 如何实现高效的部署医疗影像推理
如何实现高效的部署医疗影像推理

一个完整的医疗影像推理流程一般包含数据的前处理、AI 推理以及数据后处理这几部分。通常情况下,我们可以通过 TensorRT, TensorFlow 或者 PyTorch 这些框架来实现 GPU 加速的 AI 推理部分,然而数据前后处理部分往往是放在 CPU 上执行的。对于一些比较大的数据,比如 CT 或者 MR 这种 3D 图像,CPU 上的数据前后处理会成为整个推理流程的瓶颈,导致推理的时延变长,GPU 使用效率不高。医疗影像推理的另一个需要考虑的问题是如何实现高效的部署。我们往往需要部署多个医疗影像 AI 应用,那么如何去调度多个模型,如何并发处理多个请求,并充分利用 GPU 资源成为挑战。
什么是 MONAI
MONAI 是一个专门针对医疗图像的深度学习开源框架。MONAI 致力于:
-
发展一个学术界、工业界和临床研究人员共同合作的社区;
-
为医疗图像创建最先进的端到端工作流;
-
为研究人员提供创建和评估深度学习模型的优化和标准化的方法。
MONAI 中包含一系列的 transforms 对医疗图像数据进行前后处理。在 MONAI 0.7 中,我们在 transforms 中引入基于 PyTorch Tensor 的计算,许多 transforms 既支持 NumPy array,也支持 PyTorch Tensor 作为输入类型和计算后端。当以 PyTorch Tensor 作为输入数据时,我们可以使用 GPU 来加速数据前后处理的计算。
什么是 NVIDIA Triton 推理服务器
Triton 推理服务器是一个开源的 AI 模型部署软件,可以简化深度学习推理的大规模部署。它能够对多种框架(TensorFlow、TensorRT、PyTorch、ONNX Runtime 或自定义框架),在任何基于 GPU 或 CPU 的环境上(云、数据中心、边缘)大规模部署经过训练的 AI 模型。Triton 可提供高吞吐量推理,以实现 GPU 使用率的最大化。
在较新的版本中,Triton 增加了 Python backend 这一新特性,Python backend 的目标是让使用者可以更加容易的部署 Python 写的模型,无需再去编写任何 C++ 代码。在一些场景下,我们的推理流程中可能会出现循环、条件判断、依赖于运行时数据的控制流和其他自定义逻辑与模型混合执行。使用 Triton Python backend,开发人员可以更加容易地在自己的推理流程中实现这些控制流,并且在 Python 模型中调用 Triton 部署的其他模型。
使用 MONAI 和 Triton 高效搭建和部署 GPU 加速的医疗影像推理流程
在本文介绍的例子中,我们将使用 MONAI 中 GPU 加速的数据处理以及 Triton 的 Python backend 来构建一个 GPU 加速的医疗影像推理流程。通过这个例子,读者可以了解到,在 GPU 上进行数据处理所带来的性能增益,以及如何使用 Triton 进行高效的推理部署。
整个推理流程如下图所示,包含数据预处理,AI 模型推理,和数据后处理三部分。
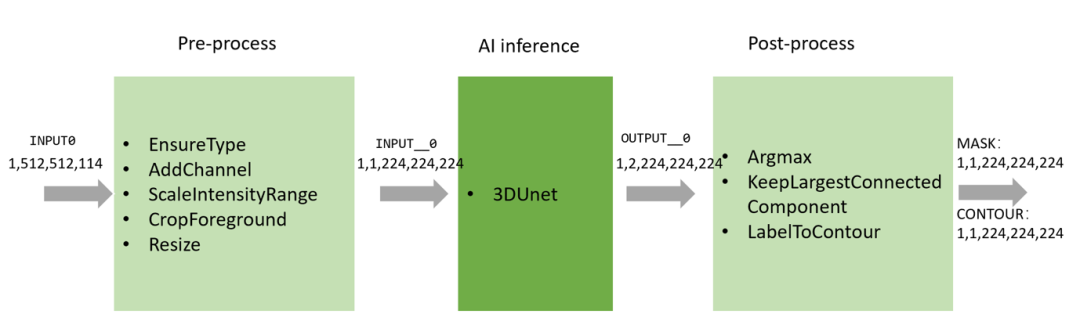
通过 EnsureType 这个 transform,我们将输入数据转换成 PyTorch Tensor 并放到 GPU 上,这样之后的数据预处理操作都会在 GPU 上进行。我们使用 Triton 的 Torch backend 来作为 3DUnet 的推理后端,输出的结果为 GPU 上的 Torch Tensor,并作为后处理模块的输入,在 GPU 上进行后处理计算。
使用 Triton 的 Python backend,我们可以非常容易的将整个流程串联起来,即:按照 Triton Python backend 要求的模型结构构建前后处理的 Python 代码,并在其中调用 3DUnet 的推理。以下是我们例子中的代码片段。完整的代码及复现步骤请见 Github:
https://github.com/Project-MONAI/tutorials/tree/master/full_gpu_inference_pipeline
class TritonPythonModel:"""Your Python model must use the same class name. Every Python modelthat is created must have "TritonPythonModel" as the class name."""def initialize(self, args):"""`initialize` is called only once when the model is being loaded.Implementing `initialize` function is optional. This function allowsthe model to intialize any state associated with this model."""self.inference_device_id = args.get("model_instance_device_id", "0")infer_transforms = []infer_transforms.append(EnsureType(device=torch.device(f"cuda:{self.inference_device_id}")))infer_transforms.append(AddChannel())infer_transforms.append(ScaleIntensityRange(a_min=-57, a_max=164, b_min=0.0, b_max=1.0, clip=True))infer_transforms.append(CropForeground())infer_transforms.append(Resize(spatial_size=(224, 224, 224)))self.pre_transforms = Compose(infer_transforms)def execute(self, requests):"""`execute` must be implemented in every Python model. `execute`function receives a list of pb_utils.InferenceRequest as the onlyargument. This function is called when an inference is requestedfor this model. Depending on the batching configuration (e.g. DynamicBatching) used, `requests` may contain multiple requests. EveryPython model, must create one pb_utils.InferenceResponse for everypb_utils.InferenceRequest in `requests`. If there is an error, you canset the error argument when creating a pb_utils.InferenceResponse."""responses = []for request in requests:# get the input by name (as configured in config.pbtxt)input_triton_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT0")# convert the triton tensor to torch tensorinput_torch_tensor = from_dlpack(input_triton_tensor.to_dlpack())transform_output = self.pre_transforms(input_torch_tensor[0])transform_output_batched = transform_output.unsqueeze(0)# convert the torch tensor to triton tensortransform_tensor = pb_utils.Tensor.from_dlpack("INPUT__0", to_dlpack(transform_output_batched))# send inference request to 3DUnet served by Triton. The name of the model is "segmentation_3d"inference_request = pb_utils.InferenceRequest(model_name="3dunet", requested_output_names=["OUTPUT__0"], inputs=[transform_tensor])infer_response = inference_request.exec()output1 = pb_utils.get_output_tensor_by_name(infer_response, "OUTPUT__0")# convert the triton tensor to torch tensoroutput_tensor = from_dlpack(output1.to_dlpack())# do the post processargmax = AsDiscrete(argmax=True)(output_tensor[0])largest = KeepLargestConnectedComponent(applied_labels=1)(argmax)contour = LabelToContour()(largest)out_tensor_0 = pb_utils.Tensor.from_dlpack("MASK", to_dlpack(largest.unsqueeze(0)))out_tensor_1 = pb_utils.Tensor.from_dlpack("CONTOUR", to_dlpack(contour.unsqueeze(0)))inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor_0, out_tensor_1])responses.append(inference_response)return responsesdef finalize(self):"""`finalize` is called only once when the model is being unloaded.Implementing `finalize` function is optional. This function allowsthe model to perform any necessary clean ups before exit."""pass
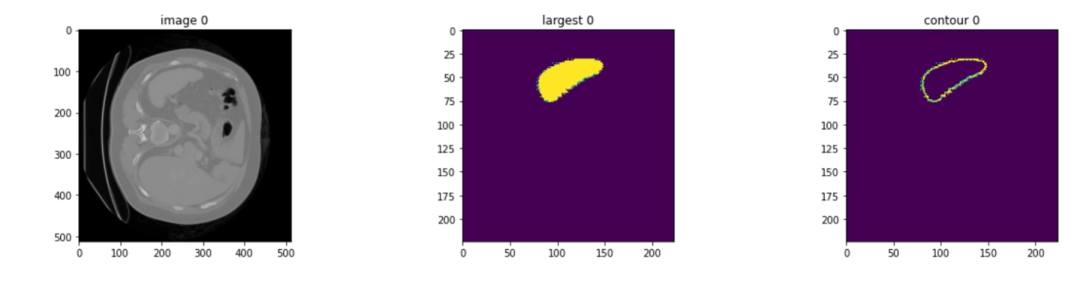
以 MSD Spleen 3D 数据作为输入,经过整个推理流程,将得到分割后的脾脏区域以及其轮廓。
性能测试
我们在 RTX 8000 上对整个推理流程进行了性能测试,以了解 Triton 及 MONAI 不同特性对性能的影响。
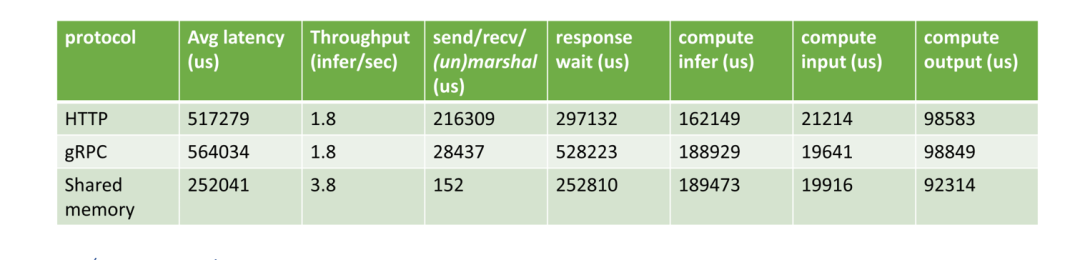
HTTP vs. gRPC vs. shared memory
目前 Triton 支持 HTTP, gRPC 和共享内存等方式进行数据通信。由于三维医学图像通常很大,通信带来的开销不容忽视。对于许多常见的医学图像人工智能应用,客户端与服务器位于同一台机器上,因此使用共享内存是减少发送/接收开销的一种可行方法。在测试中,我们比较了客户端和服务器之间使用不同通信方式对性能的影响。所有过程(前/后处理和AI推理)都在 GPU 上。我们可以得出结论,当数据传输量很大时,使用共享内存将大大减少延迟。
Pre/Post-processing on GPU vs. CPU
接着我们测试了分别在 GPU 和 CPU 进行前后数据处理时,整个推理流程的速度。可以看到,当使用 GPU 进行数据处理时,可以实现 12 倍的加速。

想要了解更多 Triton 和 MONAI 的特性与使用方法,请关注以下链接。同时,Triton 和 MONAI 均已在 Github 开源,欢迎开发者踊跃参与开源社区建设。
原文标题:使用 MONAI 和 Triton 高效构建和部署 GPU 加速的医疗影像推理流程
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
NVIDIA
+关注
关注
14文章
5682浏览量
110110 -
gpu
+关注
关注
28文章
5268浏览量
136058 -
医疗
+关注
关注
8文章
2026浏览量
61778
原文标题:使用 MONAI 和 Triton 高效构建和部署 GPU 加速的医疗影像推理流程
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
索尼医疗影像重磅亮相CMEF 2026
K8s部署vLLM推理服务详细步骤
腾龙MP3010M-EV与CM2001S:重塑医疗影像的精准与高效
超清视界,智联未来:索尼FCB-EV9500L与CM2002V重塑医疗影像新范式
如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务

4K影像赋能精准医疗:索尼FCB-CS8230与SDI编码板的协同创新之路
NVIDIA TensorRT LLM 1.0推理框架正式上线
微型导轨在医疗影像设备的精准导航

基于米尔瑞芯微RK3576开发板部署运行TinyMaix:超轻量级推理框架
让老旧医疗设备“听懂”新语言:CAN转EtherCAT的医疗行业应用
如何在魔搭社区使用TensorRT-LLM加速优化Qwen3系列模型推理部署
Say Hi to ERNIE!Imagination GPU率先完成文心大模型的端侧部署

从内窥镜到阅片中心:AI一体机如何重塑医疗影像全链路



评论