 NVIDIA DGX A100的DNA测序技术研究
NVIDIA DGX A100的DNA测序技术研究

快速且经济高效的全基因组测序和分析可以迅速为患有罕见或未诊断疾病的危重患者提供答案。最近在加速临床测序方面取得的进展,例如创造世界纪录 用于快速诊断的DNA测序技术 ,使我们离在临床环境中进行全基因组基因诊断又近了一步。
斯坦福大学医学院( Stanford University School of Medicine )、NVIDIA ( NVIDIA )、谷歌( Google )、 UCSC 和牛津纳米孔技术( Oxford Nanopore Technologies , ONT )领导的一个团队最近使用这项技术来识别与疾病相关的基因变异,这些变异在短短 7 小时 18 分钟内就得到了诊断,结果于 2022 年 1 月发表在 新英格兰医学杂志 上。
这一创纪录的端到端基因组工作流程依赖于创新技术和高性能计算。它利用长阅读纳米孔测序技术更好地分析结构变体。这是在 48 个流动池中实现的,优化的方法使孔占有率达到 82% ,在短短几个小时内快速生成 202 千兆碱基。对输出的分析分布在一个谷歌云计算环境中,包括 16 个 4xV100 GPU 实例(总计 64 GPU 个)的基调用和对齐,以及 14 个 4xP100 GPU 实例(总计 56 GPU 个)的变体调用。
自一月 NEJM 发表以来,NVIDIA Clara 团队一直在优化 DGX-A100 的全基因组工作流程,使临床医生和研究者能够在八 A100 GPU 上部署与世界记录方法相同的分析,而在 4H10M 中部署 60X 全基因组(图 1 ;在 HG00 参考样品上标明)。
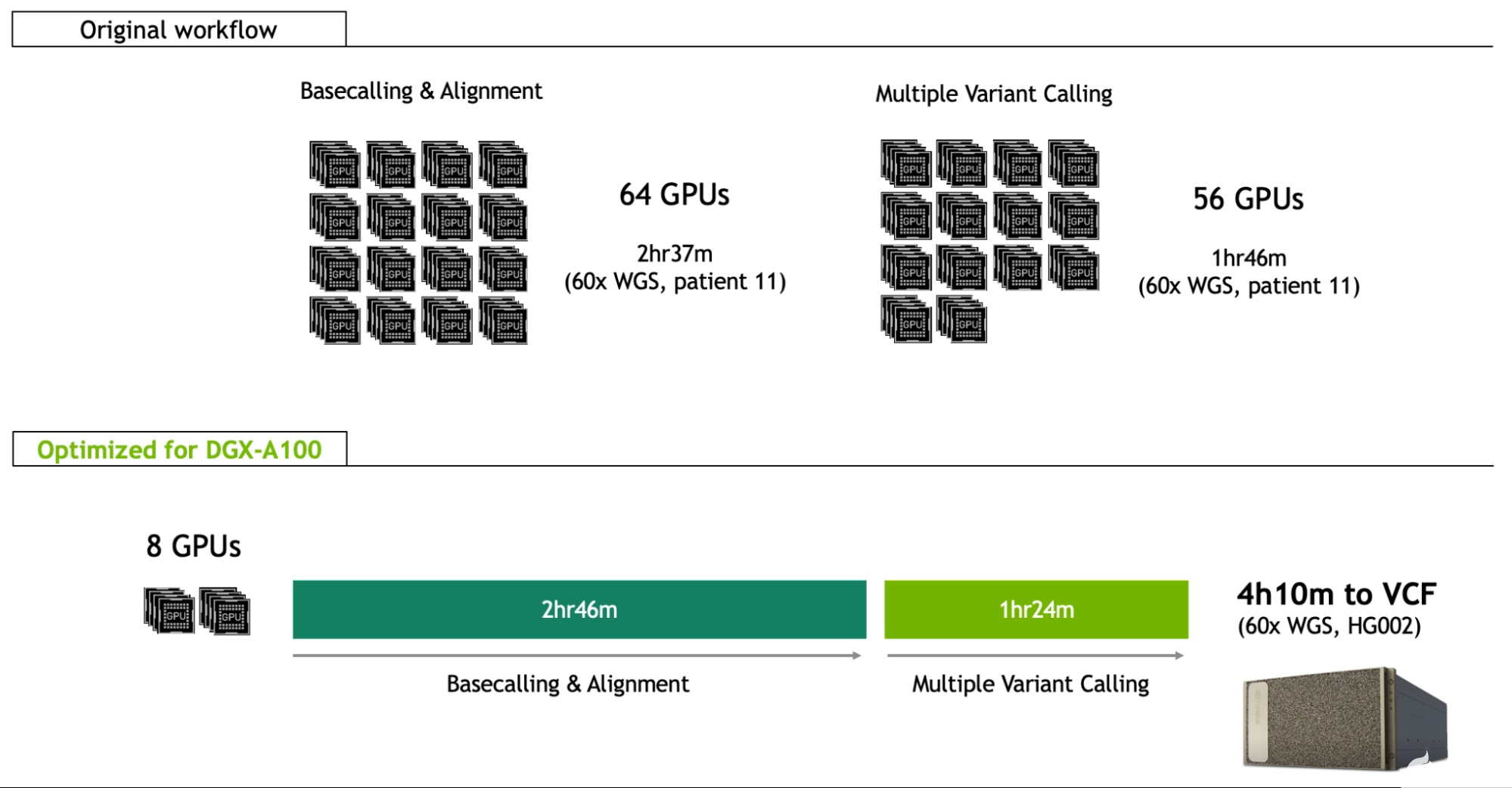
图 1 。 NVIDIA DGX-A100 上优化的纳米孔测序工作流程
这不仅可以在本地运行的单服务器( 8-GPU )框架中实现快速分析,还可以将每个样本的成本降低三分之二,从 568 美元降至 183 美元。
基本呼叫和对齐
碱基调用是将原始仪器信号分类为基因组碱基 A 、 C 、 G 和 T 的过程。这是确保所有下游分析任务准确性的计算关键步骤。这也是一个重要的数据缩减步骤,将生成的数据缩减约 10 倍。
以每碱基 340 字节为单位,一个单一的 60 倍覆盖率的整个基因组在原始信号中很容易达到数万亿字节,而在处理时则为数百千兆字节。因此,计算速度有利于与测序输出速度相匹敌,这是非常重要的,通过 48 个流动单元的 128000 个孔,以每秒约 450 个碱基的速度进行。
ONT 的 PromethION P48 测序仪在 72 小时的运行中可以产生多达 10 个 Terabase ,相当于 96 个人类基因组(覆盖率为 30 倍)。
这项工作所需的快速分类任务已经受益于深度学习创新和 GPU 加速。用于此目的的核心数据处理工具包 Guppy 使用递归神经网络( RNN )进行基址调用,可以选择更小(更快)或更大(更高精度)的递归层大小的三种不同架构。
BaseCall 中的主要计算瓶颈是 RNN 内核,它得益于 GPU 与 ONT 序列器的集成,例如桌面网格 Mk1 ,其中包括一个 V100 GPU 和手持 MinION Mk1C ,其中包括一个 Jetson 边缘平台。
比对是将合成的碱基 DNA 片段(现在是 As 、 Cs 、 Gs 和 Ts 的字符串形式)提取出来,并确定这些片段起源的基因组位置,通过大规模并行测序过程组装完整基因组的过程。这基本上是从许多 100-100000 bp 长的读取中重建全长基因组。就创造世界纪录的样本而言,总共有 1300 万次阅读。
在最初的世界记录分析中, basecalling 和 alignment 分别在 Guppy 和 Minimap2 的不同实例上运行。通过将其迁移到单服务器 DGX-A100 解决方案,并使用 Guppy 的集成 minimap2 aligner ,您可以立即节省 I / O 时间,并从 A100 用于 RNN 推断的张量核心中获益。通过在 DGX 上分别平衡八个 A100 GPU 和 256 CPU 线程的基址调用和对齐,这两个进程可以完全重叠,以便与基址调用同时对齐读取,不会对总运行时间造成影响(《 1 分钟)。
这使 DGX-A100 上的 basecalling 和校准步骤的运行时间变为 2h 46m ,这也可以与测序本身重叠。这与 60 倍样本的预期测序时间相似。
变异呼叫
变体调用是工作流的一部分,旨在识别新组装个体基因组中与参考基因组不同的所有点。这包括扫描基因组的全部宽度,以寻找不同类型的变异。例如,这可能包括小的单碱基对变体,一直到覆盖数千个碱基对的大结构变体。世界纪录管道使用胡椒粉作为小变体,使用嗅探作为结构变体。
PEPPER Margin DeepVariant 方法旨在优化小变异,以实现纳米孔测序产生的长读。
PEPPER 通过 RNN 识别候选变体, RNN 由两个双向、选通、循环单元层和一个线性转换层组成。
Margin 然后使用隐马尔可夫模型方法进行一个称为单倍型的过程,确定哪些变体是从母系或父系染色体一起遗传的。它将此信息传递给 Google DeepVariant ,以最大限度地提高杂合子变体调用的准确性。
DeepVariant 通过一个深度卷积神经网络对最终变体进行分类,该网络建立在 Inception v2 体系结构之上,专门适用于 DNA 读取堆积输入图像。
总的来说, PEPPER Margin DeepVariant 允许更快的 PEPPER 神经网络扫描整个基因组寻找候选基因,然后使用更大的 DeepVariant 神经网络对这些候选基因进行高精度的变异调用。为了加速这条管道,世界纪录工作流使用了 Parabricks DeepVariant ,这是一种 GPU 加速的实现,比 CPU 上的开源版本快 20 倍以上(图 2 )。
Clara 团队通过修改 PEPPER Margin 以集成方式运行,按染色体分割数据,并在 GPU 上同时运行程序,进一步加快了速度。 PEPPER 还针对批量大小、工作人员数量和呼叫者数量等管道参数进行了优化,并对 PyTorch 进行了升级,以支持 NVIDIA 安培体系结构加速 RNN 推理瓶颈。
对于结构变量调用, Snifgles 升级为最近发布的 Snifgles 2 ,其效率要高得多,仅在 CPU 上的加速度为 38 倍。
所有这些改进使 DGX-A100 的多变量调用阶段的运行时间达到 1h 24m 。
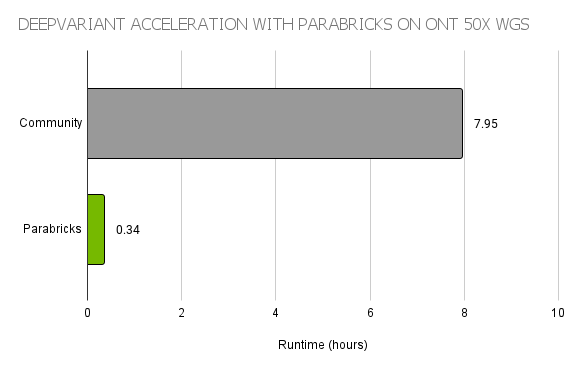
图 2 。 Parabricks DeepVariant 支持在 ONT 数据上快速运行
视频 1 。危重病人超快速 DNA 测序技术的优化
使用 NVIDIA DGX-A100 为实时测序供电
通过优化 DGX A100 的世界记录 DNA 测序技术,NVIDIA Clara 团队为实时测序提供了动力,简化了单个服务器上的复杂工作流,并且在达到最先进性能的同时,将分析成本降低了 50% 以上。
关于作者
Harry Clifford:作为NVIDIA 基因组学的高级产品架构师, Harry 致力于工程和产品开发之间的接口,利用NVIDIA 在人工智能、高性能计算( HPC )和数据分析堆栈方面的专业知识,以加速高精度解决方案解决基因组学工作流问题。他的背景是生物信息学和功能基因组学,包括来自牛津大学的博士学位、生物制药行业和剑桥大学的博士后经验以及生物技术领域的创业经验。哈里在与人共同创立精准肿瘤公司 CCG 后,被列入福布斯“ 30 岁以下”榜单。 ai (被 Dante Labs 收购),一家由 Y Combinator 和默克加速器支持的初创公司,通过深度学习和高级分析软件提供决策支持。
审核编辑:郭婷
-
神经网络
+关注
关注
42文章
4844浏览量
108218 -
NVIDIA
+关注
关注
14文章
5696浏览量
110144
发布评论请先 登录
首届中国NVIDIA DGX Spark黑客松大赛开启报名
NVIDIA DGX Spark助力高等教育领域重大项目
NVIDIA DGX SuperPOD为Rubin平台横向扩展提供蓝图
NVIDIA DGX Spark桌面级AI超级计算机助力开发者构建AI模型
NVIDIA DGX Spark系统恢复过程与步骤

NVIDIA DGX Spark助力构建自己的AI模型

在NVIDIA DGX Spark平台上对NVIDIA ConnectX-7 200G网卡配置教程
NVIDIA DGX Spark快速入门指南

NVIDIA宣布开源Aerial软件
新手小白必看!关于A100云主机租用,你想知道的一切都在这!

NVIDIA黄仁勋向SpaceX马斯克交付DGX Spark
NVIDIA DGX Spark新一代AI超级计算机正式交付
NVIDIA DGX Spark桌面AI计算机开启预订




评论