 MLPerf v1.0培训基准反映最先进的人工智能应用
MLPerf v1.0培训基准反映最先进的人工智能应用

MLPerf 是一个全行业人工智能联盟,其任务是开发一套性能基准,涵盖广泛使用的一系列主要人工智能工作负载。最新的 mlperfv1 。 0 培训包括视觉、语言和推荐系统,以及强化学习任务。它不断发展,以反映最先进的人工智能应用。
NVIDIA 按照我们的传统,提交了所有八个基准的 MLPerf v1 。 0 培训结果。事实上,建立在 NVIDIA 人工智能平台上的系统是唯一可以进行全面提交的商用系统。
与之前提交的 MLPerf v0 。 7 相比,我们在芯片到芯片的基础上提高了 2 。 1 倍,在规模上提高了 3 。 5 倍。我们创造了 16 项业绩记录,其中 8 项是基于每个芯片的, 8 项是针对商用解决方案类别的大规模培训。
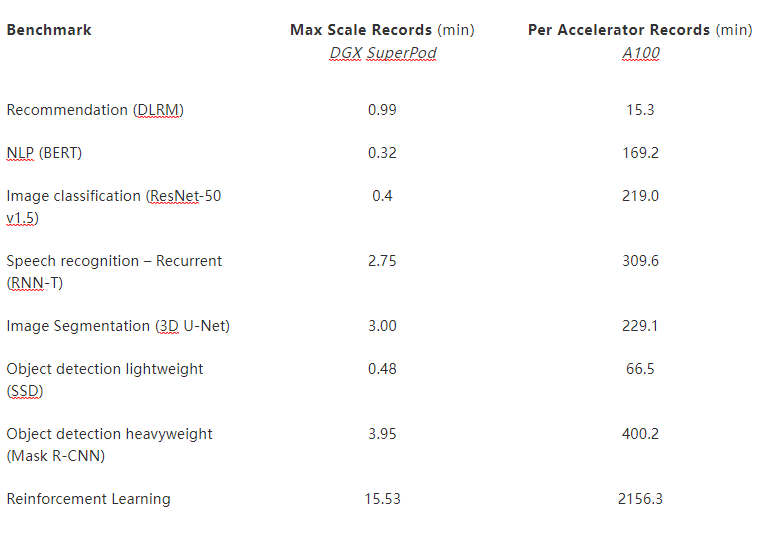
表 1 。 NVIDIA MLPERF AI 记录。
(*)
(*)使用 NVIDIA 8xA100 服务器训练时间计算 A100 的每个加速器性能,并将其乘以 8 |每个芯片的性能比较,通过比较最接近的类似规模下的性能得出其他性能。
根据加速器记录: BERT : 1 。 0-1033 | 数据链路管理: 1 。 0-1037 | 面罩 R-CNN : 1 。 0-1057 | ResNet50 v1 。 5 : 1 。 0-1038 | 固态硬盘: 1 。 0-1038 | RNN-T : 1 。 0-1060 | 3D U 网: 1 。 0-1053 | 迷你们: 1 。 0-1061
最大刻度记录: BERT : 1 。 0-1077 | 数据链路管理: 1 。 0-1067 | 面罩 R-CNN : 1 。 0-1070 | ResNet50 v1 。 5 : 1 。 0-1076 | 固态硬盘: 1 。 0-1072 | RNN-T : 1 。 0-1074 | 3D U 网: 1 。 0-1071 | 迷你们: 1 。 0-1075
MLPerf 名称和徽标是商标。有关详细信息,请参阅 www.mlperf.org 。
这是以 NVIDIA A100 GPU s 为特色的第二轮 MLPerf 训练。我们对相同硬件的持续改进是 NVIDIA 平台实力和持续软件改进承诺的生动证明。与前几轮 MLPerf 一样, NVIDIA 工程师开发了一系列创新,以实现这些新的性能水平:
在所有基准上扩展 CUDA 图形 。传统上,神经网络是从 CPU 以单个内核的形式启动,在 GPU 上执行。在 MLPerf v1 。 0 中,我们在 GPU 上启动了整个内核序列,将与 CPU 的通信最小化。
使用 SHARP 将节点之间的有效互连带宽增加一倍。夏普将集合操作从 CPU 和 GPU 卸载到网络,并消除了在端点之间多次发送数据的需要。
CUDA 图形和锐利的增强使我们能够将我们的规模增加到 4096 GPU 的创纪录数字,用于解决单个人工智能网络。
空间并行性使我们能够在 8 个 GPU 上分割单个图像,用于像 3D U-Net 这样的大规模图像分割网络,并使用更多的 GPU 来获得更高的吞吐量。
在硬件改进中, NVIDIA A100 GPU 上的新 HBM2e GPU 内存将内存带宽提高了近 30% ,达到 2 TBps 。
这篇文章提供了许多用于提供出色规模和性能的优化的见解。其中许多改进在 NGC 上可用,它是 NVIDIA GPU 优化软件的中心。您可以在实际应用程序中认识到这些优化的好处,而不只是在一旁观察更好的基准测试分数。
大规模训练
大规模培训需要对系统硬件和软件进行精确调整,以协同工作,并支持大规模出现的独特性能要求。 NVIDIA 在这两个方面都取得了重大进展,现在可以用于生产。
在系统方面,我们大规模培训的关键组成部分是 NVIDIA DGX SuperPOD 。 DGX SuperPOD 是 HPC 和 AI 数据中心多年专业经验的结晶。它基于 NVIDIA DGX A100 ,具有最新的 NVIDIA A100 张量核心 GPU 、第三代 NVIDIA NVLink 、 NVSwitch 和 NVIDIA ConnectX-6 VPI 200 Gbps HDR InfiniBand 。这些结合起来,使赛琳娜成为 超级计算机 500 强排行榜 中排名前五的超级计算机,其组件如下:
4480 NVIDIA A100 张量核 GPU s
560 NVIDIA DGX A100 系统
850 Mellanox 200G HDR InfiniBand 交换机
在软件方面, NGC 容器版本 v 。 21 。 05 增强并支持多种功能:
分布式优化器支持增强。
使用 Mellanox HDR Infiniband 和 NCCL 2 。 9 。 9 提高了通信效率。
增加了锐利的支撑。 SHARP 改进了 MPI 和机器学习集体操作的性能。向 NCCL 添加了 SHARP 支持,以将所有 reduce 集体操作卸载到网络结构中,从而减少节点之间的数据传输量。
工作量
在本节中,我们将深入研究针对选定的单个 MLPerf 工作负载的优化。
建议( DLRM )
推荐可以说是当今数据中心中最普遍的人工智能工作负载。 NVIDIA MLPerf DLRM 提交基于 HugeCTR ,一个 GPU 加速推荐框架,它是 NVIDIA Merlin 开放测试版框架的一部分。 HugeCTR v3 。 1 测试版增加了以下优化:
混合嵌入
优化集体
优化的数据读取器
带嵌入的重叠 MLP
全迭代 CUDA 图
混合嵌入
将 DLRM 扩展到多个节点的主要挑战之一是 NVLink 和 Infiniband 之间的 per- GPU all-to-all 带宽相差约 10 倍。这使得节点间的嵌入交换成为训练过程中的一个重要瓶颈。
为了解决这个问题, HugeCTR 实现了混合嵌入,这是一种新的嵌入设计,在进行前向传递的嵌入权值交换之前,对一批类别进行重复数据消除。在后向通道中进行梯度交换之前,还可以局部减小梯度。
为实现高效的重复数据消除,混合嵌入根据类别的统计访问频率将类别映射为频繁和不频繁的嵌入。频繁嵌入是以数据并行的方式实现的,它在一个批处理中带走了大部分复制的类别,减少了嵌入交换的流量。不频繁嵌入遵循分布式模型并行嵌入范式。这使 DLRM 能够以前所未有的效率扩展到多个节点。
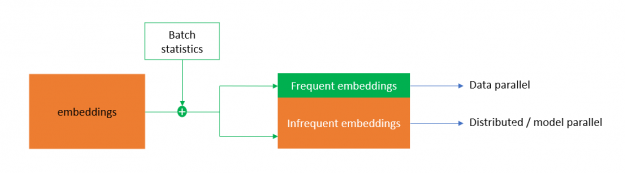
图 1 。混合嵌入 HugeCTR
优化集体
所有到所有和所有减少集体延迟在扩展效率方面起着重要作用。小消息大小的多节点全对全吞吐量受到 Infiniband 消息速率的限制。为了缓解这种情况, HugeCTR 使用分层的 all-To-all 实现了融合的 NVLink 聚合,以嵌入 exchange 。
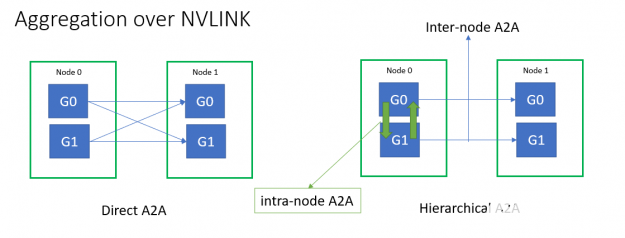
图 2 。 ZBK8 中的集体优化
您可以从所有节点到所有节点进行优化,并进一步减少延迟:
直接使用本机 IB verbs API 和 SHARP 来减少库开销。
图形可捕获, GPU – 启动通信以减少启动开销。
用单侧跃迁协议代替双侧会合协议来减少网络跳数。
使用持久通信缓冲区消除冗余的消息缓冲区副本。
直接在 GPU 内存上使用 NIC 原子,而不是通过 CPU 间接定向,减少了 NIC- GPU 同步延迟。
与环网相比,还使用单次减少算法优化了节点内的所有减少。
频繁嵌入 all-reduce 和 MLP-all-reduce 融合到一个 all-reduce 操作中,以节省暴露的 all-reduce 延迟。
优化的数据读取器
输入管道在培训绩效中起着重要的作用。为了达到峰值 I / O 吞吐量, HugeCTR 使用 Linux 异步 I / O 库( AIO )实现了一个完全异步的数据读取器。由于混合嵌入要求整个批处理出现在所有 GPU 上,因此每个 GPU 的直接主机到设备( H2D )将使 PCIe 成为瓶颈。因此,使用分层方法将数据复制到 GPU 上,首先通过 PCIe 执行 H2D ,然后通过 NVLink 进行广播。
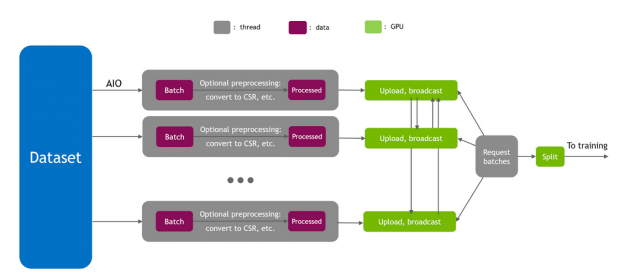
图 3 。 HugeCTR 多线程数据读取器
此外,来自数据读取器的 H2D 通信可能会干扰节点间的 all-to-all 并减少通过 PCIe 的通信量。因此, HugeCTR 实现了智能数据读取器调度以避免这种干扰。
带嵌入的重叠 MLP
由于底层 MLP 与嵌入没有数据依赖关系,因此底层 MLP 的几个组件可以与嵌入重叠,以有效地利用 GPU 资源。
底部 MLP 正向与嵌入正向过程重叠
频繁嵌入局部权值更新与所有约简重叠
MLP 重量更新与节间全对全重叠
cuBLAS Lt GEMM 融合
HugeCTR 实现了一个融合的、完全连接的层,该层利用了 cublasLt GEMM 融合:
用于 MLP-fprop 的 GEMM + Relu +偏置融合
GEMM + dRelu + dBias 融合治疗 MLP-bprop
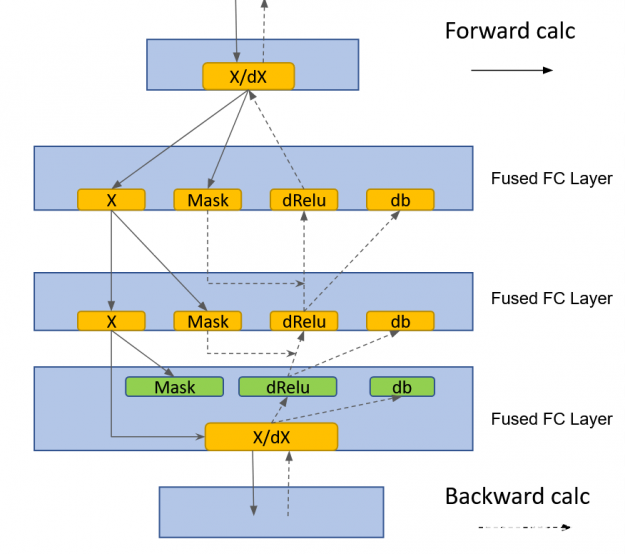
图 4 。使用 cuBLAS Lt GEMM 熔合的 HugeCTR 中的熔合 FC 层
全迭代 CUDA 图
为了减少启动延迟并防止内核启动、数据读取器和通信流量之间的 PCIe 干扰,所有 DLRM 计算和通信内核都设计为流可捕获。整个训练迭代被捕获到一个 CUDA 图中。
通过前面的优化,我们扩展到多个节点,并在不到一分钟的时间内在 14 个 DGX-A100 节点上完成了 DLRM 训练任务。与之前提交的 v0 。 7 相比,这是 3 。 3 倍的加速。
NLP ( BERT )
BERT 可以说是当今 NLP 领域最重要的工作负载之一。在 MLPerf v1 。 0 版本中,我们通过以下优化改进了 v0 。 7 版本:
融合多头注意
分布式羔羊
无同步训练
CUDA graphs in PyTorch
一炮皆减锐利
融合多头注意
多头注意块中激活张量的大小随序列长度的平方而增大。这会导致内存占用增加,以及由于伴随的内存访问操作而导致运行时间延长。我们将 softmax 、掩蔽和退出操作融合到一个内核中,包括前向传递和后向传递。通过这样做,我们避免了对多头注意块中的大激活张量进行多次内存访问操作,从而显著提高了性能。
有关详细信息,请参阅 NVIDIA Apex 库中的 SelfMultiheadAttn 。
分布式 LAMB
在这一轮 MLPerf 中,我们实现了分布式 LAMB 。在分布式 LAMB 中,梯度首先在每个 DGX-A100 节点内的八个 GPU 上分裂。接下来是八个独立组中的节点之间的 all reduce 。在这个操作之后,每个 GPU 都有 8 个块中的一个,这些块构成了全约化梯度张量, LAMB 优化器在 1 / 8 上运行th全梯度张量。
必要时,通过计算局部范数并执行 all-reduce 操作来计算梯度范数。在优化器之后,在每个节点上执行一个 intranode all gather 操作,这样每个 GPU 都有完整的更新参数张量。继续执行下一次迭代的前向传递。
分布式 LAMB 极大地提高了单节点和多节点配置的性能。有关更多信息,请参阅 Apex 库中的 DistributedFusedLAMB 。
无同步训练
在某些情况下, GPU 的执行取决于在 CPU 上存储或计算的某个值。一个例子是当一个特定的张量有一个不同的大小,这取决于每次迭代的计算。因为张量大小信息保存在 CPU 上, GPU 和 CPU 之间必须有一个同步,才能传递张量大小信息以进行适当的缓冲区分配。
我们的解决方案是使用具有固定大小的张量,但使用单独的布尔掩码指示哪些元素是有效的。这种方法不需要 CPU – GPU 同步,因为张量大小是已知的。当后续计算必须知道张量的实际大小时,对于平均运算,布尔掩码的元素可以在 GPU 上求和。
尽管这种方法导致对 GPU 内存的访问稍微多一些,但它比在关键路径中进行 CPU 同步要快得多。这种优化为小的本地批处理大小带来了显著的性能提升,对于我们的 max-scale 配置就是这样。这是因为 CPU 同步无法跟上小批量的快速 GPU 执行。

图 5 。无同步训练消除了 CPU 同步
CPU – GPU 同步的另一个来源是保存在 CPU 上的数据,例如学习率或其他可能的优化器状态。我们将所有优化器状态保留在 GPU 上,以便分布式 LAMB 实现无同步执行。
通过这些优化,我们消除了训练周期中 CPU 和 GPU 之间的所有同步。唯一的同步是发生在评估点上的同步,以将每个评估点的评估精度实时记录到一个文件中。
CUDA graphs in PyTorch
传统上, CPU 单独启动每个 GPU 内核。一般来说,即使 GPU 内核对大批量处理做更多的工作, CPU 内核启动工作和相关的 CPU 开销保持不变,除非 CPU 调度发生变化。因此,对于较小的本地批处理大小, CPU 开销可能成为一个重要的性能瓶颈。这就是我们在 MLPerf 中的 max-scale BERT 配置中发生的情况。
除此之外,当 CPU 执行成为瓶颈时, CPU 执行的变化会导致每个迭代的所有 GPU 的运行时不同。当工作负载扩展到多个 GPU 时(在本例中是 4096 个 GPU ),这会带来很大的同步开销。每个 GPU 同步每个梯度缩减的迭代,迭代时间由最慢的工人决定。
BERT 图形是一种功能,它允许一次启动整个内核序列,消除了内核执行之间的 CPU 开销。 CUDA 图形最近在 PyTorch 中可用。通过图捕获模型,我们消除了 CPU 开销和伴随的同步开销。对于我们的 max-scale CUDA 配置, CUDA Graphs 实现本身就带来了 1 。 7 倍的性能提升。
一炮皆减锐利
夏普显著提高了 BERT 的集体性能,特别是我们的最大规模配置。对于这种 BERT 配置,夏普的端到端性能提升了 17% 。
图像分类( ResNet-50 v1 。 5 )
ResNet-50 是 MLPerf 工作负载中的老手。在这个版本的 MLPerf 中,我们继续通过改进 cuDNN 中的 Conv + BN + ReLu 融合内核来优化 ResNet ,并进行以下优化:
DALI 优化
MXNet 保险丝 BN + ReLu
改进的 MXNet 依赖引擎改进
DALI 优化
在 ResNet-50 的大范围(》 128 个节点)中,我们将每 GPU 的本地批大小减少到非常小的值。这通常会导致低于 20 毫秒的迭代时间。为了减少数据管道的开销,我们引入了输入批处理乘数( IBM )。大批量的 DALI 吞吐量高于小批量。为了利用这个事实,我们创建了比本地批大小大得多的超级批。对于每个迭代,我们从这些超级批中导出所需的样本,从而增加 DALI 处理吞吐量并减少数据管道开销。
在这些小的迭代时间中,无间隙和连续执行是实现完美缩放的关键。 通过提示预分配 DALI 缓冲区 是我们引入的另一个功能,用于在探索数据集时减少动态 GPU 内存分配的开销。
MXNet 融合了 BN + ReLu 和 BN + Add + ReLu 性能优化
对于 ResNet-50 ,批处理范数( BN )是网络迭代时间的重要部分。通过矢量化、缓存友好的内存遍历和减少量化,优化了 MXNet 中融合的 BN + ReLu 和 BN + Add + ReLu 核。
改进的 MXNet 依赖引擎改进
新的 MXNet 依赖引擎提供了一种异步方法来调度 GPU 上的工作,减少了主机( CPU )开销和抖动,例如 MXNet 和 Horovord 握手产生的开销。
在新的依赖关系引擎中,只要在 GPU 上安排了工作,操作就会更新依赖关系,而不是在工作完成时。后续操作必须执行同步以确保正确性。通过消除对同步的需要并使用 cudaStreamWait 事件来管理依赖关系,这一点得到了进一步的增强。
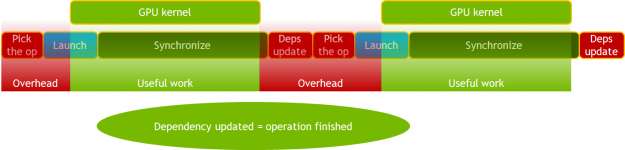
图 6 。 ResNet-50 和旧的 MXNet 依赖引擎
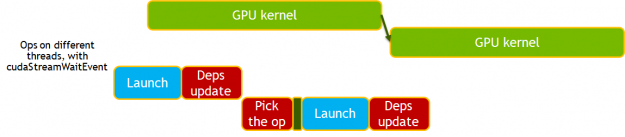
图 7 。 ResNet-50 和新的依赖引擎, cudaStreamWaitEvent
图像分割( 3D U 网)
U-Net3D 是这一轮 MLPerf 训练的两个新工作量之一。我们使用了以下优化:
空间平行性
异步求值
数据加载器
通道上次布局支持
空间平行性
在 3du-Net 中,由于训练数据集中的样本数相对较小,因此在原始数据并行性的情况下,其可伸缩性有一个基本的限制。为了打破这一限制,我们使用空间平行性将单个图像分割成八个 GPU s 。在反向传播结束时,可以像往常一样减少每个分区的梯度,以得到合成的梯度,然后可以用来计算权重梯度。
实现空间并行卷积的简单方法是在运行卷积之前从相邻的 GPU 传输光环信息。然而,为了提高效率,我们实现了一个不同的方案,在这个方案中,我们从相邻的 GPU 转移光环,同时运行主要的内部卷积。这个主卷积的误差项是用光晕独立计算出来的,再加上它就得到了结果。通过隐藏传输成本,我们看到了比单纯方法更好的扩展效率。
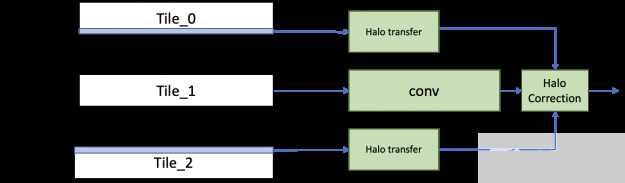
图 8 。 fprop 空间并行卷积
对于反向传播,类似地, dgrad 操作所需的光晕与权值梯度和数据梯度的计算并行传输。然后,为数据梯度传输的光晕被重新用于计算权重和数据梯度的校正项。
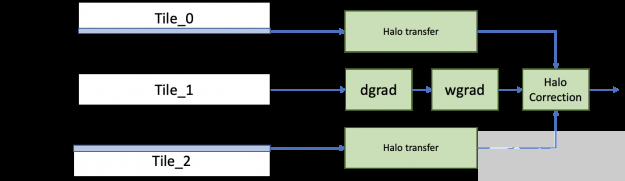
图 9 。带 bprop 的空间并行卷积
3D U-NET 在网络中间具有瓶颈区域,其激活大小小得多,不适合于空间并行性。我们使用了一种混合方法,只对从中受益的层使用空间并行性。我们从瓶颈区域之前的所有 GPU 中收集样本的激活,并在每个 GPU 上连续执行这些层。当合作变得有益时,我们又把工作分给了 GPU 。这确保了我们为网络的每个区域分别做出最佳选择。
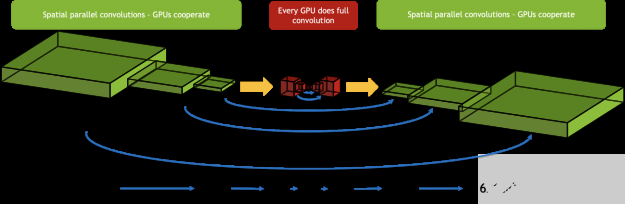
图 10 。空间并行性在三维 U 网中的应用
异步求值
在参考代码中,求值贡献了大量的时间。因为评估可以与训练同时运行,所以我们为运行评估分配了专用节点。
为了将评估完全隐藏在训练周期之后,我们使用了空间并行来加速验证步骤。此外,由于 evaluation 使用同一组图像,因此这些图像只加载一次,然后缓存在 GPU 内存中。
因为评估要到培训的三分之一时间才会开始,所以评估节点有足够的时间加载、处理和缓存数据集,以及初始化所有必需的库。
在训练周期结束时,训练节点使用 InfiniBand 将模型快速传输到评估节点,并继续运行后续的训练迭代。传递模型参数后,求值节点运行求值。在评估结束时,如果达到目标精度,评估节点将与训练节点通信。
添加的评估节点数量刚好足以将整个评估周期隐藏在训练周期之后。
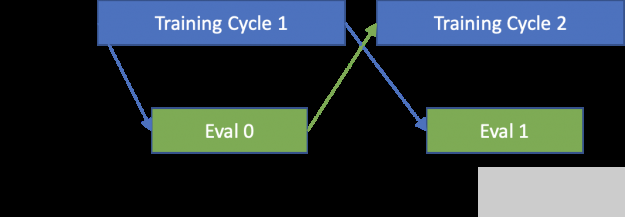
图 11 。异步评估计划
数据加载器
我们通过两种方式优化了数据加载器:优化扩充和缓存数据集。
Augmentations :由于数据集的小尺寸, 3D U-Net 需要大量的扩充。最昂贵的操作之一是我们称之为“有偏见的作物”。与随机裁剪相反,有偏裁剪以给定的概率选择具有正标签的区域。这要求每次选择昂贵的路径时,都要对标签上的三维连接组件进行大量计算。为了避免每次加载示例时都计算连接的组件,结果将缓存在主机中并重用,以便只计算一次。
数据加载 :随着使用新特性的培训变得更快, I / O 开始成为瓶颈。为了缓解这种情况,我们将整个图像数据集缓存在 GPU 内存中。这将从关键数据加载程序路径中移除 PCIe 和 I / O 。当图像从大而高带宽 GPU 内存加载时,标签从 CPU 加载以执行增强。
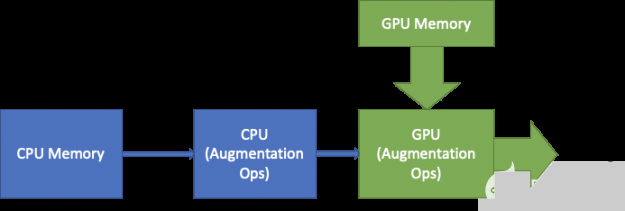
图 12 。 ZFK5 内存上的数据缓存
通道上次布局支持
因为 Channels Last 布局对于卷积内核更有效,所以在 MXNet 中添加了对 Channels Last 格式的本机支持。这避免了模型中需要的任何额外转置,以利用高效的 GPU 内核。
优化的 cuDNN 内核
3du-Net 有多个编码器和解码器层,信道数很小。使用 256 的典型平铺大小× 64 对于这些操作中使用的内核,会产生显著的分片大小量化效果。为了优化这一点, cuDNN 添加了一些内核,这些内核针对较小的磁贴大小进行了优化,具有更好的缓存重用性。这有助于 3D-U-Net 实现更好的计算利用率。
除了这些优化之外, 3du-Net 还受益于优化的 BatchNorm + ReLu 激活内核。使用 BatchSize 值 1 重复运行 BatchNorm 内核以获得实例 Norm 功能。在 MXNet 、 CUDA 图形和 SHARP 中实现的异步依赖引擎也显著提高了性能。
通过对 3D U-Net 进行一系列优化,我们将 DGX 扩展到 100 个 A100 节点( 800 GPU s ),在 80 个节点( 640 GPU s )上运行训练,在 20 个节点( 160 GPU s )上运行评估。与单节点配置相比, 100 节点的最大规模配置获得了 9 。 7 倍以上的加速比。
目标检测(轻量级)( SSD )
这是轻量 SSD 第四次出现在 MLPerf 中。在这一轮中,评估时间表被改为每五个时代进行一次,从第一个时代开始。在前几轮中,评估计划从第 40 个时代开始。即使有额外的计算要求,我们也将提交时间加快了 x1 。 6 以上。
SSD 由许多较小的卷积层组成。如前所述, MXNet 依赖引擎 CUDA 图的改进以及 SHARP 的启用对基准测试尤其有影响。
更高效的配置
优化评价
更高效的配置
深度学习模型的训练时间是一个多变量函数。在其最基本的形式中,方程式如下:
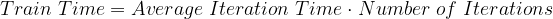
目标是最小化

它和
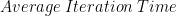
and
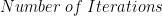
是批量大小的函数。

是单调非减函数。批量大小的计算效率更高,但每次迭代需要更多的时间。
另一方面,
在一定的批量大小下,是一个单调的非递增函数。更大的批量需要更少的迭代来收敛,因为模型每次迭代看到更多的图像。
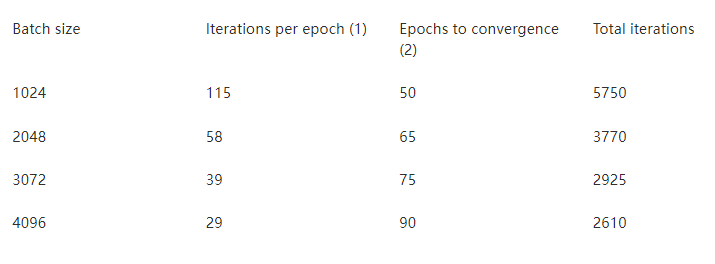
表 2 。使用不同批量大小收敛所需的迭代次数
( 1 ) MS-COCO 历元大小为 117266 张图像 (2 ) 经验值
与我们使用 2048 批量大小的 v0 。 7 提交相比, v1 。 0 批量大小为 3072 ,需要的迭代次数减少了 22% 。因为较大的迭代只慢了 20% ,结果是收敛速度快了 8% 。
在本例中,将批处理大小改为 4096 而不是 3072 将导致更长的训练时间。迭代次数减少 11% 并不能弥补每次迭代额外 20% 的运行时间。
优化评价
评估可分为三个阶段:
Inference :使用经过训练的模型对验证数据集进行预测。在 GPU 上运行。
Prep : [NEED DESCRIPTION]
Scoring :根据基本事实评估推理结果。在 CPU 上异步运行。
v1 。 0 中的新评估为基本提交添加了八个验证周期。更糟糕的是,对 epoch 训练时间的改进意味着得分需要不到 2 秒或 5 个 epoch 的训练时间。否则,它不会被完全隐藏,任何训练时间的改进都是毫无意义的。
为了提高推理时间,我们保证了推理图是静态的。我们改进了非最大值抑制实现,并将用于过滤负检测的布尔掩码移到图的外部。静态图节省了内存重新分配时间,使训练和推理上下文之间的切换更快。
对于得分,我们使用 nv-cocoapi ,这是一个 C ++实现的 cocoapi 和 60X 倍的速度更快。对于 v1 。 0 ,我们通过多线程结果累积、更快的索引排序和缓存基本真相数据结构,将 nv-cocoapi 的性能提高了 2 倍。
目标检测(重量级)( Mask R-CNN )
我们通过以下技术优化了目标检测:
CUDA graphs in PyTorch
删除同步点
异步求值
数据加载器优化
ResNet 层与 cuDNN v8 的更好融合
CUDA graphs in PyTorch
深度学习框架使用 GPU 加速计算,但大量代码仍在 CPU 内核上运行。 CPU 代码处理类似张量形状的元数据,以准备启动 GPU 内核所需的参数。处理元数据的成本是固定的,而 GPU 所做的计算工作的成本与批处理大小正相关。对于大批量, CPU 开销占总运行时成本的百分比可以忽略不计。在小批量时, CPU 开销可能会大于 GPU 运行时。当这种情况发生时, GPU 在内核调用之间处于空闲状态。
此问题可以在 Nsight Systems 时间轴图上确定。下图显示了在绘图前每 – GPU 批大小为 1 的掩码 R-CNN 的“主干”部分。绿色部分显示 CPU 负载,蓝色部分显示 GPU 负载。在这个配置文件中,您可以看到 CPU 在 100% 负载时达到最大值,而 GPU 大部分时间处于空闲状态。 GPU 内核之间有很多空白。

图 13 。遮罩 R-CNN 的右时间轴图
CUDA graph 是一个工具,当张量形状是静态的时,它可以自动消除 CPU 开销。在第一步中捕获所有内核调用的完整图。在随后的步骤中,整个图形通过一个操作启动,消除了所有的 CPU 开销。 PyTorch 现在支持 CUDA 图形,我们使用它来加速 MLPerf 1 。 0 的 Mask R-CNN 。
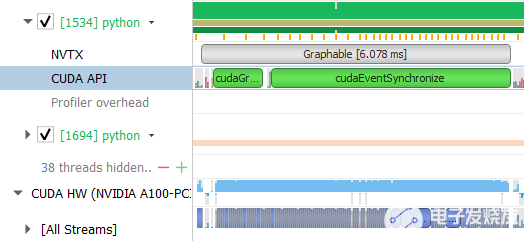
图 14 。 CUDA 图形优化
通过作图,我们可以看到 GPU 内核被紧密打包, GPU 利用率仍然很高。图示部分现在以 6 毫秒而不是 31 毫秒的速度运行,速度提高了 5 倍。我们主要只是绘制 ResNet 主干,而不是整个模型。即使在那时,我们看到整个基准的提升超过了 2 倍。
删除同步点
有许多 PyTorch 模块使主进程等待 GPU 完成之前启动的所有内核。这可能对性能有害,因为当 CPU 可以启动更多内核时,它会处于空闲状态。 CPU 可以在低开销段中领先于 GPU ,并开始从后续段启动内核。只要总的 CPU 开销小于总的 GPU 内核时间, CPU 就永远不会成为瓶颈,但当引入同步点时,瓶颈就会中断。而且,具有同步点的模型段不能用 CUDA 图形表示,因此删除同步非常重要。
我们为 mlperf1 。 0 做了一些工作。例如, Trang 。 RangPrm 改写为使用 CUB 而不是推力,因为后者是同步 C ++模板库。这些改进在最新的 NGC 容器中提供。
删除所有同步将 CUDA 图中的提升从 1 。 6x 提高到 2 。 5x 。
异步求值
我们提交的 mlperf0 。 7 进行了异步评估,但速度不够快,无法跟上优化后的培训。每个历元的评估时间为 18 秒,其中 4 秒是完全暴露的时间。如果不更改评估代码,我们的 at-scale 提交的时间会慢大约 100 秒。
在三个评价阶段中,推理和准备占了所有的暴露时间。为了加快推理速度,我们将测试图像缓存在 GPU 内存中,因为它们永远不会改变。我们将准备阶段移到后台进程池中,因为测试数据集中的每个样本都可以独立处理。我们在两个背景过程中同时对分割模板和框进行评分。这些优化将每个历元的计算时间减少到了~ 4 秒。
数据加载器优化
该组件在训练期间加载和增强图像。在我们提交的 mlperf0 。 7 中,所有数据加载工作都由 CPU 内核完成。旧的 dataloader 不够快,无法跟上优化后的培训。为了解决这个问题,我们开发了一个混合数据加载器。
混合数据加载器对 CUDA 上的图像进行解码,然后使用 Torchvision 对 GPU 进行图像增强。为了完全隐藏数据加载的代价,我们将 loss 后向调用移到主训练循环中的 load next image 调用。由于 CPU 图形启动, CPU 在丢失向后调用后空闲了几毫秒。这是足够的时间解码下一个图像。在 GPU 完成反向传播之后,它们处于空闲状态,而优化器在梯度上进行所有减少。在此空闲时间内, dataloader 执行图像增强工作。
ResNet 层与 cuDNN v8 的更好融合
ResNet50 的基本构造块是一个由卷积、批处理范数和激活函数组成的三层堆栈。对于 maskr-CNN ,批处理范数是冻结的,这意味着批处理范数和激活函数都是可以融合的逐点操作。
在前几轮中,我们使用 PyTorch JIT fuser 来融合两个逐点操作。多亏了 cuDNN v8 中的新融合引擎,我们通过将逐点运算与卷积融合在一起对其进行了改进。 fusion 引擎灵活的 API 还使我们能够在一个 autograd 函数下融合所有三个基本层。这让我们可以绕过定影器的限制,在反向传播中进行不对称融合,以获得更大的性能提升。
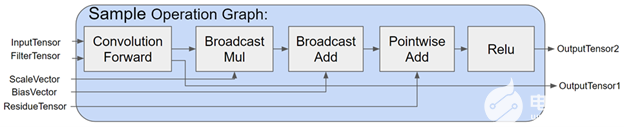
图 15 。 cuDNN 图形 API 将高级 DL 层融合用例降低为细粒度的 CUDA 内核图形
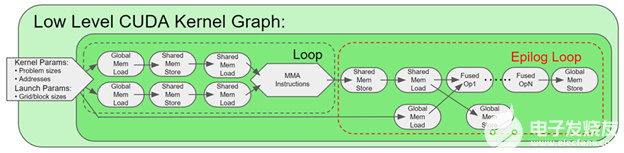
图 16 。细粒度的 CUDA 内核图被进一步转换为一个高效的张量核融合内核
语音识别( RNN-T )
RNN-T 语音识别是这一轮 MLPerf 训练中的又一项新任务。我们使用了以下优化:
顶点传感器损耗
顶点传感器接头
序列分裂
批量拆分
用 CUDA 图进行批量评估
cuDNN v8 中更优化的 LSTMs
顶点传感器损耗
RNN-T 使用一种特殊的损耗函数,我们称之为传感器损耗函数。计算损耗的算法本质上是迭代的。由于不规则的内存访问模式和暴露的长内存读取延迟,简单的实现通常效率低下。
为了克服这个困难,我们开发了 apex.contrib.transducer.TransducerLoss 。它采用了一种类似于对角线波前的计算范式来开发算法中的并行性。共享内存和寄存器广泛用于缓存迭代之间交换的数据。 loss 函数还使用预取来隐藏内存访问延迟。
顶点传感器接头
另一个经常出现在传感器类型网络中的组件是传感器联合操作。为了加速这个操作,我们开发了 apex.contrib.transducer.TransducerJoint 。这个 Apex 扩展不仅比其本机的 PyTorch 扩展快,而且还支持输出打包,减少了后续层的工作负载。
图 17 显示了顶点传感器接头的填料操作。在基线联合操作中,由于联合操作与输入填充无关,因此输入序列中的填充被转移到输出。在顶点传感器联合操作中,输出端的填充被移除,减小了馈送给后续操作的张量的大小。
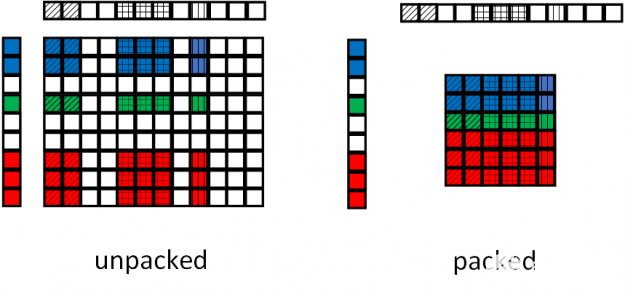
图 17 。 Apex 传感器接头填料操作
序列分裂
为了减少填充物上浪费的 LSTM 计算,我们将批处理分为两个阶段(图 18 )。在第一个过程中,对小批量中的所有样本进行评估,直到特定的时间步(用黑框括起来)。小批量样品的一半在第一次通过时完成。另一半样本的剩余时间步长(用红色框括起来)在第二遍中进行评估。用蓝色框括起来的区域表示批量拆分的节省。
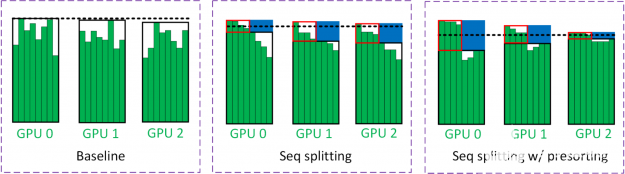
图 18 。序列分裂
图 18 中的黑色虚线估计了 GPU 所看到的工作量。因为第二遍的批处理大小减少了一半, GPU 看到的工作负载大约减少了一半。在 multi- GPU 训练中,通常是最慢的 GPU 限制了训练吞吐量。虚线是从具有大多数工作负载的 GPU 中获得的。
为了减轻这种负载不平衡,我们采用了一种称为预排序的技术,即根据序列长度对小批量中的样本进行排序。最长和最短的序列放在同一个 GPU 上以平衡工作负载。这背后的直觉是,具有长序列的 GPU 可能是瓶颈。因此,短序列也应该放在这些 GPU 上,以最大限度地发挥序列分裂的优势。
批量拆分
RNN-T 有一个有趣的网络结构,其中 LSTM 处理相对较小的张量,而联合网络则处理更大的张量。为了使 LSTMs 能够更有效地以大批量运行,同时不超过 GPU 内存容量,我们采用了一种称为批处理拆分的技术(图 17 )。我们使用了一个相当大的批量大小,这样 LSTMs 就获得了相当高的 GPU 利用率。相比之下,联合网络对批处理的一部分进行操作,并逐个遍历这些子批。
在图 19 中,使用了 2 的批次分割因子。在这种情况下,输入到 LSTMs 和联合网的批量大小分别是 B 和 B / 2 。因为在反向传播完成后,除了权值的梯度之外,关节网络生成的所有张量都不再需要,所以可以释放它们并为循环中的下一个子批次创建空间。
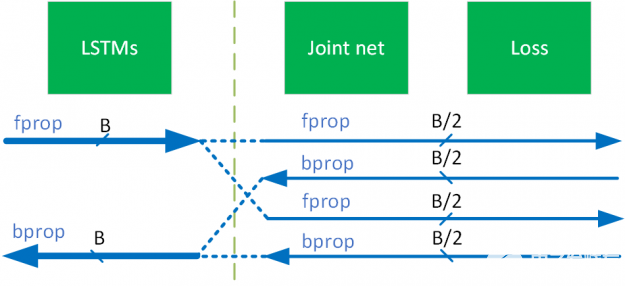
图 19 批量拆分
用 CUDA 图进行批量评估
除了加速训练, RNN-T 的评估也被仔细审查。 RNN-T 的评估本质上是迭代的,预测网络的评估是逐步进行的。批处理 MIG 中的每个示例在同一时间步中选择不同的代码路径,具体取决于执行结果。因此,简单的实现会导致较低的 GPU 利用率和较长的评估时间,与培训本身相当。
为了克服这些困难,我们在评估中进行了两类优化。第一个优化在批处理模式下执行评估,并使用谓词处理批处理中的不同控制流。第二个优化绘制了主 RNN-T 评估循环,该循环由许多短 GPU 核组成。我们还使用循环展开和重叠 CPU – GPU 通信与 GPU 执行来分摊相关的开销。优化后的评估速度比单节点配置的参考代码快 100 倍以上,比最大规模配置快 30 倍以上。
cuDNN v8 中更优化的 LSTMs
LSTM 是 RNN-T 的主要构造块。端到端网络时间的很大一部分花在 LSTMs 上。在 cuDNN v8 中, LSTMs 的性能得到了极大的优化。例如,将更好的水平融合算法和启发式算法应用于 LSTM 单元中的 gemm 和 LSTM 层之间的 drop-out ,提高了性能并减少了 drop-out 带来的开销。
概括
MLPerf v1 。 0 展示了人工智能领域的不断创新。 NVIDIA 人工智能平台通过硬件、数据中心技术和软件的紧密集成,提供领先的性能,以充分发挥人工智能的潜力。
自第一个 MLPerf 训练基准启动以来的过去两年半时间里, NVIDIA 性能提高了近 7 倍。 NVIDIA 平台在性能和可用性方面都非常出色,提供了从数据中心到边缘再到云的单一领导平台。
所有用于 NVIDIA 提交的软件都可以从 MLPerf 存储库获得,以使您能够重现我们的基准测试结果。我们不断地将这些最前沿的 MLPerf 改进添加到我们的深度学习框架容器中,这些容器可以在 NGC 上找到,它是我们的 GPU 优化应用程序的软件中心。
关于作者
Vinh Nguyen 是一位深度学习的工程师和数据科学家,发表了 50 多篇科学文章,引文超过 2500 篇。在 NVIDIA ,他的工作涉及广泛的深度学习和人工智能应用,包括语音、语言和视觉处理以及推荐系统。
Sukru Burc Eryilmaz 是 NVIDIA 计算机体系结构的高级架构师,他致力于在单节点和超级计算机规模上改进神经网络训练的端到端性能。他从斯坦福大学获得博士学位,并从比尔肯特大学获得学士学位。
Davide Del Testa 是 NVIDIA 汽车解决方案架构师团队的成员,他支持客户构建基于 NVIDIA 驱动平台的自主驾驶架构。在此之前,他是 NVIDIA 的深度学习研究实习生,在那里他应用深度学习技术开发 BB8 , NVIDIA 的研究工具。 Davide 拥有应用于电信的机器学习博士学位,他在网络优化和信号处理领域采用了学习技术。他在意大利帕多瓦大学获得电信工程硕士学位。
Shar Narasimhan 是 AI 的高级产品营销经理,专门从事 NVIDIA 的 Tesla 数据中心团队的深度学习培训和 OEM 业务。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5727浏览量
110296 -
数据中心
+关注
关注
18文章
5845浏览量
75251 -
人工智能
+关注
关注
1821文章
50518浏览量
267765 -
MLPerf
+关注
关注
0文章
37浏览量
993
发布评论请先 登录
RS485 Sensor Node V1.0:工业物联网的得力助手

嵌入式系统中的人工智能

物理人工智能面临的安全风险
【产品介绍】Altair RapidMiner数据分析与人工智能平台




评论