 Merlin HugeCTR分级参数服务器:缓存和在线更新设计
Merlin HugeCTR分级参数服务器:缓存和在线更新设计

1. 概述
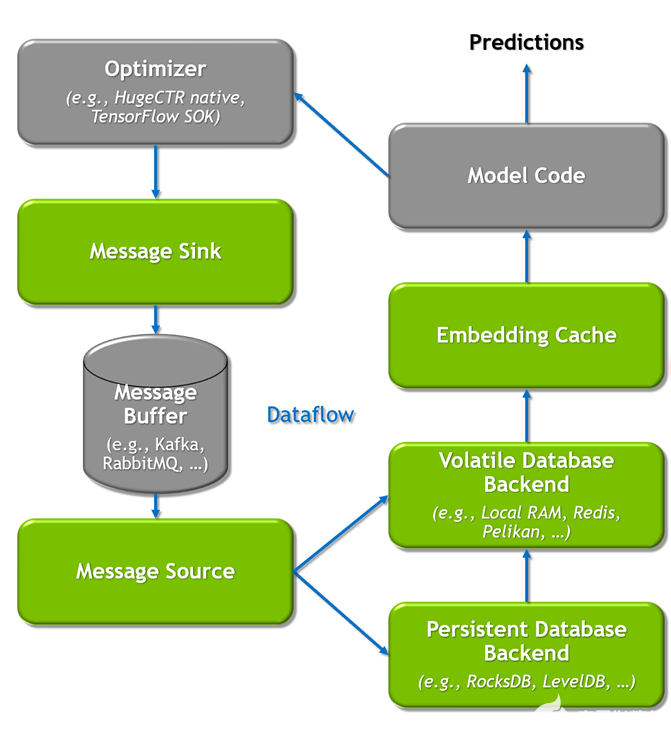
HPS 数据后端作为 GPU embedding 缓存架构的基石,同时也是 GPU embedding 缓存在 CPU 内存以及本地磁盘的进一步物理扩展。HPS 数据后端通过绑定不同物理层级的存储从而提供了大型模型 embedding table 的缓存,查询,更新以及容错等服务,目的即为了保证在推理服务中 GPU embedding 缓存的高命中率,从而提高推理服务的吞吐大幅度降低端到端的延迟。
2. Volatile 数据后端
Volatile 数据后端以 RAM Memory 作为主要存储介质,提供本地或者远端更加快捷的参数读写服务。既可以作为 GPU embedding 缓存的扩展,也可以作为本地磁盘的(Persistent 后端)缓存。由于 Persistent 数据后端的存储容量可以理解为无限巨大,但是同时也就意味着在实际的推理服务中的读写速度也是相对较慢的。因此 Volatile 数据后端弥补了 Persistent 数据库的缺陷,极大扩展了有限的 GPU 内存。但是 Volatile 数据库的容量本质上也是有限的,因此我们通过实现参数的分区,驱逐以及共享进一步提高 RAM Memory 带来的上限。
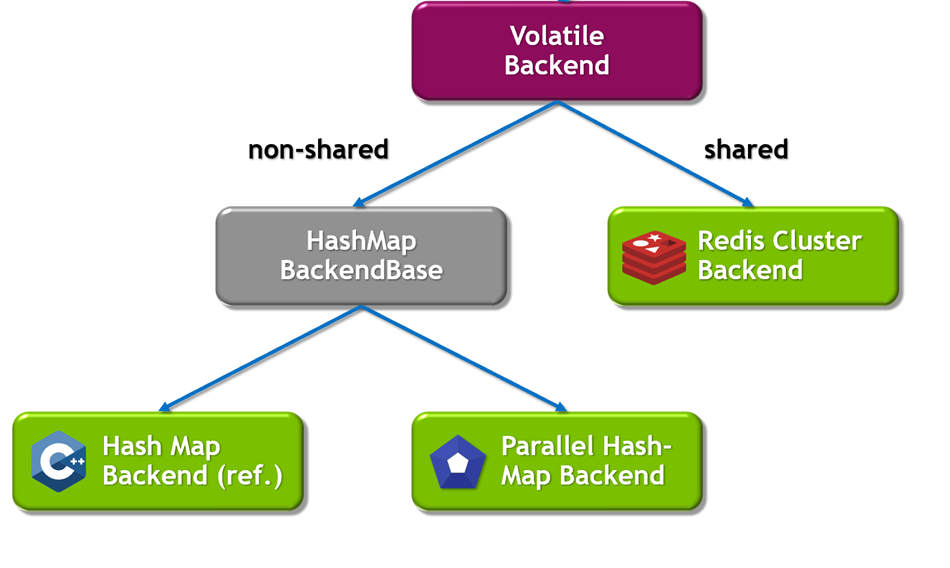
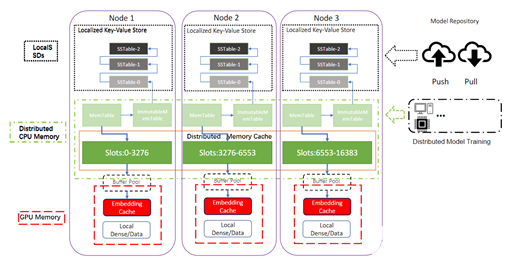
为了保证 Volatile 数据后端可以适用于更广泛的推荐部署场景,我们同样实现了针对不同场景的本地化或者分布式存储机制。从下图中我们可以看到,针对 HashMap 此类常规的存储结构,通过实例化 Volatile 数据后端,可以保证每个数据节点都将拥有一个独立本地化的存储实例。对于本地化的 Volatile 数据后端,我们不仅实现了分区优化的 HashMap 结构,还实现了高性能的 Parallel HashMap 数据结构,进而大幅度提升了本地参数的查询和读写服务。
与之相反的,则是分布式共享 Volatile 数据后端,分布式的数据后端将参数通过逻辑分区保存在不同的网络节点,即 Redis Cluster(既可以将参数分布式存储在远端的数据节点,同样也可以是相同的推理节点)。通过使用集群中共享 RAM 内存进行参数的存储和读写,进一步扩大了 Volatile 数据库容量,也提供了 Redis 持久化特性(RDB 和 AOF 等 ),从而使得跨节点重启之后的读写操作可以无缝进行。 由于共享的机制,也实现了 HugeCTR 模型训练到推理的参数无缝更新。
为了最大限度地提高性能并避免由零星 RAM memory 在 Volatile 数据后端中的高效使用(即内存不足的情况),我们提供了溢出处理机制。 它允许限制每个分区存储的最大嵌入量,从而限制分布式数据库的内存消耗。当前我们允许用户配置不同的驱逐更新策略(随机驱逐以及 LRU)来保证内存最大限度的利用。对于本地化的参数分区以及查询机制,用户可以对数据后端显式的配置分区数量以及分区大小来更加细粒度的提高数据后端的查询读写服务。具体来说,用户可以通过配置 max_get_batch_size,max_set_batch_size 以及并发线程数来精准控制读写开销。
具体参数配置信息可以参考 HPS 配置详解:https://github.com/triton-inference-server/hugectr_backend/blob/main/docs/hierarchical_parameter_server.md#6-configuration
3. Persistent 数据后端
Persistent 数据后端以本地 SSDs 作为持久化存储介质,维护一个完整的模型参数部分,同时承载着模型参数的容错的功能。相对于 GPU embedding 缓存与 Volatile RAM 缓存,Persistent 数据后端可以看作是一个拥有无限虚拟空间的存储后端,同时也作为一个本地化的 Key-value 查询引擎,在此我们引入了性能优化后的 RocksDB 作为 Persistent 后端的实现。
每个推理节点通过 HPS 的配置文件即可在本地磁盘保留所有模型 embedding table 的独立完整副本。 Persistent 数据后端也是对分布式 Volatile 数据后端的进一步补充:1) 进一步扩展存储容量的同时, 2) 实现高可用性。 特别是对于超大规模的模型(甚至超过了分布 Redis Cluster 的总 RAM 容量),或者由于网络带宽等硬件限制造成 Redis Cluster 不可用,RocksDB 的分成存储结构 同样可以完全满足高并发参数查询请求。
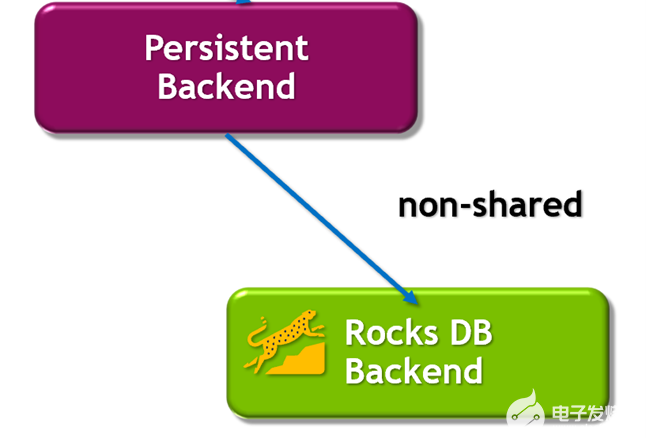
针对 Persistent 后端的 Rocksdb 会以分块查询机制来获取最大性能。针对不同的硬件基础设施,用户可以进行定制化的配置,从而保证硬件资源的利用率以及推理性能的最大化。
4. 流式增量更新
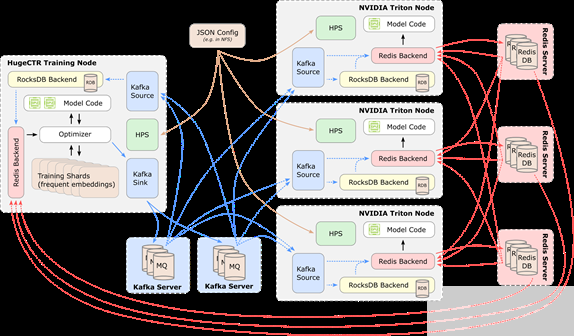
通过优化后 Kafka 的发布更新机制,推理节点中的每个 HPS 实例所对应的不同层级的数据后端通过订阅对应模型的 Topic,消费实时的增量模型参数,实现模型的异步更新。在具体实现中,我们提供两个简单易用的抽象接口,分别是 MessageSink 和 MessageSource,保证了增量模型从训练端向推理端的无缝更新。
用户可以通过 JSON 格式的配置文件,任意组合搭配适用于部署场景的数据后端,保证每个部署节点充分的利用上文所提到的所有存储介质。由于 HPS 是构建于 Triton 推理架构之上。正如下图所展示的完整 HPS 训练推理数据流示意图,每个 Triton 节点通过 Volatile 数据后端既可以维护高性能的本地 RAM 缓存,同时也可以负责维护对应 Redis 节点的参数分区,Redis cluster 中的分区参数既可以通过训练与推理集群共享,也可以通过订阅 Kafka 数据源来实现无缝的参数更新。模型在 HugeCTR 训练平台可以实时将在线训练中的增量模型推向分布式的 Kafka 队列,相同 JSON 配置的推理节点会自动检测和监控消息队列,从而保证了推理节点的 Persistent 数据后端始终维护完整的最新版本的参数副本,为推理服务的容错提供了保障。
5. 结语
在这一期的 HugeCTR 分级参数服务器介绍中,我们介绍了 CPU 分布式缓存,本地缓存,以及在线更新的设计细节。在下一期中,我们将着重介绍 HugeCTR 分级参数服务器中最关键的组件:Embedding Cache 的设计细节,敬请期待。
关于作者:
About Yingcan Wei
GPU计算专家,毕业于香港大学,HugeCTR算法组负责人。当前主要从事HugeCTR的算法设计与推理架构工作。研究领域包括深度学习域适应,生成对抗网络,推荐算法设计优化。在2020年加入英伟达前,任职于欧美外资以及互联网等企业,拥有多年图像处理 、数据挖掘,推荐系统设计开发相关经验。
About Matthias Langer
Matthias 在西门子担任工厂自动化软件和机器学习方面的调试专家多年。 2019 年,他在拉筹伯大学(墨尔本)获得计算机科学博士学位,以表彰他在带宽受限环境中的分布式深度学习方面的工作。 Matthias 与澳大利亚体育学院 (AIS) 为东京奥运会开发了一种用于视频分析的新型 AI 系统,并开发了算法来帮助澳大利亚移动电话网络中的负载预测。此外,他曾在中国领先的技术招聘平台 BOSS 直聘北京研究中心担任机器科学家,直至 2021 年 6 月首次公开募股。 在 NVIDIA,Matthias 是上海 DevTech APAC 团队的一员,该团队负责开发 NVIDIA HugeCTR。 Matthias 的工作重点是分发、并行化和性能优化算法,这些算法使 HugeCTR 成为世界上用于推荐模型训练和推理的最快和最具可扩展性的系统之一。目前主要负责 HugeCTR 的分布式嵌入存储和检索模块的实现、维护和扩展。
About Jerry Shi
本科毕业于加州大学伯克利分校,在康奈尔大学获得硕士文凭。于2021年加入英伟达,在Merlin HugeCTR团队算法组负责推荐系统架构与算法的相关设计及开发。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11382浏览量
226559 -
gpu
+关注
关注
28文章
5339浏览量
136281 -
服务器
+关注
关注
14文章
10467浏览量
91890
发布评论请先 登录
播出服务器磁盘I/O与缓存性能分析
缓存服务器运作的原理解析
Skylaking服务器升级 支持Optane缓存和GPU

Merlin HugeCTR V3.4.1版本新增内容介绍
GPU加速的推荐程序框架Merlin HugeCTR
Merlin HugeCTR 分级参数服务器简介
如何使用NVIDIA Merlin推荐系统框架实现嵌入优化



评论