 深入RAPIDS了解处理Cassandra数据的方法
深入RAPIDS了解处理Cassandra数据的方法

组织将其大部分高速事务数据保存在快速的 NoSQL 数据存储中,如 Apache Cassandra ®。最终,需要从这些数据中获得分析见解 。从历史上看,用户利用外部大规模并行处理分析系统(如 Apache Spark )来实现这一目的。然而,今天的分析生态系统正在迅速采用 AI 和 ML 技术,这些技术的计算在很大程度上依赖于 GPU s 。
在这篇文章中,我们探索了一种处理 Cassandra SSTables 的尖端方法,方法是使用 RAPIDS 生态系统中的工具将它们直接解析到 GPU 设备内存中。这将使用户能够以更少的初始设置更快地到达见解 ,并且还可以方便地 MIG 评估用 Python 编写的现有分析代码。
在这篇分为两部分的系列文章的第一篇文章中,我们将快速深入 RAPIDS 项目,并探索一系列选项,使来自卡桑德拉的数据可用于 RAPIDS 分析。最后,我们将描述我们当前的方法:解析 C ++中的 sRebug 文件并将它们转换成 GPU 友好的格式,使数据更容易加载到 GPU 设备内存中。
如果您想跳过循序渐进的过程并立即尝试 sstable to arrow ,请查看第二职位。
什么是 RAPIDS
RAPIDS是一套开源库,用于在 GPU 上进行端到端的分析和数据科学。它源于CUDA,这是一个由 NVIDIA 开发的开发人员工具包,旨在使开发人员能够利用其 GPU 的优势。
RAPIDS 采用了常见的AI/ML API,如pandas和scikit-learn,并使它们可用于 GPU 加速。数据科学,特别是机器学习,使用了大量并行计算,这使得它更适合在 GPU 上运行,该 GPU 可以比当前的 CPU s(来自rapids.ai的图像)高几个数量级的“多任务”:
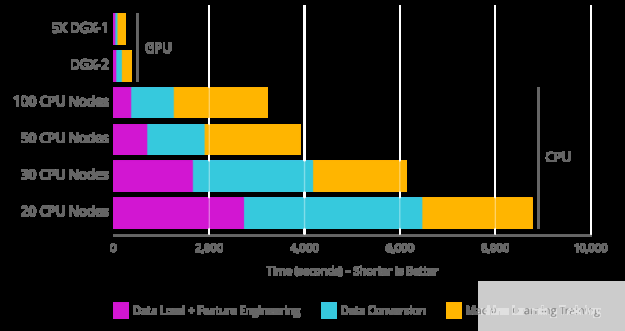
图 1 :
一旦我们以 cuDF 的形式获得 GPU 上的数据(本质上是 pandas 数据帧的 RAPIDS 等价物),我们就可以使用与 MIG 熟悉的 Python 库几乎相同的 API 与之交互,如 pandas 、 scikit learn 等,如下图从 RAPIDS 所示:
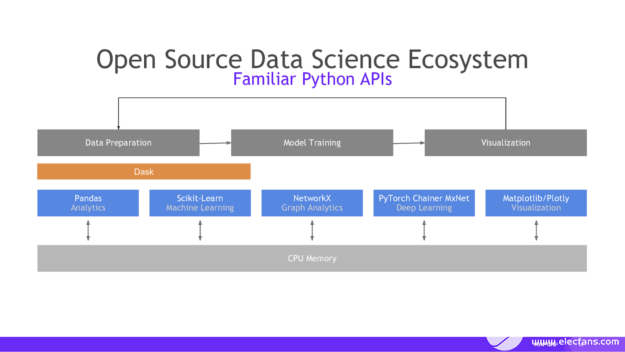
图 2 :
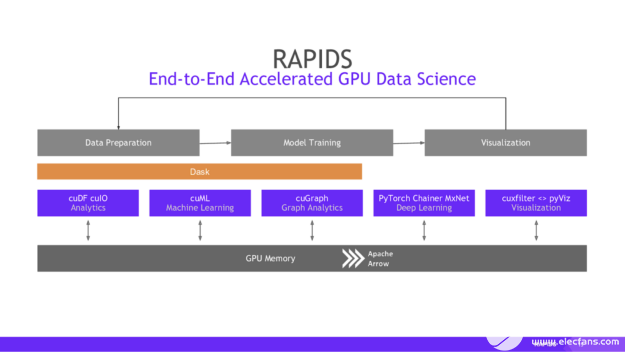
图 3 :
注意使用Apache Arrow作为底层内存格式。箭头是基于列而不是行的,这会导致更快的分析查询。它还带有进程间通信( IPC )机制,用于在进程之间传输箭头记录批(即表)。 IPC 格式与内存中的格式相同,它消除了任何额外的复制或反序列化成本,并为我们提供了一些非常快速的数据访问。
在 RAPIDS 上运行分析的好处是显而易见的。您所需要的只是合适的硬件,只需查找 Python 数据科学库的名称并将其替换为 GPU 等价物,即可 MIG 对 GPU 上运行的现有数据科学代码进行评级。
我们如何将 Cassandra 数据放到 GPU 上?
在过去的几周里,我一直在研究五种不同的方法,按复杂性增加的顺序列出如下:
使用 Cassandra 驱动程序获取数据,将其转换为 pandas 数据帧,然后将其转换为 cuDF 。
与前面相同,但跳过 pandas 步骤,将驱动程序中的数据直接转换为箭头表。
使用 Cassandra 服务器代码从磁盘读取 SSTables ,使用 Arrow IPC 流格式对其进行序列化,然后将其发送到客户端。
与方法 3 相同,但是在 C ++中使用我们自己的解析实现,而不是使用 CasANDRA 代码。
与方法 4 相同,但在解析 SSK 表时使用 GPU 矢量化和CUDA。
首先,我将简要概述这些方法中的每一种,然后在最后进行比较,并解释我们接下来的步骤。
使用 Cassandra 驱动程序获取数据
这种方法非常简单,因为您可以使用现有库而不必进行太多的黑客攻击。我们从驱动程序获取数据,将session.row_factory设置为 pandas _factory函数,告诉驱动程序如何将传入数据转换为 pandas .DataFrame。然后,调用 cuDF .DataFrame.from_ZBK5]函数将数据加载到 GPU 上是一件简单的事情,然后我们可以使用 RAPIDS 库运行 GPU -加速分析。
以下代码要求您能够访问正在运行的 Cassandra 群集。有关更多信息,请参阅DataStax Python 驱动程序文档。您还需要使用Conda安装所需的 Python 库:
BashCopy
conda install -c blazingsql -c rapidsai -c nvidia -c conda-forge -c defaults blazingsql cudf pyarrow pandas numpy cassandra-driver
PythonCopy
from cassandra.cluster import Cluster from cassandra.auth import PlainTextAuthProvider import pandas as pd import pyarrow as pa import cudf from blazingsql import BlazingContext import config # connect to the Cassandra server in the cloud and configure the session settings cloud_config= { 'secure_connect_bundle': '/path/to/secure/connect/bundle.zip' } auth_provider = PlainTextAuthProvider(user=’your_username_here’, password=’your_password_here’) cluster = Cluster(cloud=cloud_config, auth_provider=auth_provider) session = cluster.connect() def pandas_factory(colnames, rows): """Read the data returned by the driver into a pandas DataFrame""" return pd.DataFrame(rows, columns=colnames) session.row_factory = pandas_factory # run the CQL query and get the data result_set = session.execute("select * from your_keyspace.your_table_name limit 100;") df = result_set._current_rows # a pandas dataframe with the information gpu_df = cudf.DataFrame.from_pandas(df) # transform it into memory on the GPU # do GPU-accelerated operations, such as SQL queries with blazingsql bc = BlazingContext() bc.create_table("gpu_table", gpu_df) bc.describe_table("gpu_table") result = bc.sql("SELECT * FROM gpu_table") print(result)
使用 Cassandra 驱动程序直接将数据提取到 Arrow 中
此步骤与上一步相同,只是我们可以使用以下箭头关闭 pandas \ u 工厂:
PythonCopy
def get_col(col):
rtn = pa.array(col) # automatically detects the type of the array
# for a full implementation, we would want to fully check which
arrow types want
# to be manually casted for compatibility with cudf
if pa.types.is_decimal(rtn.type):
return rtn.cast('float32')
return rtn
def arrow_factory(colnames, rows):
# convert from the row format passed by
# CQL into the column format of arrow
cols = [get_col(col) for col in zip(*rows)]
table = pa.table({ colnames[i]: cols[i] for i in
range(len(colnames)) })
return table
session.row_factory = arrow_factory
然后我们可以用同样的方法获取数据并创建 cuDF 。
然而,这两种方法都有一个主要缺点:它们依赖于查询现有的 Cassandra 集群,这是我们don’t所需要的,因为读取量大的分析工作负载 MIG ht 会影响事务性生产工作负载,而实时性能是关键。
相反,我们想看看是否有一种方法可以直接从磁盘上的 SSTable 文件中获取数据,而无需通过数据库。这就引出了接下来的三种方法。
使用 Cassandra 服务器代码从磁盘读取 SSTables
在磁盘上读取 SSTables 的最简单方法可能是使用现有的 Cassandra 服务器技术,即SSTableLoader。一旦我们从 SSTable 中获得了分区列表,我们就可以手动将 Java 对象中的数据转换为对应于表列的箭头向量。然后,我们可以将向量集合序列化为 Arrow IPC 流格式,然后通过套接字以这种格式进行流处理。
这里的代码比前两种方法更复杂,比下一种方法开发得更少,所以我没有在本文中包含它。另一个缺点是,尽管这种方法可以在 Cassandra 集群以外的单独进程或机器中运行,但要使用SSTableLoader,我们首先要在客户端进程中初始化嵌入式 Cassandra ,这在冷启动时需要相当长的时间。
使用自定义 SSTable 解析器
为了避免初始化 CasANDRA ,我们开发了自己的 C ++实现,用于解析二进制数据稳定文件。关于这种方法的更多信息可以在下一篇博文中找到。下面是 Cassandra 存储引擎的指南上一篇 Pickle 的文章,这对破译数据格式有很大帮助。我们决定使用 C ++作为解析器的语言,以最终引入 CUDA ,也可以用于处理二进制数据的低级控制。
集成 CUDA 以加快表读取速度
一旦自定义解析实现变得更加全面,我们计划开始研究这种方法。利用 GPU 矢量化可以大大加快读取和转换过程。
Comparison
在当前阶段,我们主要关注读取 SSTable 文件所需的时间。对于方法 1 和 2 ,我们实际上无法公平地衡量这一次,因为 1 )该方法依赖于额外的硬件( Cassandra 集群)和 2 )。在 Cassandra 自身中存在着复杂的缓存效应。然而,对于方法 3 和 4 ,我们可以执行简单的自省来跟踪程序从开始到结束读取 SSTable 文件所需的时间。
以下是针对NoSQLBench生成的 1k 、 5K 、 10k 、 50k 、 100k 、 500k 和 1m 行数据集的结果:
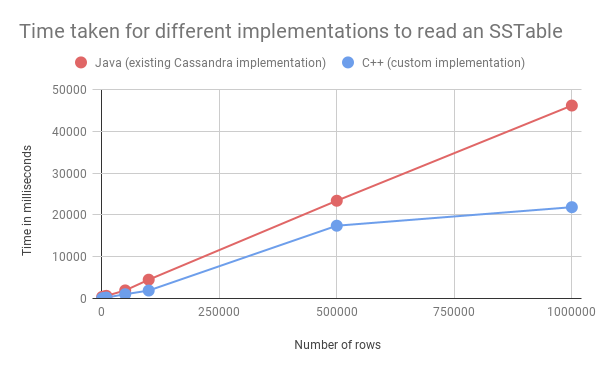
图 4 :
如图所示,定制实现比现有的 Cassandra 实现稍快,即使没有任何额外的优化,如多线程。
Conclusion
考虑到分析用例的数据访问模式通常包括大型扫描并经常读取整个表,获取此数据的最有效方法不是通过 CQL ,而是直接获取 SSL 表。我们能够在 C ++中实现一个 StAnalyd 解析器,它可以做到这一点,并将数据转换成 Apache 箭头,以便它可以被分析库所利用,包括 NVIDIA GPU 供电 RAPIDS 生态系统。由此产生的开源( Apache 2 许可)项目称为 sstable to arrow ,可在GitHub上获得,并可通过Docker Hub作为 alpha 版本访问。
关于作者
Alex Cai 于 2021 年在 DataStax 实习,是哈佛大学 2025 级的学生。他热衷于计算机、软件和认知科学,在业余时间,他喜欢阅读、研究语言学和玩他的猫。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5682浏览量
110102 -
gpu
+关注
关注
28文章
5266浏览量
136042 -
C++
+关注
关注
22文章
2127浏览量
77358
发布评论请先 登录
深入剖析CP3CN17可重编程连接处理器
深入剖析STA2065:高性能信息娱乐应用处理器
深入了解S124 MCU:特性、参数与应用考量
深入了解BASIC Stamp:架构、指令与应用全解析
深入解析MCF5271集成微处理器硬件特性与设计要点
深入剖析MCF5253 ColdFire微处理器:特性、参数与应用解析
云端数据高效处理:方法与系统全解析

深入了解Maxim产品命名规则
深入了解LTC1091/LTC1092/LTC1093/LTC1094数据采集系统
深入剖析ADuC834:高精度数据采集与处理的理想之选
深入剖析ADSP - 2136x SHARC处理器:高性能音频处理的理想之选
变频器逆变模块损坏的起因及处理方法
pcm设备故障及处理方法

NVIDIA RAPIDS 25.06版本新增多项功能
谐波怎么处理最简单的方法



评论