 如何检查相互竞争的模型并通过GPU获得成功
如何检查相互竞争的模型并通过GPU获得成功

数据科学家和机器学习工程师经常面临“与 深度学习 相比使用 机器学习 分类器解决其业务问题”的困境。根据数据集的性质,一些数据科学家更喜欢经典的机器学习方法。其他人采用最新的深度学习模式,而还有人追求“集成”模式,希望在可解释性和性能这两个方面都达到最佳。
机器学习,特别是决策树,导致了更先进的 XGBoost 模型,比深度学习成熟得更早,并且有一些成熟的方法。深度学习在非表格计算机视觉、语言和语音识别领域表现出色。无论您选择哪一种, GPU 都在加速数据科学用例,使其达到这样的程度:对大型数据集的任何数据分析都只需要它们来满足每天的便利性、快速迭代和结果。
RAPIDS 通过类似于 scikit-learn 和 pandas 等收藏夹的界面,使数据科学家更容易利用 GPU 。这里,我们使用的是一个表格数据集。经典的提取 – 转换 – 加载过程( ETL )是任何数据科学项目的核心起点。
对于GPU加速用例,NVIDIA NVTabular 应用框架 推荐系统 使用 NVTabular -加速特征工程、预处理和数据加载库,也可用于其他领域,如金融服务。
在本文中,我们将演示如何检查相互竞争的模型(称为 challenger models ),并使用 GPU 加速,通过简单、经济高效且可理解的模型可解释性应用程序获得成功。当 GPU 加速在模型开发过程中被多次使用时,建模者的时间将通过在数十次模型迭代中摊销培训时间和降低成本而得到更有效的利用。
我们是在使用 公共房利美抵押贷款数据集 预测抵押贷款拖欠的情况下这样做的。我们还展示了用于模型训练的 NVTabular 数据加载器获得的简单加速比。同样的例子也可以扩展到信用承销、信用卡拖欠或其他一系列重要的分类问题。
所有金融信用风险建模中的一个共同主题是对预期损失的关注。无论交易是一方欠另一方一定金额的两个交易对手之间的交易协议,还是借款人欠贷款人每月还款金额的贷款协议,我们都可以通过以下方式查看预期损失 EL :
EL = PD x LGD x EAD
哪里:
PD :违约概率,考虑到人口中的所有贷款
LGD :违约造成的损失;介于 0 和 1 之间的值,用于测量未付贷款的百分比
EAD :违约风险敞口,即剩余未偿余额
PD 和 EL 附加到一个时间段,该时间段通常可以设置为每年或每月,具体取决于发放贷款的公司的选择。
在我们的案例中,我们的目标是根据个人贷款的特征预测最有可能拖欠的具体个人贷款。因此,我们主要关注影响 PD 利率的贷款,也就是说,将有预期损失的贷款与无预期损失的贷款分开。
机器学习与深度学习方法
机器学习( ML )和深度学习( DL )已经发展成为分析预测的合作和竞争方法。考虑两种方法并权衡每个模型的结果,或者使用集成多个方法来获得给定应用的两个世界,这是最好的实践。这两种方法都可以从数据中提取深刻、复杂的见解,帮助决策。
在许多情况下,与传统回归模型相比,使用更高级的 ML 模型可以提供真正的业务价值。然而,使用更先进的模型解释特定决策的驱动因素可能很困难、耗时,而且使用传统的基础设施成本高昂。模型运行时间与解释预测的解释步骤的运行时间同样重要。
为了对结果充满信心,我们希望解决对可解释性的新需求。现有技术速度慢,计算成本高,是 GPU 加速的理想选择。通过转向 GPU 加速建模和解释,团队可以改进处理、准确性和解释性,并在业务需要时提供结果。
抵押贷款风险预测
从消费者角度来看,违约风险可能会影响我们个人,也可能会影响发行方。今天,在许多国家,为基础设施改善项目发放了大量贷款。例如,一条大型公路 桥 可能需要超过 10 亿美元的债务融资。显然,为数十亿美元的巨额项目融资会带来违约风险。
衡量违约概率很重要,因为管理机构的公民当然不希望看到该债券违约。英格兰银行的一篇题为 金融学中的机器学习可解释性:在违约风险分析中的应用 的论文为当前的工作提供了灵感,该工作的重点是住房抵押贷款。
在英格兰银行的文件中很容易看到这种解释透明的好处。作者称他们的方法为定量输入影响( QII ), QII 用于线性逻辑和梯度增强树机器学习预测模型。问题是:哪些因素对违约的影响最大?
作者解释了这些解释的直觉力量。他们还进行观察,这是金融建模从业者应该注意的。本文通过精确召回曲线结果,展示了为默认预测设计足够的精确性、精确性和召回率的能力。
模型可解释性可能是与思想领袖、管理层、外部审计师和监管者讨论的重要组成部分。[VZX38 ]使用[VZX39 ]计算,其中数据集由英国的六百万个贷款组成,具有大约2.5%的违约率。
正如 NVIDIA 作者在最近的文章中所描述的,违约风险是资本市场、银行业和保险业中非常常见的债务用例。例如,信用衍生工具是一种对违约可能性进行投机的方式,通过分期付款和离家较近的方式进行投机。抵押贷款贷款者对他们是否能及时得到偿还深感兴趣。
归根结底,保险合同是从客户的角度覆盖洪水、盗窃或死亡相关风险的方式。从贷款人或保险承保的角度来看,预测这些事件对其业务的盈利能力至关重要。借助著名的美国房利美公共抵押贷款数据集,我们能够使用 GPU ML 和 DL 模型的加速训练,检查风险方法和样本外精确度、召回率。
本文的重点是 ML 和 DL 模型的细微差别以及可解释性的方法。如果发生逾期 90 天的贷款事件,贷款公司就会产生担忧。由于重置成本,违约概率令人担忧。本文的一个关键结果是,当 GPU 加速应用于本 GPUTreeShap paper 中所述的算法时,计算 Shap 值的速度提高了 29 倍。
我们预测美国房利美抵押贷款数据集违约的 Python 程序将使用 GPU 加速框架 RAPIDS 。 RAPIDS 为数据帧操作提供类似于 Python pandas 的应用程序接口( API )。本手册提供的抵押贷款数据集非常方便 RAPIDS 抵押数据链路 拥有近二十年的贷款业绩数据,记录了实际利率、借款人特征和贷款人名称。我们的抵押贷款表格数据集存在一个经典的 imbalanced class 预测问题,因为只有大约 4% 的贷款拖欠。
分类列的因式分解
因子是编程语言中的一个重要概念。熟悉 R 语言进行统计计算的读者了解使用 factor() 函数创建的因子,作为将列分类为离散值集的一种方法。 R 、 事实上,默认情况下是对列进行因式分解,可以根据输入进行因式分解,因此用户通常应该覆盖read.csv()带有 wordy 参数的选项stringsAsFactors=FALSEPython pandas 和 RAPIDS 软件包包含非常相似的factorize()本 article 中提到的方法。对于我们的抵押贷款数据集,邮政编码是一个需要分解的经典列。
df[‘Zip’], Zip = df[‘Zip’].factorize()
一系列转换语句是一个热编码列的替代方案,减少了转换数据所需的稀疏性和内存。与使用单一热编码相比,因子分解的优势在于,数据帧不需要随着列值数量的增加而变宽,但我们仍然具有分类列变量的优势。
XGBoost 分类器调整
当使用决策树时,可以获得特征重要性的好处。特性重要性报告有助于解释决策中最常用的特性。如图 1 所示的特征重要性报告是推动决策树成为流行分类方法的工件之一。决策树节点对应于一组训练数据集行。最初,我们从一个节点开始表示所有训练行。节点纯度指的是数据集行相似。当我们开始决策树训练过程时,节点杂质更为常见,当我们在扫描数据集时扩展树时,纯度变得更为常见。特征重要性列在 减少节点杂质 中,根据到达该节点的机会进行加权。最有效的节点是那些导致杂质最佳减少的节点,同时也代表数据总体中样本数量最多的节点。
对于决策树(如 XGBoost 分类器),当决策树通过从初始单个节点到数百个节点的拆分进行扩展时,当发生拆分以获得准确性时,不需要节点杂质。我们将很快讨论更多关于可解释性的问题。
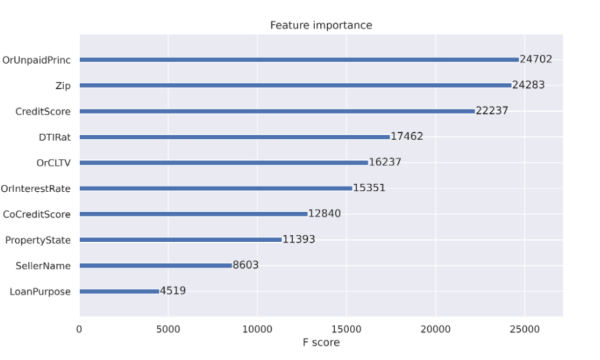
图 1 : XGBoost 分类器报告的特征重要性。要素的列名列在打印之前。
XGBoost 分类器作为 Python Jupyter 笔记本的一部分进行了调整,以检查贷款拖欠的可预测性。这项工作的灵感来自于 逐条降级 。我们在前一篇文章中重点介绍了 XGBoost 分类器,并且能够报告通过因子分解在精确度和召回率方面的改进。给定一个包含刺激变量和默认输出变量的数据集,数据行的可预测性受到限制。我们在图 2 中的结果来自 2007 年至 2012 年期间 1120 万份个人抵押贷款,测试集中有 110 万份贷款。与使用标准值 0.5 相比,对发出的违约概率使用自定义阈值有助于平衡精确度和召回率。我们将在下面用最佳参数显示代码序列。
samples/tree/main/credit_default_risk上找到,以及有关如何下载抵押贷款数据集的说明。
params = { 'num_rounds': 100, 'max_depth': 12, 'max_leaves': 0, 'alpha': 3, 'lambda': 1, 'eta': 0.17, 'subsample': 1, 'sampling_method': 'gradient_based', 'scale_pos_weight': scaling, # num_negative_samples/num_positive_samples 'max_delta_step': 1, 'max_bin': 2048, 'tree_method': 'gpu_hist', 'grow_policy': 'lossguide', 'n_gpus': 1, 'objective': 'binary:logistic', 'eval_metric': 'aucpr', 'predictor': 'gpu_predictor', 'num_parallel_tree': 1, "min_child_weight": 2, 'verbose': True } if use_cpu: print('training XGBoost model on cpu') params['tree_method'] = 'hist' params['sampling_method'] = 'uniform' params['predictor'] = 'cpu_predictor' dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test) evals = [(dtest, 'test'), (dtrain, 'train')] model = xgb.train(params, dtrain, params['num_rounds'], evals=evals, early_stopping_rounds=10)
我们可以在前面看到, XGBoost 培训步骤的目标是binary:logistic评估指标是精确性和召回率曲线下的面积,称为aucpr. 训练模型后,在训练集上计算对应于最大 F1 分数的阈值。该阈值应用于测试集上的预测,结果如图 2 所示,并在图 3 的精度召回曲线中显示为红点。
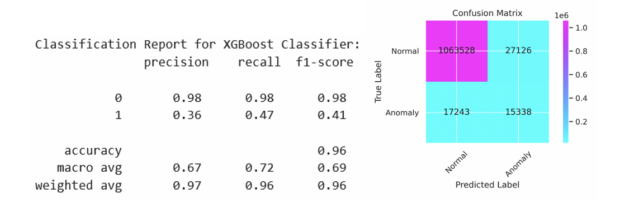
图 2 :针对 1120 万套抵押贷款记录培训和测试集,报告精度和召回测试集。测试集中包括 110 万笔贷款。
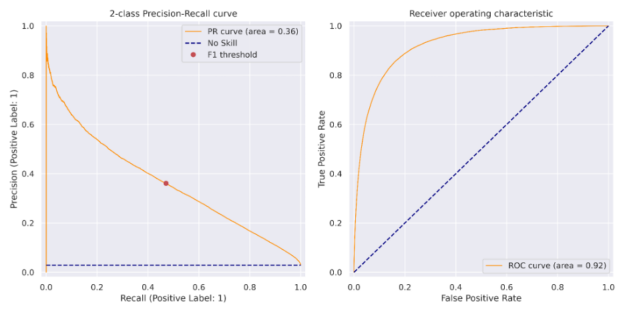
图 3:XGBoost 机器学习精度召回曲线(左)和接收器工作特性曲线(右)反映了数据集的不平衡性质。精密度召回曲线的面积为 0.36 ,与英格兰银行 816 纸张精密度召回曲线相比,该曲线更具优势。 红点表示用于获得该车型 F1 最高分数的阈值。
使用 NVTABLAR 加速 PyTorch 深度学习培训
这个 NVIDIA NVTabular Python 软件包 是一个用于表格数据的功能工程和预处理库,旨在快速轻松地操作 TB 级数据集,并培训基于深度学习( DL )的推荐系统。它可以使用 Anaconda 或 Docker 安装,也可以使用带有 NVTabular 关键字的 pip 安装。在我们的例子中,我们只是在训练期间使用它将数据输入 PyTorch 分类器。我们还比较了使用普通 PyTorch 数据加载器与 NVTABLAR 的异步 PyTorch 数据加载器的运行时。我们发现,对于抵押贷款数据集, NVTabular 比不使用它有 6 倍的优势,因为两次运行都是在同一个 GPU 上完成的。有关更多详细信息,请参见图 4 和 文章 。
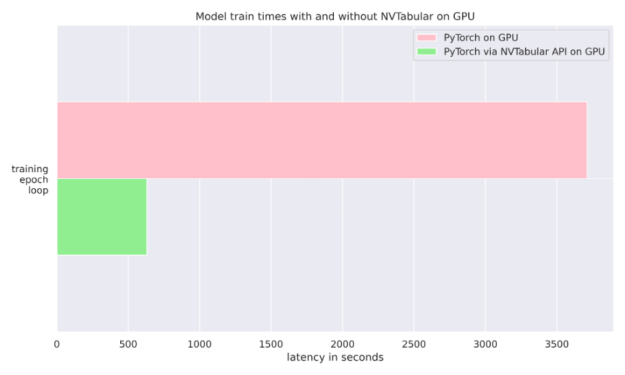
图 4 : NVTabular 6 X 加速度。两个 PyTorch 训练循环都在 GPU 上运行。
为了简单起见,我们选择了一个 5 层多层感知( MLP )神经网络,其中包含 512 个神经元,包括线性层、预处理、批量归一化和退出。简单的 MLP 能够在测试集上匹配 XGBoost 模型的性能。更复杂的模型可能会超过此性能。在将该阈值应用于测试集之前,采用相同的方法来确定在列车组上产生最大 F1 分数的阈值。分类报告和混淆矩阵如下所述,类似的 PR 曲线和 ROC 曲线如图 5 所示。
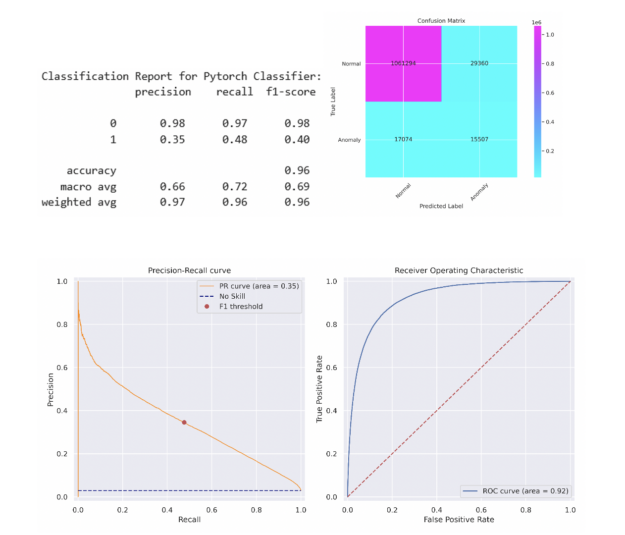
图 5 :PyTorch 深度学习精度召回曲线(左)和接收器操作特征曲线(右)反映了数据集的不平衡性质。精确查全率曲线的面积为 0.35 ,与英格兰银行 816 纸张精确查全率曲线相比,具有优势。
机器学习和深度学习的可解释性
既然我们对我们的预测模型有信心,那么就必须更多地了解它是如何工作的以及为什么工作的。对于 ML 和 DL 模型,可以使用 SHAP 和 Captum 计算 Shapley 值。对于 SHAP 包,可以很容易地检索 Shapley 值,以便按照下面的代码片段解释我们的 XGBoost ML 模型:
expl = shap.TreeExplainer(model) shap_values = expl.shap_values(X_test) shap.summary_plot(shap_values, X_test.to_pandas(), sort=False, show=False) plt.tight_layout()
使用CaptumGradientShap 方法计算 PyTorch DL Shapley 值,并使用以下代码绘制,将 Shapley 值传递到 SHAP summary _ plot ()方法中。我们分离出积极和消极的分类变量和连续变量,以便只可视化一个不同的类或两个类,如图 6 所示。
from captum.attr import GradientShap Gradshap = GradientShap(model) attr_gs, delta = gradshap.attribute((torch.cat([pos_cats, neg_cats], dim=0), torch.cat([pos_conts, neg_conts], dim=0)), baselines=(torch.zeros_like(neg_cats, device=device), torch.zeros_like(neg_conts, device=device)), n_samples=200, return_convergence_delta=True) df = DataFrame(cp.asarray(torch.cat([torch.cat([pos_cats, pos_conts], dim=1), torch.cat([neg_cats, neg_conts], dim=1)], dim=0))) df.columns = CATEGORICAL_COLUMNS + CONTINUOUS_COLUMNS svals = cp.asnumpy(torch.cat(attr_gs, dim=1)) shap.summary_plot(svals, df[CATEGORICAL_COLUMNS+CONTINUOUS_COLUMNS].to_pandas(), sort=False, show=False) plt.tight_layout()
一般来说,我们想解释一个单一的预测,并解释这些特征是如何导致该预测的。 Shapley 功能解释总结为一行的预测,我们可以跨行聚合以批量解释模型预测。出于监管目的,这意味着模型可以为任何输出(有利或不利)提供人类可解释的解释。任何持有抵押贷款或在债务工具领域工作的人都可以认识到这些熟悉的因素。
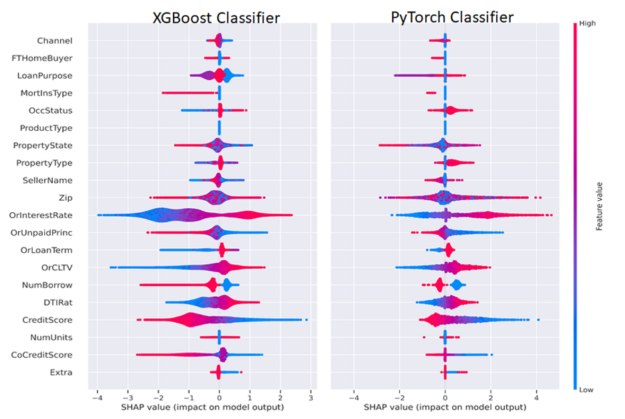
图 6 :使用 Shapley 算法测量特征的影响和方向。红色表示特征值较高,蓝色表示特征值较低。更为正值的 SHAP 值表示对正值类别(贷款拖欠)的贡献更大,反之亦然。要素名称通常显示在左侧。
图 6 并排描述了 ML 和 DL Shapley 值。我们可以以 CreditScore 和利率( OrInterestRate )特性为例,按照以下方式解释图 6 。 CreditScore 功能的红色部分表示较高的信用分数,如图右侧图例所示,较高的功能值为红色,较低的功能值为蓝色。对于聚集在负 x 轴上的 CreditScore 点,对应于负 SHAP 值,这有助于形成负或非拖欠类别,表明信用分数高的人不太可能拖欠。对称地, CreditScore 的蓝色(低)值位于正 x 轴或正 Shapley 值上,表示对正或拖欠类别的贡献。
OrInterestRate 功能也可以采用类似但相反的解释:低(蓝色)利率产生负 Shapley 值,并与较低的拖欠率相关,这是直观的,因为较低的利率意味着较低的抵押付款。有些特性可能不太清晰,为数据科学家或机器学习工程师提供了改进模型的机会。例如,在我们的简单 MLP 模型中,我们在传递到 MLP 之前将因式分类特征与连续特征连接起来。该模型的一个改进可能是使用分类嵌入,这既可以提高模型性能,也可以增强可解释性。通过这种方式,数据科学家或机器学习工程师可以尝试优化模型的可解释性和性能。
GPU-Acceleration results
图 7 和图 8 重点测试了读取输入数据集、合并两个数据集所需的时间,以及与 Ice Lake 24 核双 CPU 相比, NVIDIA Ampere A100 GPU 上的 DL 推断步骤。如表 1 所示,每个步骤都有稳定的加速。
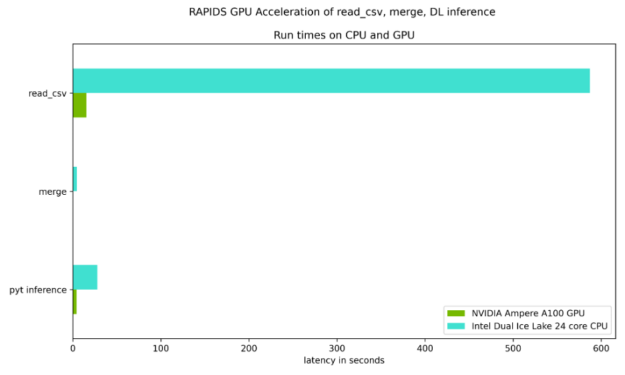
图 7 :键 RAPIDS Python 步骤的相对运行时延迟,对于耗时超过 1 秒的计算密集型步骤,其显示的加速比为 6 到 38 倍。

图 8 :关键 Python 步骤的相对运行时延迟,计算密集型步骤的加速比为 2 到 29 倍
表 1 量化了图 7 和图 8 所示的加速,并强调了 GPU 加速的好处。
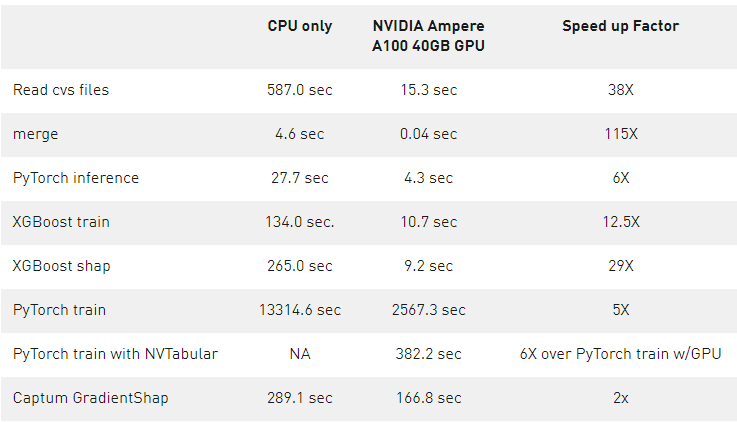
表 1 : 数据转换或 ETL 过程的各个步骤的相对计算延迟,以及 1120 万贷款数据集的培训和推理步骤。
在这篇文章中,我们扩展了先前的一篇相关文章,通过深入学习讨论了信用违约风险预测,并讨论了:
如何使用 RAPIDS 来 GPU 加速完整的默认分析工作流
如何使用 GPU 在 RAPIDS 内部应用 XGBoost 实现
如何将深度学习lib库应用于 GPU 表格数据
如何使用 查看 NVTabular 包 对于 GPU 上的 PyTorch DL ,只需更改数据加载器即可获得 6 倍的运行时性能。
如何使用 Shap 和 Captum 包以及 GPU 访问可解释的预测,并使用这些可解释的结果进一步改进模型。
关于作者
Emanuel Scoullos 是 NVIDIA 金融服务和技术团队的数据科学家,他专注于 FSI 内的 GPU 应用。此前,他在反洗钱领域的一家初创公司担任数据科学家,应用数据科学、分析和工程技术构建机器学习管道。他获得了博士学位。普林斯顿大学化学工程硕士和罗格斯大学化学工程学士学位。
Mark J. Bennett 是 NVIDIA 的高级数据科学家,他专注于金融机器学习的加速。他拥有南加州大学计算机科学硕士学位和博士学位。来自加州大学洛杉矶分校的计算机科学,并为爱荷华大学和芝加哥大学教授研究生业务分析。他曾在阿贡国家实验室、诺基亚贝尔实验室、诺斯罗普·格鲁曼公司、 XR 交易证券公司和美国银行证券公司担任工程和管理职务。马克与 R 合著了《金融分析》一书,由剑桥大学出版社出版。
John Ashley 目前领导 NVIDIA 的全球金融服务和技术团队。在此之前,他启动并领导了 NVIDIA 的专业服务深度学习实践和 NVIDIA 深度学习专业服务合作伙伴计划,致力于帮助客户和合作伙伴采用并提供深度学习解决方案。此前在 NVIDIA 任职期间,他还负责管理与IBM软件和认知团队的关系,是一名高级解决方案架构师,负责纽约和伦敦的金融服务,并支持 NVIDIA 与平方公里阵列射电天文学项目的合作。他拥有计算科学和信息学博士学位,以及电子工程学士和硕士学位。
Prabhu Ramamoorthy 是 NVIDIA 的金融生态系统合作伙伴经理,他专注于金融服务的 HPC / ML / AI 加速。他拥有来自威斯康星大学麦迪逊的工商管理硕士学位和来自印度顶尖工程学院之一的 BIT PrANIN 的本科学位。他是特许金融分析师 CFA 特许持有人、金融风险经理 FRM 和特许另类投资分析师 CAIA ,专门研究金融用例。他曾担任保证金软件公司 Dash Regtech (前身为 LDB ,被视为金本位)的技术负责人,主要面向投资银行和经纪自营商,并曾在四大公司毕马威/安永担任金融服务业务总监,在过去 10 年中,他帮助了 80 多家金融机构。
Jochen Papenbrock 位于德国法兰克福,在过去的15年中,Jochen一直在金融服务业人工智能领域担任各种角色,担任思想领袖、实施者、研究者和生态系统塑造者。
Miguel Martinez 是 NVIDIA 的高级深度学习数据科学家,他专注于 RAPIDS 和 Merlin 。此前,他曾指导过 Udacity 人工智能纳米学位的学生。他有很强的金融服务背景,主要专注于支付和渠道。作为一个持续而坚定的学习者, Miguel 总是在迎接新的挑战。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5694浏览量
110119 -
机器学习
+关注
关注
67文章
8565浏览量
137228 -
python
+关注
关注
58文章
4885浏览量
90314
发布评论请先 登录
壁仞科技壁砺166系列GPU产品率先支持Kimi K2.6模型

将TensorFlowSavedModel转换为支持imx8mpNPU的tflite模型,没有成功是怎么回事?
如何获得 libegl?
沐曦股份曦云C系列GPU深度适配通义千问Qwen3.5模型

高新兴瑞联成功通过国家高新技术企业认定
沐曦股份曦云C系列GPU Day 0适配智谱GLM-4.6V多模态大模型

沐曦股份GPU加速技术助力药物研发降本增效
罗德与施瓦茨即将亮相2025年慕尼黑电子展
芯驰科技高端车规MCU E3620P成功流片并开启送样

构建CNN网络模型并优化的一般化建议
德赛电池成功获得RBA白银等级认证
移远通信飞鸢AIoT大模型应用算法成功通过备案



评论