 如何使用NVIDIA TAO快速准确地训练AI模型
如何使用NVIDIA TAO快速准确地训练AI模型

越来越多的要求制造商在其生产过程中达到高质量控制标准。传统上,制造商依靠人工检查来保证产品质量。然而,手动检查成本高昂,通常只覆盖一小部分生产样本,最终导致生产瓶颈、生产率降低和效率降低。
通过人工智能和计算机视觉实现缺陷检测自动化,制造商可以彻底改变其质量控制流程。然而,制造商和全自动化之间存在一个主要障碍。构建一个 AI 系统和生产就绪的应用程序是困难的,通常需要一个熟练的 AI 团队来训练和微调模型。一般制造商不采用这种专业技术,而是采用手动检查。
本项目的目标是展示如何使用NVIDIA转移学习工具包( TLT )和预训练模型快速建立制造过程中更精确的质量控制。这个项目是在没有人工智能专家或数据科学家的情况下完成的。为了了解 NVIDIA TLT 在为商业质量控制目的培训人工智能系统方面的有效性,使用公开的 dataset 钢焊接工艺,从 NGC 目录(一个 GPU 优化的人工智能和 HPC 软件中心)重新培训预培训的 ResNet-18 模型,使用 TLT 。我们比较了人工智能研究团队先前发表的一项工作中,在数据集上从头开始构建的模型和由此产生的模型的准确性。
NVIDIA TLT 操作简便、速度快,不具备人工智能专业知识的工程师可以轻松使用。我们观察到 NVIDIA TLT 的设置速度更快,结果更准确,宏观平均 F1 成绩 为 97% ,而之前发布的数据集“从头开始构建”的结果为 78% 。
这篇文章探讨了 NVIDIA TLT 如何快速准确地训练 AI 模型,展示了 AI 和转移学习如何改变图像和视频分析以及工业流程的部署方式。
具有 NVIDIA TLT 的工作流
NVIDIA TLT 是 NVIDIA 训练、调整和优化( TAO )平台 的核心组件,遵循零编码范式快速跟踪 AI 开发。 TLT 附带了一套随时可用的 Jupyter 笔记本、 Python 脚本和配置规范以及默认参数值,使您能够快速轻松地开始培训和微调数据集。
为了开始使用 NVIDIA TLT ,我们遵循了以下 快速入门指南说明 。
我们下载了 Docker 容器和 TLT Jupyter 笔记本。
我们将数据集映射到 Docker 容器上。
我们开始了第一次培训,调整了默认的培训参数,如网络结构、网络大小、优化器等,直到我们对结果感到满意。
数据集
这个项目中使用的数据集是由伯明翰大学的研究人员为他们的论文 基于可见 spectrum 摄像机和机器学习的 SS304 TIG 焊接过程缺陷自动分类 创建的。
该数据集由超过 45K 的灰度焊接图像组成,可通过 Kaggle 获得。数据集描述了一类正确执行: good_weld 。钨极惰性气体( TIG )焊接过程中可能出现五类缺陷: 烧穿、污染、未熔合、未保护气体、, 和 high_travel_speed 。

图 1 来自培训数据集的焊接图像示例
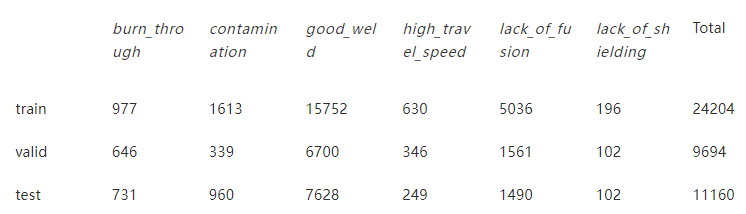
表 1 列车、验证和测试数据集的图像分布
与许多工业数据集一样,该数据集是相当不平衡的,因为很难收集低可能性出现的缺陷的数据。表 1 显示了列车、验证和测试数据集的类别分布。
图 2 显示了测试数据集中的不平衡。测试数据集包含的 good_weld 图像比 lack_of_shielding 多 75 倍。
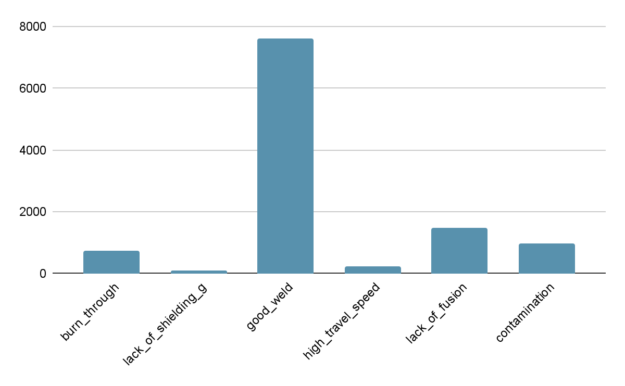
图 2 TIG 钢焊接试验数据集的类别分布 。
使用 NVIDIA TLT
所采用的方法侧重于最小化开发时间和调优时间,同时确保精度适用于生产环境。 TLT 与示例笔记本附带的标准配置文件结合使用。设置、培训和调整在 8 小时内完成。
我们进行了有关网络深度和训练次数的参数扫描。我们观察到,改变默认的学习率并不能改善结果,因此我们没有进一步研究这一点,而是将其保留在默认值。经过 30 个阶段的训练,学习率为 0 。 006 ,从 NGC 目录中获得的预训练 ResNet-18 模型获得了最佳结果。
查看 krygol/304SteelWeldingClassification GitHub repo 中的逐步方法。
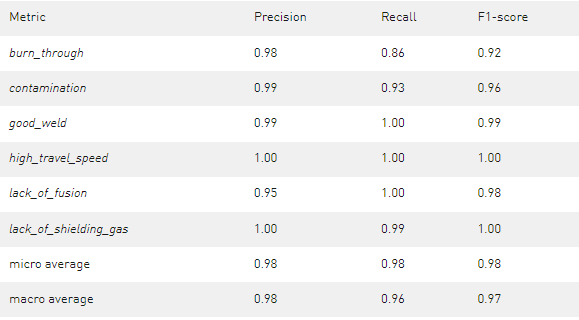
表 2 经过 30 个时期的训练,学习率为 0 。 006 ,预训练的 ResNet-18 获得的结果
获得的结果在所有班级中都相当好。一些 lack_of_fusion 气体图像被错误分类为 burn_through 和 污染 图像。在训练更深层次的 ResNet50 时也观察到了这种效果,这更容易将 lack_of_fusion 误分类为另一个缺陷类。
与原始方法的比较
伯明翰大学的研究人员选择了不同的人工智能工作流。他们手动准备数据集,通过欠采样来减少不平衡。他们还将图像重新缩放到不同的大小,并选择自定义网络结构。
他们使用了一个完全连接的神经网络( Full-con6 ),即具有两个隐藏层的神经网络。他们还实现了一个卷积神经网络( Conv6 ),其中有三个卷积层,每个卷积层后跟一个最大池层和一个完全连接层作为最终隐藏层。他们没有像 ResNet 那样使用跳过连接。
TLT 获得的结果与伯明翰大学研究人员定制实施的结果相比更令人印象深刻。
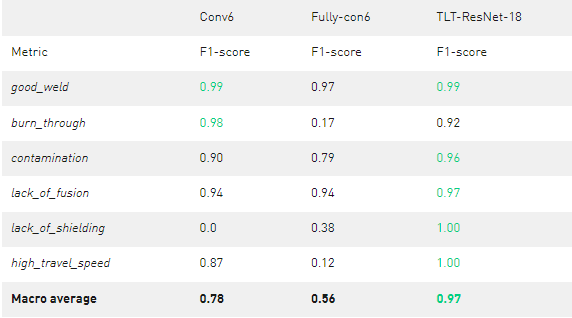
表 3 定制网络与 TLT ResNet-18 的比较
Conv6 的平均表现较好,宏观平均 F1 为 0 。 78 ,但在识别 lack_of_shielding 气体缺陷方面完全失败 。 con6 的平均表现较差,宏观平均 F1 为 0 。 56 。 FULL-con6 可以对一些 lack_of_shielding 气体图像进行分类,但是 burn_through 和 高速行驶 图像存在问题。 FULL-con6 和 Conv6 都有明显的弱点,这将使它们无法获得生产准备就绪的资格。
每个班级的最佳 F1 成绩在表中以绿色标出。如您所见, TLT 训练的 ResNet-18 模型提供了更好的结果,宏观平均值为 0 。 97 。
结论
我们在 TLT 方面有着丰富的经验,总体而言, TLT 是用户友好且有效的。它设置速度快,易于使用,并且在较短的计算时间内产生可接受的结果。根据我们的经验,我们相信 TLT 为不是 AI 专家但希望在生产环境中使用 AI 的工程师提供了巨大的优势。在制造环境中使用 TLT 自动化质量控制不会带来性能成本,应用程序通常可以与默认设置一起使用,并进行一些小的调整,以超越自定义体系结构。
利用 NVIDIA TLT 快速准确地训练人工智能模型的探索表明,人工智能在工业过程中具有巨大的潜力。
关于作者
Konstantin Rygol 是 AI 和 HPC 在波士顿存储和服务器解决方案有限公司的首席工程师。他拥有挪威卑尔根大学的物理硕士学位。在研究原子物理学期间,他对 HPC 和 AI 产生了浓厚的热情。他现在是 NVIDIA 深度学习培训中心的讲师,致力于将人工智能引入德国市场。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5725浏览量
110291 -
服务器
+关注
关注
14文章
10440浏览量
91849 -
AI
+关注
关注
91文章
41976浏览量
303076
发布评论请先 登录
AI Ceph 分布式存储教程资料大模型学习资料2026
HM博学谷狂野AI大模型第四期
AI大模型微调企业项目实战课
AI模型训练与部署实战 | 线下免费培训

NVIDIA 成立由全球领先 AI 实验室组成的 Nemotron Coalition,推动开放前沿模型发展

NVIDIA Jetson模型赋能AI在边缘端落地

NVIDIA推出代理式AI蓝图与电信推理模型
NVIDIA 推出 Nemotron 3 系列开放模型

NVIDIA推动面向数字与物理AI的开源模型发展
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率

NVIDIA Nemotron Nano 2推理模型发布

利用NVIDIA Cosmos模型训练通用机器人




评论