIDIA SRF 仍处于实验阶段,正在积极开发中。您可以在 2022 年 6 月中旬访问 在 GitHub 上下载 NVIDIA SRF 。
用于可视化和成像的 AI
NVIDIA Orin ,一种基于 AI 推断中的 NVIDIA 安培体系结构 、 设置新记录 的低功耗片上系统,提高了每台加速器的性能。它比上一代 Jetson AGX Xavier 快 5 倍,同时平均能效提高 2 倍。
Jetson AGX Orin 是用于 HPC 和 NVIDIA Clara Holoscan 的 Holoscan 的关键成分,该平台系统制造商和研究人员正在使用该平台开发下一代 AI 仪器。其强大的成像计算能力和多功能软件堆栈使其对涉及可视化和成像的 HPC 边缘用例具有吸引力。
Orin 凭借其 JetPack SDK 运行完整的 NVIDIA AI 平台,这是一个已经在数据中心和云计算中得到验证的软件栈。它得到了使用 NVIDIA Jetson 平台的 100 万开发人员的支持。
美国能源部阿贡国家实验室( ArgonneNational Laboratory )的 高级光子源 ( APS )可以产生超明亮的高能光子束。光子的亮度是标准医院 X 光机的 1000 亿倍,可以在纳米级和原子级上拍摄图像。随着 2024 年 APS-U 的升级,它将能够产生比当前机器亮 500 倍的光子。
牛津大学的钻石光源 是世界一流的同步加速器设备,正在将现有光束线和五条新的旗舰光束线的亮度和相干性提高 20 倍。 Diamond 的数据传输速率已经达到每月 PB ,使用 Diamond II ,预计至少会高出一个数量级。
在世界范围内,有 50 多个先进光源支持 16000 多名研究科学家的工作,这些仪器也有更多的升级。虽然所有这些进步本身都很显著,但它们依赖于计算和数据科学家准备好在边缘的超级计算机上运行人工智能数据处理应用程序。
PtychoNN : APS 边缘计算平台
APS 是一台足球场大小的机器,可以产生光子束。这些光束用于研究材料、物理和生物结构。
如今,生成具有纳米级分辨率的材料图像的一种方法是光子照相法( ptychography ),这是一种计算密集型方法,用于将散射的 X 射线干涉图转换为实际物体的图像。
到目前为止,该方法需要解决一个具有挑战性的反问题,即使用正向和反向傅里叶变换,根据在数万次 X 射线测量中观察到的衍射图案,迭代计算物体的图像。科学家们等了几天才得到实验图像的结果。
现在,有了人工智能,科学家们可以绕过大部分反演过程,在实验进行时查看物体的图像,甚至可以在飞行中进行调整。
有了人工智能, APS 的科学家们能够使用流式 ptychography 管道,通过深度卷积神经网络模型 PtychoNN 进行加速,从而将图像处理速度提高 300 倍以上,并将生成高质量图像所需的数据减少 25 倍。
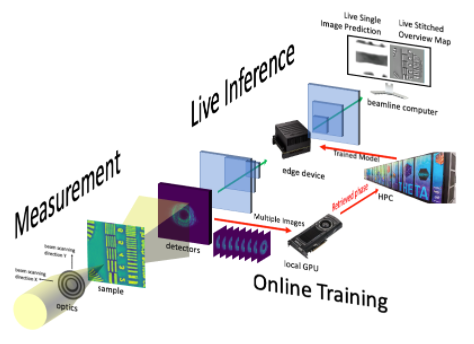
图3. 在A100上的数据中心培训PtychoNN模型,并在波束线仪器上部署经过培训的AI模型,AGX Orin运行PtychoNN以更快300倍的速度传输图像
PtychoNN 模型的培训 NVIDIA A100 Tensor Core GPU 具有深度学习和 X 射线图像相位检索数据。经过训练的模型可以在 edge 设备上运行,以直接将传入的衍射图像映射到真实空间中的对象图像,并在毫秒内实时映射。
更快的取样意味着仪器的使用效率更高,为调查更多材料提供了机会。它提供了以前不可能实现的功能,例如查看在 X 射线束中受损的生物材料样本、快速变化的样本或与 X 射线束大小相比较大的样本。
通用的硬件和软件体系结构简化了编排, NVIDIA AGX 位于边缘, A100 GPU 群集位于数据中心。该解决方案易于扩展,以跟上 APS 预期的 125 倍数据速率增长。预计 2022 年的探测器升级和 2024 年的设施升级将带来增长。
“为了充分利用升级后的 APS 的功能,我们必须重新设计数据分析。我们目前的方法不足以跟上。机器学习可以充分利用并超越当前的可能。”
Mathew Cherukara ,阿贡国家实验室计算科学家
这种使用 NVIDIA GPU 和 PtychoNN 的工作流程和方法可能是世界上许多其他光源的适用模型,这些光源也可以 通过实时 X 射线成像加速科学突破 。
在前面的示例中,单个 GPU 边缘设备使用经过训练的神经网络加速图像流。 edge 实验耗时数天,现在只需几分之一秒,研究人员就可以实时交互使用他们的大型科学仪器。有关边缘其他相关 HPC 和 AI 示例的更多信息,请参阅以下参考资料:
边缘高性能地理空间图像处理
Clara 全息扫描实时显示活细胞显微图像
使用 NVIDIA 工具包的高级传感器处理管道
虽然我们的许多突出的 edge HPC 应用程序都专注于流式视频和成像管道,但 NVIDIA Holoscan 可以扩展到具有各种数据格式和速率的其他传感器类型。无论您是使用软件定义的无线电进行高带宽频谱分析,还是从电网监测遥测异常, NVIDIA Holoscan 都是软件定义仪器的首选平台。
通过关注开发人员的生产力和应用程序性能,无论传感器是什么,边缘 HPC 都可以提供实时分析和任务成功。
关于作者
Harry Petty 是一位经验丰富的数据中心营销人员和技术专家,曾在大型科技公司担任领导职务,为混合云、存储解决方案、网络处理器和服务器产品线推广 SDN 产品。
Geetika Gupta 是 HPC + AI 和 Edge 应用的领先产品。自 NVIDIA 开普勒一代以来,她一直担任数据中心 GPU 的产品经理,现在专注于 HPC + AI 和流式数据用例的融合。 Geetika 拥有加州大学洛杉矶分校安德森学院的 MBA 学位和 IITBHU 的机械工程学士学位。
Adam Thompson 是 NVIDIA 的高级解决方案架构师。他有信号处理方面的背景,他的职业生涯一直在参与和领导一些项目,这些项目专注于射频分类、数据压缩、高性能计算、统计信号处理以及管理和设计针对大数据框架的应用程序。
审核编辑:郭婷
-
处理器
+关注
关注
68文章
18304浏览量
222351 -
NVIDIA
+关注
关注
14文章
4598浏览量
101775 -
gpu
+关注
关注
27文章
4426浏览量
126755
发布评论请先 登录
相关推荐


环旭电子推出为应对数据时代挑战而优化的边缘计算解决方案
智能网卡简介及其在高性能计算中的作用
从高性能内核到双核设计,MCU朝边缘AI进击

Rambus提升GDDR6带宽,以应对边缘计算挑战
边缘计算AI入门

研华边缘计算设备EPC-B5000,高AI算力加速边缘计算






 工商网监
工商网监
评论