 使用NVIDIA DCGM构建GPU监控解决方案
使用NVIDIA DCGM构建GPU监控解决方案

对于基础设施或站点可靠性工程( SRE )团队来说,监控多个 GPU 对于管理大型 GPU 集群以实现 AI 或 HPC 工作负载至关重要。 GPU 指标允许团队了解工作负载行为,从而优化资源分配和利用率,诊断异常,并提高数据中心的整体效率。除了基础设施团队之外,无论您是从事 GPU – 加速 ML 工作流的研究人员,还是喜欢了解 GPU 利用率和容量规划饱和的数据中心设计师,您应该都对指标感兴趣。
这些趋势变得更为重要,因为 AI / ML 工作负载通过使用 Kubernetes 之类的容器管理平台进行容器化和扩展。在这篇文章中,我们将概述 NVIDIA 数据中心 GPU 经理( DCGM ),以及如何将其集成到诸如 Prometheus 和 Grafana 这样的开源工具中,从而为 Kubernetes 构建一个 GPU 监控解决方案。
NVIDIA DCGM 公司
NVIDIA DCGM 公司 是一组用于在基于 Linux 的大规模集群环境中管理和监视 NVIDIA GPUs 的工具。它是一个低开销的工具,可以执行各种功能,包括主动健康监视、诊断、系统验证、策略、电源和时钟管理、组配置和记帐。
DCGM 包括用于收集 GPU 遥测的 API。特别感兴趣的是 GPU 利用率指标(用于监视张量核心、 FP64 单元等)、内存指标和互连流量指标。 DCGM 为各种语言(如 C 和 Python )提供了绑定,这些都包含在安装程序包中。为了与 Go 作为编程语言流行的容器生态系统集成,有基于 DCGM API 的 Go 绑定 。存储库包括示例和 restapi ,以演示如何使用 Go API 监视 GPUs 。去看看 NVIDIA/gpu-monitoring-tools repo !
导出
监控堆栈通常由一个收集器、一个存储度量的时间序列数据库和一个可视化层组成。一个流行的开源堆栈是 Prometheus ,与 Grafana 一起作为可视化工具来创建丰富的仪表板。普罗米修斯还包括 Alertmanager 来创建和管理警报。 Prometheus 与 kube-state-metrics 和 node_exporter 一起部署,以公开 kubernetesapi 对象的集群级指标和节点级指标,如 CPU 利用率。图 1 显示了普罗米修斯的一个架构示例。
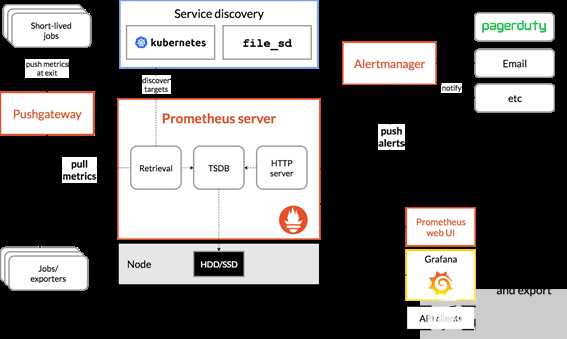
图 1 参考普罗米修斯建筑。
在前面描述的 Go API 的基础上,可以使用 DCGM 向 Prometheus 公开 GPU 度量。为此,我们建立了一个名为 dcgm-exporter 的项目。
dcgm-exporter 使用 Go 绑定 从 DCGM 收集 GPU 遥测数据,然后为 Prometheus 公开指标以使用 http 端点(/metrics)进行提取
dcgm-exporter 也是可配置的。您可以使用 .csv 格式的输入配置文件,自定义 DCGM 要收集的 GPU 指标。
Kubernetes 集群中的每个 pod GPU 指标
dcgm-exporter 收集节点上所有可用 GPUs 的指标。然而,在 Kubernetes 中,当一个 pod 请求 GPU 资源时,您不一定知道节点中的哪个 GPUs 将被分配给一个 pod 。从 v1 。 13 开始, kubelet 添加了一个设备监视功能,可以使用 pod 资源套接字找到分配给 pod — 的 pod 名称、 pod 名称空间和设备 ID 的设备。
dcgm-exporter 中的 http 服务器连接到 kubelet pod resources 服务器( /var/lib/kubelet/pod-resources ),以标识在 pod 上运行的 GPU 设备,并将 GPU 设备 pod 信息附加到收集的度量中。
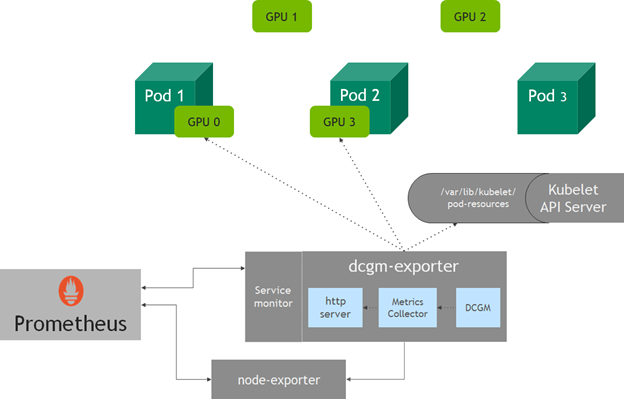
图 2 GPU 在 Kubernetes 使用 dcgm exporter 进行遥测。
设置 GPU 监控解决方案
下面是一些设置 dcgm-exporter 的示例。如果您使用的是 NVIDIA GPU 操作员 ,那么 dcgm-exporter 是作为操作员的一部分部署的组件之一。
文档包括 建立 Kubernetes 集群 的步骤。为了简洁起见,请快速前进到使用 NVIDIA 软件组件运行 Kubernetes 集群的步骤,例如,驱动程序、容器运行时和 Kubernetes 设备插件。您可以使用 Prometheus Operator 来部署 Prometheus ,它还可以方便地部署 Grafana 仪表板。在本文中,为了简单起见,您将使用单节点 Kubernetes 集群。
设置 普罗米修斯运营商目前提供的社区头盔图 时,必须遵循 将 GPU 遥测技术集成到 Kubernetes 中 中的步骤。必须为外部访问公开 Grafana ,并且必须将 prometheusSpec.serviceMonitorSelectorNilUsesHelmValues 设置为 false 。
简而言之,设置监视包括运行以下命令:
$ helm repo add prometheus-community \ https://prometheus-community.github.io/helm-charts $ helm repo update $ helm inspect values prometheus-community/kube-prometheus-stack > /tmp/kube-prometheus-stack.values # Edit /tmp/kube-prometheus-stack.values in your favorite editor # according to the documentation # This exposes the service via NodePort so that Prometheus/Grafana # are accessible outside the cluster with a browser $ helm install prometheus-community/kube-prometheus-stack \ --create-namespace --namespace prometheus \ --generate-name \ --set prometheus.service.type=NodePort \ --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false
此时,您的集群应该看起来像下面这样,其中所有的 Prometheus pods 和服务都在运行:
$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-8f59968d4-zrsdt 1/1 Running 0 18m kube-system calico-node-c257f 1/1 Running 0 18m kube-system coredns-f9fd979d6-c52hz 1/1 Running 0 19m kube-system coredns-f9fd979d6-ncbdp 1/1 Running 0 19m kube-system etcd-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-apiserver-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-controller-manager-ip-172-31-27-93 1/1 Running 1 19m kube-system kube-proxy-b9szp 1/1 Running 1 19m kube-system kube-scheduler-ip-172-31-27-93 1/1 Running 1 19m kube-system nvidia-device-plugin-1602308324-jg842 1/1 Running 0 17m prometheus alertmanager-kube-prometheus-stack-1602-alertmanager-0 2/2 Running 0 92s prometheus kube-prometheus-stack-1602-operator-c4bc5c4d5-f5vzc 2/2 Running 0 98s prometheus kube-prometheus-stack-1602309230-grafana-6b4fc97f8f-66kdv 2/2 Running 0 98s prometheus kube-prometheus-stack-1602309230-kube-state-metrics-76887bqzv2b 1/1 Running 0 98s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter-rrk9l 1/1 Running 0 98s prometheus prometheus-kube-prometheus-stack-1602-prometheus-0 3/3 Running 1 92s $ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.96.0.1443/TCP 20m kube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 20m kube-system kube-prometheus-stack-1602-coredns ClusterIP None 9153/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-controller-manager ClusterIP None 10252/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-etcd ClusterIP None 2379/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-proxy ClusterIP None 10249/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-scheduler ClusterIP None 10251/TCP 2m18s kube-system kube-prometheus-stack-1602-kubelet ClusterIP None 10250/TCP,10255/TCP,4194/TCP 2m12s prometheus alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 2m12s prometheus kube-prometheus-stack-1602-alertmanager ClusterIP 10.104.106.174 9093/TCP 2m18s prometheus kube-prometheus-stack-1602-operator ClusterIP 10.98.165.148 8080/TCP,443/TCP 2m18s prometheus kube-prometheus-stack-1602-prometheus NodePort 10.105.3.19 9090:30090/TCP 2m18s prometheus kube-prometheus-stack-1602309230-grafana ClusterIP 10.100.178.41 80/TCP 2m18s prometheus kube-prometheus-stack-1602309230-kube-state-metrics ClusterIP 10.100.119.13 8080/TCP 2m18s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter ClusterIP 10.100.56.74 9100/TCP 2m18s prometheus prometheus-operated ClusterIP None 9090/TCP 2m12s
安装 DCGM-Exporter
下面是如何开始安装 dcgm-exporter 来监视 GPU 的性能和利用率。您可以使用头盔图表来设置 dcgm-exporter 。首先,添加 Helm 回购:
$ helm repo add gpu-helm-charts \ https://nvidia.github.io/gpu-monitoring-tools/helm-charts
$ helm repo update
然后,使用 Helm 安装图表:
$ helm install \ --generate-name \ gpu-helm-charts/dcgm-exporter
可以使用以下命令观察展开:
$ helm ls NAME NAMESPACE REVISION APP VERSION dcgm-exporter-1-1601677302 default 1 dcgm-exporter-1.1.0 2.0.10 nvidia-device-plugin-1601662841 default 1 nvidia-device-plugin-0.7.0 0.7.0
普罗米修斯和格拉法纳的服务应公开如下:
$ kubectl get svc -A NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default dcgm-exporter ClusterIP 10.99.34.1289400/TCP 43d default kubernetes ClusterIP 10.96.0.1 443/TCP 20m kube-system kube-dns ClusterIP 10.96.0.10 53/UDP,53/TCP,9153/TCP 20m kube-system kube-prometheus-stack-1602-coredns ClusterIP None 9153/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-controller-manager ClusterIP None 10252/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-etcd ClusterIP None 2379/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-proxy ClusterIP None 10249/TCP 2m18s kube-system kube-prometheus-stack-1602-kube-scheduler ClusterIP None 10251/TCP 2m18s kube-system kube-prometheus-stack-1602-kubelet ClusterIP None 10250/TCP,10255/TCP,4194/TCP 2m12s prometheus alertmanager-operated ClusterIP None 9093/TCP,9094/TCP,9094/UDP 2m12s prometheus kube-prometheus-stack-1602-alertmanager ClusterIP 10.104.106.174 9093/TCP 2m18s prometheus kube-prometheus-stack-1602-operator ClusterIP 10.98.165.148 8080/TCP,443/TCP 2m18s prometheus kube-prometheus-stack-1602-prometheus NodePort 10.105.3.19 9090:30090/TCP 2m18s prometheus kube-prometheus-stack-1602309230-grafana ClusterIP 10.100.178.41 80:32032/TCP 2m18s prometheus kube-prometheus-stack-1602309230-kube-state-metrics ClusterIP 10.100.119.13 8080/TCP 2m18s prometheus kube-prometheus-stack-1602309230-prometheus-node-exporter ClusterIP 10.100.56.74 9100/TCP 2m18s prometheus prometheus-operated ClusterIP None 9090/TCP 2m12s
使用在端口 32032 公开的 Grafana 服务,访问 Grafana 主页。使用普罗米修斯图表中可用的凭据登录到仪表板: prometheus.values 中的 adminPassword 字段。
现在要为 GPU 度量启动 Grafana 仪表板,请从 数一数仪表板。 导入引用的 NVIDIA 仪表板。
使用 DCGM 仪表板
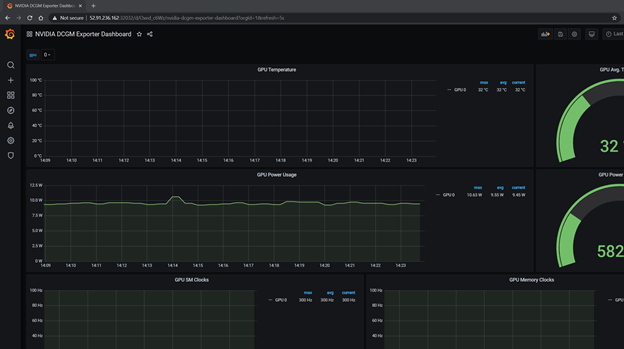
图 3 参考 NVIDIA Grafana dashboard 。
现在运行一些 GPU 工作负载。为此, DCGM 包括一个名为 dcgmproftester 的 CUDA 负载生成器。它可以用来生成确定性的 CUDA 工作负载,用于读取和验证 GPU 度量。我们有一个集装箱化的 dcgmproftester ,可以在 Docker 命令行上运行。这个例子生成一个半精度( FP16 )矩阵乘法( GEMM ),并使用 GPU 上的张量核。
产生负载
要生成负载,必须首先下载 DCGM 并将其容器化。下面的脚本创建一个可用于运行 dcgmproftester 的容器。此容器可在 NVIDIA DockerHub 存储库中找到。
#!/usr/bin/env bash set -exo pipefail mkdir -p /tmp/dcgm-docker pushd /tmp/dcgm-docker cat > Dockerfile <在将容器部署到 Kubernetes 集群之前,请尝试在 Docker 中运行它。在本例中,通过指定
-t 1004,使用张量核心触发 FP16 矩阵乘法,并运行测试-d 45( 45 秒)。您可以通过修改-t参数来尝试运行其他工作负载。$ docker run --rm --gpus all --cap-add=SYS_ADMIN nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 --no-dcgm-validation -t 1004 -d 45 Skipping CreateDcgmGroups() since DCGM validation is disabled CU_DEVICE_ATTRIBUTE_MAX_THREADS_PER_MULTIPROCESSOR: 1024 CU_DEVICE_ATTRIBUTE_MULTIPROCESSOR_COUNT: 40 CU_DEVICE_ATTRIBUTE_MAX_SHARED_MEMORY_PER_MULTIPROCESSOR: 65536 CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR: 7 CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR: 5 CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH: 256 CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE: 5001000 Max Memory bandwidth: 320064000000 bytes (320.06 GiB) CudaInit completed successfully. Skipping WatchFields() since DCGM validation is disabled TensorEngineActive: generated ???, dcgm 0.000 (27605.2 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28697.6 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28432.8 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28585.4 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28362.9 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28361.6 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28448.9 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28311.0 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28210.8 gflops) TensorEngineActive: generated ???, dcgm 0.000 (28304.8 gflops)将此计划到您的 Kubernetes 集群上,并在 Grafana 仪表板中查看适当的度量。下面的代码示例使用容器的适当参数构造此 podspec :
cat << EOF | kubectl create -f - apiVersion: v1 kind: Pod metadata: name: dcgmproftester spec: restartPolicy: OnFailure containers: - name: dcgmproftester11 image: nvidia/samples:dcgmproftester-2.0.10-cuda11.0-ubuntu18.04 args: ["--no-dcgm-validation", "-t 1004", "-d 120"] resources: limits: nvidia.com/gpu: 1 securityContext: capabilities: add: ["SYS_ADMIN"] EOF您可以看到
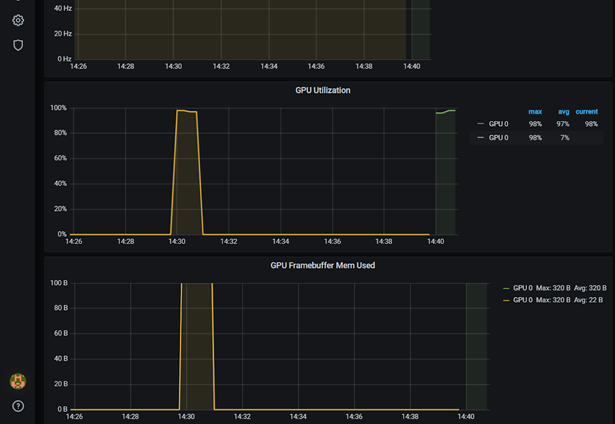
dcgmproftesterpod 正在运行,然后在 Grafana 仪表板上显示度量。 GPU 利用率( GrActive )已达到 98% 的峰值。您还可能会发现其他指标很有趣,比如 power 或 GPU 内存。$ kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE ... default dcgmproftester 1/1 Running 0 6s ...
图 4 GPU 运行 dcgmproftest 时在 Grafana 中的利用率。
验证 GPU 指标
DCGM 最近增加了一些设备级指标。其中包括细粒度的 GPU 利用率指标,可以监视 SM 占用率和 Tensor 核心利用率。为了方便起见,当您使用 Helm 图表部署 dcgm-exporter 时,它被配置为默认收集这些度量。
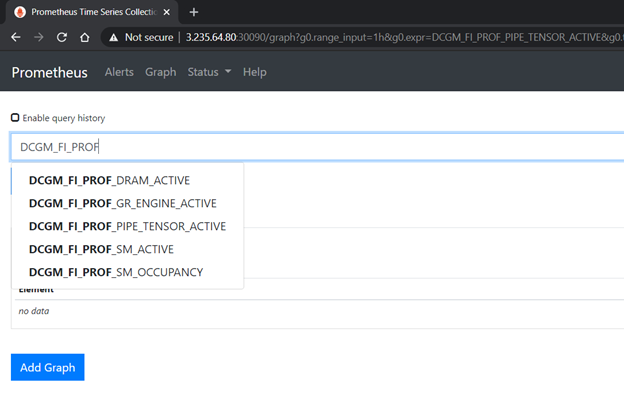
图 5 显示了在 Prometheus 仪表板中验证 dcgm-exporter 提供的评测指标。
图 5 GPU 在普罗米修斯仪表板中分析 DCGM 的指标。
您可以定制 Grafana 仪表板以包含 DCGM 的其他指标。在本例中,通过编辑 repo 上可用的 JSON 伯爵夫人 文件,将 Tensor 核心利用率添加到仪表板中。你也可以使用网页界面。请随意修改仪表板。
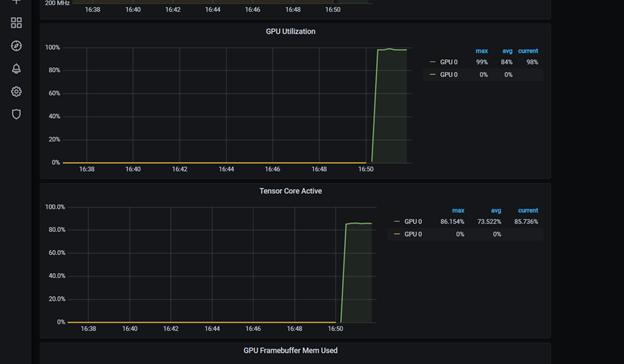
此仪表板包括 Tensor 核心利用率。您可以进一步自定义它。重新启动 dcgmproftester 容器后,您可以看到 T4 上的张量核心已达到约 87% 的利用率:
图 6 Grafana 的张量核心利用率(百分比)。
请随意修改 JSON 仪表板,以包含 DCGM 支持的其他 GPU 指标。支持的 GPU 指标在 DCGM DCGM API Documentation 中可用。通过使用 GPU 指标作为定制指标和普罗米修斯适配器,您可以使用 卧式吊舱自动标度机 根据 GPU 利用率或其他指标来缩放吊舱的数量。
概要
要从 dcgm-exporter 开始,并将监视解决方案放在 Kubernetes 上,无论是在前提还是在云中,请参阅 将 GPU 遥测技术集成到 Kubernetes 中 ,或将其部署为 NVIDIA GPU 操作员 的一部分。
关于作者
Pramod Ramarao 是 NVIDIA 加速计算的产品经理。他领导 CUDA 平台和数据中心软件的产品管理,包括容器技术。
Ahmed Al-Sudani 是 NVIDIA DCGM 团队的软件工程师。他致力于在数据中心环境中实现健康和性能监控。
Swati Gupta 是 NVIDIA 的系统软件工程师,她在 OpenShift 云基础设施、协调和监控方面工作。她专注于在容器编排系统(如 Kubernetes 、 GPU 和 Docker )中启用 GPU - 加速的 DL 和 AI 工作负载。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5694浏览量
110118 -
gpu
+关注
关注
28文章
5272浏览量
136070 -
数据中心
+关注
关注
18文章
5773浏览量
75208
发布评论请先 登录
NVIDIA向Kubernetes社区捐赠动态资源分配GPU驱动程序
NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
NVIDIA RTX PRO 5000 Blackwell GPU的深度评测

在Python中借助NVIDIA CUDA Tile简化GPU编程

NVIDIA RTX PRO 2000 Blackwell GPU性能测试

NVIDIA推出NVQLink高速互连架构
Lambda采用Supermicro NVIDIA Blackwell GPU服务器集群构建人工智能工厂
NVIDIA RTX PRO 4500 Blackwell GPU测试分析

NVIDIA Omniverse Extension开发秘籍



评论