 扩散模型在视频领域表现如何?
扩散模型在视频领域表现如何?

扩散模型正在不断的「攻城略地」。
扩散模型并不是一个崭新的概念,早在2015年就已经被提出。其核心应用领域包括音频建模、语音合成、时间序列预测、降噪等。
那么它在视频领域表现如何?先前关于视频生成的工作通常采用诸如GAN、VAE、基于流的模型。
在视频生成领域,研究的一个重要里程碑是生成时间相干的高保真视频。来自谷歌的研究者通过提出一个视频生成扩散模型来实现这一里程碑,显示出非常有希望的初步结果。本文所提出的模型是标准图像扩散架构的自然扩展,它可以从图像和视频数据中进行联合训练,研究发现这可以减少小批量梯度的方差并加快优化速度。
为了生成更长和更高分辨率的视频,该研究引入了一种新的用于空间和时间视频扩展的条件采样技术,该技术比以前提出的方法表现更好。

论文地址:https://arxiv.org/pdf/2204.03458.pdf
论文主页:https://video-diffusion.github.io/
研究展示了文本条件视频生成的结果和无条件视频生成基准的最新结果。例如生成五彩斑斓的烟花:

其他生成结果展示:

这项研究有哪些亮点呢?首先谷歌展示了使用扩散模型生成视频的首个结果,包括无条件和有条件设置。先前关于视频生成的工作通常采用其他类型的生成模型,如 GAN、VAE、基于流的模型和自回归模型。
其次该研究表明,可以通过高斯扩散模型的标准公式来生成高质量的视频,除了直接的架构更改以适应深度学习加速器的内存限制外,几乎不需要其他修改。该研究训练生成固定数量的视频帧块的模型,并且为了生成比该帧数更长的视频,他们还展示了如何重新调整训练模型的用途,使其充当对帧进行块自回归的模型。
方法介绍
图像扩散模型中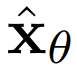 的标准架构是U-Net,它是一种被构造为空间下采样通道的神经网络架构,空间上采样通道紧随其后,其中残差连接到下采样通道激活。这种神经网络由2D卷积残差块的层构建而成,并且每个这种卷积块的后面是空间注意力块。
的标准架构是U-Net,它是一种被构造为空间下采样通道的神经网络架构,空间上采样通道紧随其后,其中残差连接到下采样通道激活。这种神经网络由2D卷积残差块的层构建而成,并且每个这种卷积块的后面是空间注意力块。
研究者建议将这一图像扩散模型架构扩展至视频数据,给定了固定数量帧的块,并且使用了在空间和时间上分解的特定类型的 3D U-Net。
首先,研究者通过将每个 2D卷积改成space-only 3D卷积对图像模型架构进行修改,比如将每个3x3卷积改成了1x3x3卷积,即第一个轴(axis)索引视频帧,第二和第三个索引空间高度和宽度。每个空间注意力块中的注意力仍然为空间上的注意力,也即第一个轴被视为批处理轴(batch axis)。
其次,在每个空间注意力块之后,研究者插入一个时间注意力块,它在第一个轴上执行注意力并将空间轴视为批处理轴。他们在每个时间注意力块中使用相对位置嵌入,如此网络不需要绝对视频时间概念即可区分帧的顺序。3D U-Net 的模型架构可视图如下所示。
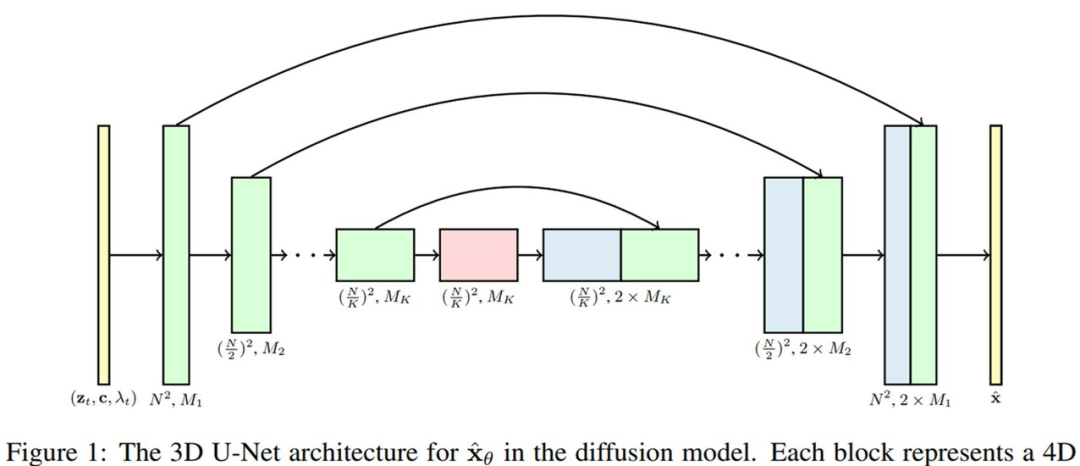
我们都知道,得益于分解时空注意力的计算效率,在视频transformers中使用它是一个很好的选择。研究者使用的分解时空架构是自身视频生成设置独有的,它的一大优势是可以直接 mask 模型以在独立图像而非视频上运行,其中只需删除每个时间注意力块内部的注意力操作并修复注意力矩阵以在每个视频时间步精确匹配每个键和问询向量。
这样做的好处是允许联合训练视频和图像生成的模型。研究者在实验中发现,这种联合训练对样本质量非常重要。
新颖的条件生成梯度方法
研究者的主要创新是设计了一种新的、用于无条件扩散模型的条件生成方法,称之为梯度方法,它修改了模型的采样过程以使用基于梯度的优化来改进去噪数据上的条件损失。他们发现,梯度方法比现有方法更能确保生成样本与条件信息的一致性。
研究者使用该梯度方法将自己的模型自回归地扩展至更多的时间步和更高的分辨率。
下图左为利用梯度方法的视频帧,图右为利用自回归扩展基线替代(replacement)方法的帧。可以看到,使用梯度方法采用的视频比基线方法具有更好的时间相干性。

实验结果
研究者对无条件、文本-条件视频生成模型进行了评估。文本-条件视频生成是在一个包含 1000 万个字幕视频数据集上进行训练,视频空间分辨率为 64x64 ;对于无条件视频生成,该研究在现有基准 [36] 上训练和评估模型。
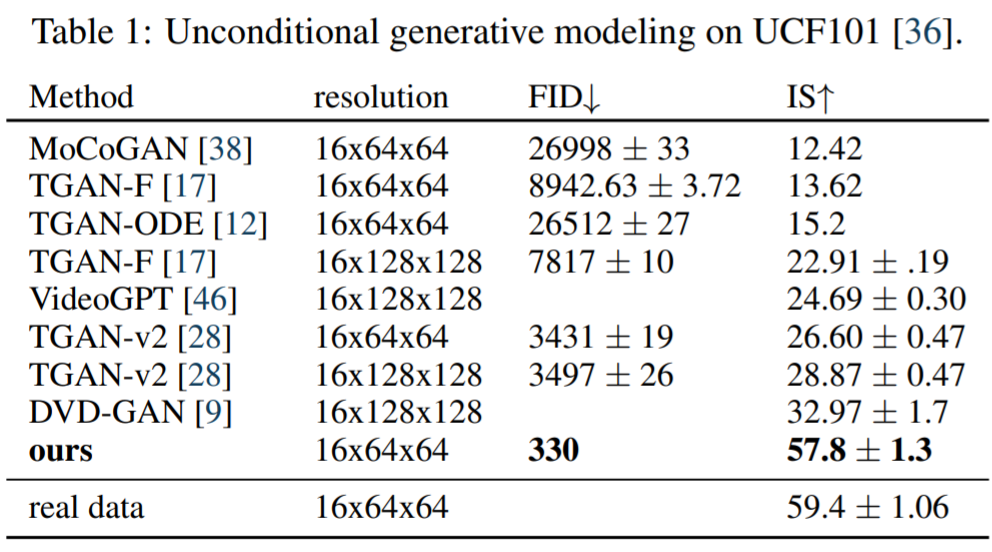
无条件视频建模该研究使用 Soomro 等人[36]提出的基准对无条件视频生成模型进行评估。表 1 展示了该研究所提模型生成的视频的感知质量得分,并与文献中的方法进行了比较,发现本文方法大大提高了SOTA。
视频、图像模型联合训练:表 2 报告了针对文本-条件的 16x64x64 视频的实验结果。

无分类器指导的效果:表3 表明无分类器指导 [13] 在文本-视频生成方面的有效性。正如预期的那样,随着指导权重的增加,类 Inception Score 的指标有明显的改进,而类 FID 的指标随着引导权重的增加先改善然后下降。
表 3 报告的结果验证了无分类器指导 [13] 在文本-视频生成方面的有效性。正如预期的那样,随着引导权重的增加,类 Inception Score (IS)的指标有明显的改进,而类 FID 的指标随着引导权重的增加先改善然后下降。这一现象在文本-图像生成方面也有类似的发现[23]。
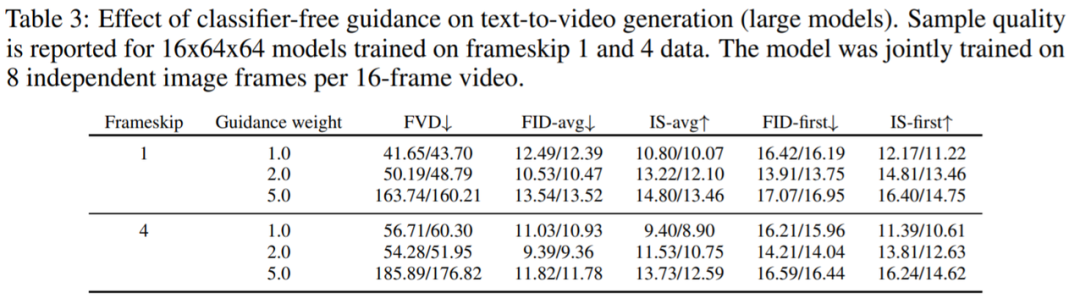
图 3 显示了无分类器指导 [13] 对文本-条件视频模型的影响。与在文本条件图像生成 [23] 和类条件图像生成 [13, 11] 上使用无分类器指导的其他工作中观察到的类似,添加指导提高了每个图像的样本保真度。

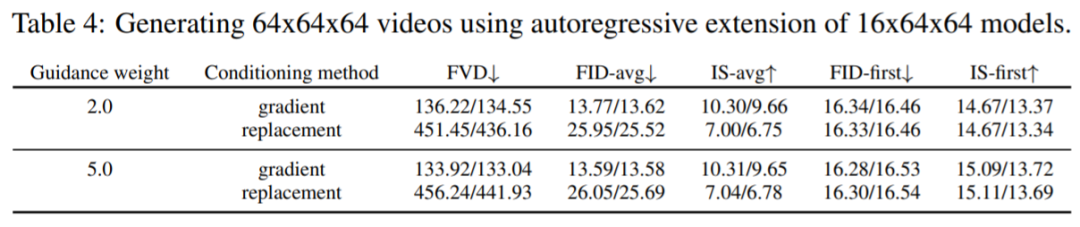
针对较长序列的自回归视频扩展:3.1节提出了基于扩散模型的条件采样梯度法,这是对[35]中替换方法的改进。表4展示了使用这两种技术生成较长视频的结果,由结果可得本文提出的方法在感知质量分数方面确实优于替换方法。
审核编辑 :李倩
-
视频
+关注
关注
6文章
2017浏览量
75235 -
GaN
+关注
关注
21文章
2391浏览量
84921 -
模型
+关注
关注
1文章
3873浏览量
52337
原文标题:视频生成无需GAN、VAE,谷歌用扩散模型联合训练视频、图像,实现新SOTA
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
联影智能发布、开源医疗视频理解大模型 邀全球开发者共探技术上限
AI大模型微调企业项目实战课
Firefly-RK1828 赋能视频大模型:多目标+全场景,引领智能分析新风向

杭晶电子差分晶振产品在视频领域的应用

探索RISC-V在机器人领域的潜力
AI视频分析在化工领域的应用和开发
百度重磅发布!全球首创中文音视频模型
一种基于扩散模型的视频生成框架RoboTransfer




评论