 OPPO造芯,首推6nm影像专用NPU芯片剑指夜景视频
OPPO造芯,首推6nm影像专用NPU芯片剑指夜景视频

(电子发烧友/程文智)火热的芯片市场又迎来了一个新玩家。12月14日,OPPO在主题为“致善·前行”的OPPO 2021年度未来科技大会(OPPO INNO DAY 2021)上正式发布了其首款影像专用NPU——马里亚纳 MariSilicon X芯片。该芯片采用了DSA架构和台积电的6nm工艺,算力和能效比十分均衡,同时还融合了OPPO积累多年的影像处理技术,将计算影像推向了4K+20bit RAW+AI+Ultra HDR的新极限。

图:OPPO芯片产品高级总监姜波在介绍马里亚纳 MariSilicon X芯片
据悉,在新NPU的支持下,夜景视频将会有新的突破,搭载马里亚纳 MariSilicon X的手机将可以在4K AI HDR视频中实现超清夜景照片的清晰画质,让视频的每一帧都是一张好照片。那么,MariSilicon X是如何实现夜景视频的优秀性能的呢?让我们看看这颗芯片到底有何过人之处。
MariSilicon X芯片的主要架构和核心参数
马里亚纳 MariSilicon X采用的是DSA(Domain Specific Architecture)新黄金架构理念,里面包括了两大核心IP:MariNeuro AI计算单元和MariLumi影像处理单元。还有专为MariNeuro AI计算单元配置的双层存储架构,包括万亿比特每秒(Tb/s)读写速度的片上内存子系统,以及8.5GB/s的独立DDR带宽,为AI的高效运算提供充足的内存读写支持。
所谓的DSA架构,就是一种更加以应用场景为中心的设计思路,通过特殊的计算架构,为解决特定领域的问题提供强大且高效的性能。DSA架构尤其适用于AI领域。通俗地讲,就是专芯专用,设计出来的芯片不是解决所有问题,而是解决特定的一类问题,从而满足对效率的需求。
也就是说,马里亚纳 MariSilicon X就是一颗专为影像而生的NPU芯片,它只做一件事,那就是把影像做到极致。它的具体核心配置可以参考表1。
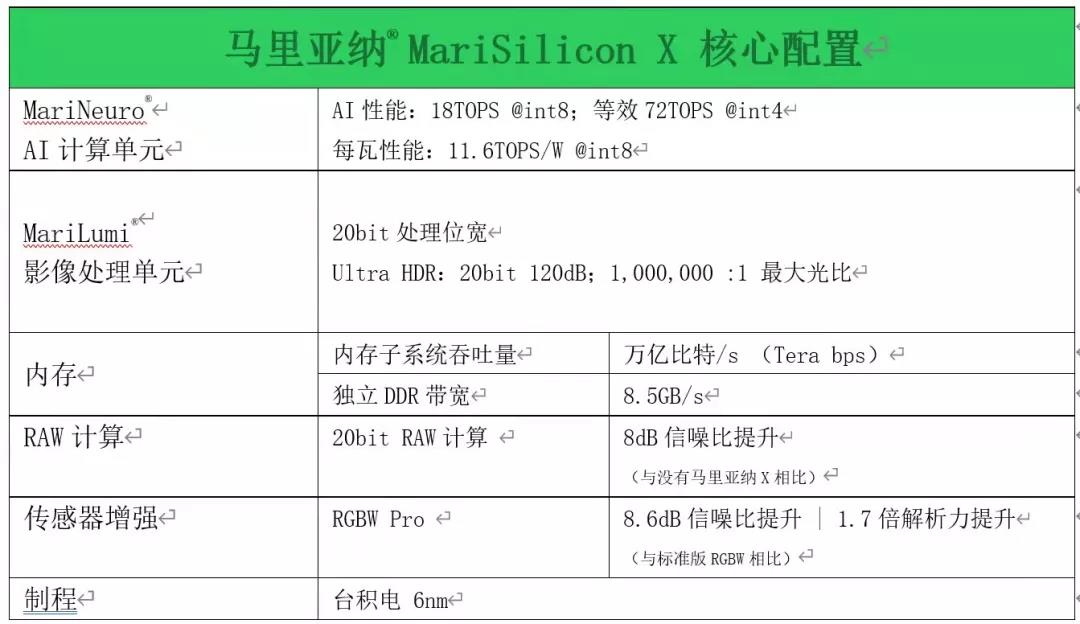
表1:MariSilicon X的核心配置。
专芯专用,跨越算力鸿沟
OPPO芯片产品高级总监姜波表示,基于DSA的设计理念,OPPO将专用的AI算法进行了芯片化,在芯片的底层硬件中,直接嵌入了适合这一算法的算子。MariNeuro AI计算单元就是专门用来实现像素级图像处理的,它的有效算力高达18TOPS,每秒可以进行18万亿次的运算。
众所周知,算力是一切计算的基础,而在手机影像的应用中,算力一般分为四个等级,分别是场景感知、场景重构、像素级处理和多维度立体图像处理。AI在影像领域的不同的应用场景中,对算力有着不同的需求。
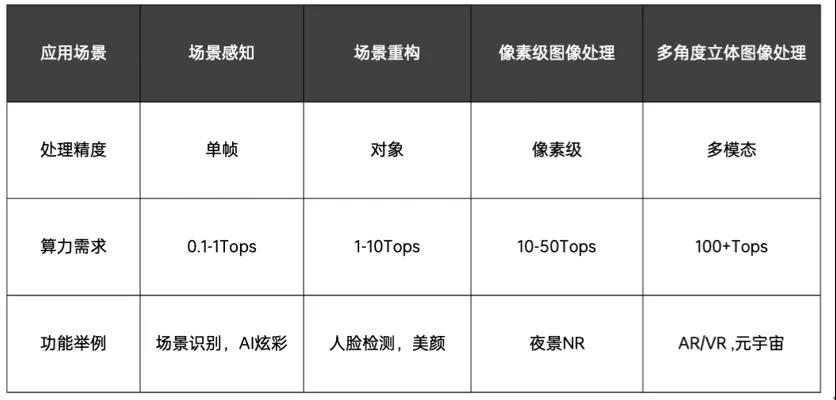
图:AI在影像领域的不同应用场景对算力的需求。(来源:OPPO)
传统的计算摄影由于算力的限制,只能做到场景重构这一层级,比如大部分手机目前对于人像处理时采用的人脸检测和美颜的计算。想要更进一步,逐个像素对图像进行处理,乃至未来对AR/VR的三维图像进行实时处理,高算力是必不可少的。“根据OPPO的测试经验,实现像素级的图像处理至少需要10-50TOPS级别的算力。”姜波表示。
他同时强调,堆砌算力并非重点。算力往往可以通过提升计算主频或者增加计算核心数量来粗暴地实现,而更具挑战的是在手机的功耗发热约束之下依然能够实现高算力,这就是能效比的重要性。

马里亚纳 MariSilicon X 的能效比就达到了11.6 TOPS/W,这也是手机AI能效罕见地实现了双位数的每瓦性能,是手机NPU芯片AI能效新的里程碑。
在OPPO的实际测试中,采用了OPPO自研的AI降噪算法(这一算法目前已经应用在了Find X3 Pro的夜景拍照中)。在实际的测试中,这样的算法加载在Find X3 Pro上,AI的性能只能做到2fps,而功耗则接近1.7W;这样的帧率,完全不够视频最低的30fps的要求。而1.7W的功耗,也远远超出了手机对视频处理的最高功耗要求。

而同样的模型加载在马里亚纳 MariSilicon X的时候,可以做到40fps的运行速度,同时功耗只有不到0.8W,这样的性能是20倍的提升,功耗则不到之前的一半。“越专用,越高效,在这组实测数据中得到了最好的体现。”姜波分享说。
除了算力,AI神经网络的处理速度还受限于内存的容量和读写速度,也就是行业常说的冯·诺依曼“内存墙”瓶颈。计算单元的运算速度和传输速度就像一个木桶中的不同木板,最短的那个限制了计算单元的能力。
为了更好地发挥马里亚纳 MariSilicon X的运算能力,OPPO非常奢侈地集成了双层存储架构,包括万亿比特每秒(Tb/s)级读写速度的片上内存子系统,以及8.5GB/s的独立DDR带宽,为AI的高效运算提供充足的内存读写支持。

片上内存子系统集成在AI计算单元MariNeuro上,只服务于与AI运算相关的数据吞吐,最高可以提供数十倍于目前手机中最先进的LPDDR5的数据传输速度,极大程度地降低数据在存储与计算两个单元的繁复读写,让AI数据在计算的时候不需要离开AI计算单元,这就能大幅降低计算时的功耗。
不仅如此,马里亚纳 MariSilicon X独立的DDR带宽专门为芯片内的各个IP提供独立带宽,也在SoC的基础上,增加了17%的系统总带宽。
此外,OPPO还为内存子系统和独立DDR带宽设计了分层结构与多行并行流程,保证图像数据在MariLumi影像处理单元与MariNeuro AI计算单元间的输入与输出可以实现最低的时延,降低因反复读写数据造成的功耗,令视频处理更快更高效。
AI降噪算法前置,带来更优画质
马里亚纳 MariSilicon X里面另外一个重要的自研IP——MariLumi 影像处理单元,它针对视频流趋势进行了独特设计,能够流畅地面向4K规格的视频数据量进行计算。像素级的处理速度也让智能HDR融合算法可以在这颗单元的前端运行,最终令画面动态范围达到了20bit 120db(20 stops),相比Find X3 Pro提升4倍,达到20bit Ultra HDR超级动态范围。20bit-120dB意味着对于一张图片而言,最暗和最亮的部分相差100万倍。

姜波指出,OPPO通过该芯片的HDR能力,可以将原来只属于白天的动态范围,首次拓展到在夜间视频上。相比Find X3的方案来看,马里亚纳 MariSilicon X处理后的视频画面更自然,动态范围达到人眼可分辨的极限。
其实,从镜头到最终存储的影像,是一个数据不断压缩的过程。具体来看,影像处理过程中涉及3个空间,RAW-RGB-YUV,数据每经过一次转换,就会受到一定损失。
RAW是原始数据的空间,这里承接的是从传感器光电转换得来的所有无损数据,有着更丰富的信息量和更大的数据量。但RAW域的图像信息是无法直接观看的,必须在RGB域“上色”,再输出到YUV域进行格式转化,最后生成JPEG/HEIF等可在屏幕上观看的格式。

RAW有一个好处就是它的线性度、色彩比较好,有更原始的信息,所以在RAW上处理,可以得到更好的处理效果。但算法复杂度、实际相应的硬件投入都会更多。因此,传统的HDR都选择在YUV里合成。
而马里亚纳 MariSilicon X将传统在后端的处理前置到了RAW域,并且因为强大的算力,最高可以支持20bit位宽的RAW数据处理。而且是基于更先进的AI算法和20bit HDR融合的计算,对每个像素做实时的计算。
通过算法前置,MariSilicon X能够为整个链路带来最多8dB的信噪比提升,这意味着在YUV等待计算的通用平台,拿到的也是更优质的图像信息,就能够在后处理,比如色调映射、3A校准等基础计算实现更高质量的表现。
打破影像的不可能三角
人工智能的三要素是数据、算力和算法,对应到计算影像上来说就是传感器、芯片和AI算法,这三者环环相扣,缺一不可。但行业主要面临的问题,就是传感器、芯片和算法的技术发展不同步。一般来说,芯片的开发周期基本需要两年以上,传感器则是一年一代更新迭代,而算法开发和训练所需的时间则更短,这就意味着很难有厂商可以将三者在一个时间节点上完美调优。
此外,在传统的技术生态中,传感器、芯片和影像算法会由产业链中不同领域的公司负责。假设有企业要做一颗芯片,通常的做法是去找专业的算法公司来购买算法,再找一个前端公司做芯片的逻辑设计,很少有公司会负责所有部分。这样做在公司运营和成本方面好处有很多,但也带来了用户体验上的问题——无法耦合各个模块,也就无法将指标做到最优。
完美打通算法、芯片和传感器是行业中长期以来都无法解决的问题,“我们称之为手机影像的「不可能三角」。”姜波解释称。

如今,OPPO通过自己在影像领域的技术和算法积累,再加上近年来逐步建构起的芯片设计能力,通过自研芯片和自研算法的整合,自研芯片和深度定制传感器的配合,以及自研芯片和通用平台的打通,打破手机影像的不可能三角。
RGBW Pro模式就是打破手机影像的不可能三角最好的例证。通过双通路设计,马里亚纳 MariSilicon X实现了对RGB和W像素的分隔处理,最大化利用每一种像素特性,释放出RGBW阵列的全部潜力。马里亚纳 MariSilicon X的RGBW Pro模式带来了8.6dB的信噪比提升,以及1.7倍的解析力提升,在传感器尺寸规格都没有变化的前提下实现大幅的影像效果增强。

四项能力突破,解决夜景视频画质问题
得益于前面提到的技术,马里亚纳 MariSilicon X获得了四项关键的技术能力,即(1)强大的AI计算能效;(2)领先行业的Ultra HDR;(3)无损的实时RAW计算;(4)最大化传感器能力的RGBW Pro。而这思想能力的突破,让OPPO可以解决手机影像长期尚未解决的难题——夜景视频画质的问题。
在全新标准之下,安卓影像第一次有能力同时支持4K + 20bit RAW + AI + Ultra HDR的极限规格。最终的结果,就是夜景视频的画质得到了质的提升。
从1080P到4K:传统弱光下的视频拍摄,只要打开AI视频增强,由于算力所限,画质被限制在1080P。马里亚纳 MariSilicon X超强AI性能将分辨率提升了4倍,首次让AI计算夜景视频达到4K规格。
从有损到无损:相较于传统计算影像都发生在YUV域的有损后处理,马里亚纳 MariSilicon X将复杂的计算前置在RAW域,为整体影像链路输出更高质量的原始图像信息。
从AI拍照到AI视频:马里亚纳 MariSilicon X也让原本只能用于拍照的AI降噪算法,首次拓展到了视频应用,为视频的每一帧带来极高的纯净度。
从18bit HDR到20bit Ultra HDR:马里亚纳 MariSilicon X支持的画面动态范围达到了20bit Ultra HDR,是目前主流平台18bit的4倍(2的20次方与2的18次方相比),信噪比达到120db,让视频的每一帧都拥有和人眼一致的动态范围。
结语
总的来说,马里亚纳 MariSilicon X是一颗极致功耗的NPU,结合20bit的HDR,RAW处理、以及RGBW传感器的耦合,加上OPPO多年来在影像技术方面的探索和影像算法方面的积累,将视频拍摄推向了一个新的高度。
以前,手机上只能做YUV的1080p的AI降噪处理,有了马里亚纳 MariSilicon X的助力后,4K的AI在RAW上实现了可能,让用户体验有了4倍的提升。也就是说,有了马里亚纳 MariSilicon X后,不论是拍照,还是录视频;也不论是拍夜景,还是录夜景视频,用户都将得心应手。

一般来说,消费类电子产品使用的芯片是一年一升级,明年的马里亚纳 MariSilicon X是否会推出其第二代产品呢?姜波回应称,对于下一代产品,目前已经在探索中了。
最后,姜波透露说,马里亚纳 MariSilicon X芯片将会首先搭载在Find X系列手机上,预计明年一季度就可以与广大用户见面,请大家拭目以待。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
OPPO
+关注
关注
20文章
5303浏览量
85344 -
NPU
+关注
关注
2文章
386浏览量
21347
发布评论请先 登录
相关推荐
热点推荐
拥抱赋能OpenClaw智能生态,此芯科技CIX ClawCore螯芯系列芯片震撼首发
科技创始人、CEO孙文剑介绍,螯芯系列覆盖端侧AI、边缘AI、高性能等不同AI开发及应用场景,以独创的产品优势赋能开发者快速创新,重构AI应用的开发与交付体验。基于螯芯系列芯片,此

理想AI眼镜Livis重磅发布,黑芝麻智能AI影像解决方案强势赋能
12月3日,理想汽车首款AI眼镜Livis正式亮相,引发业界与市场的广泛关注。此次,黑芝麻智能与理想深度合作,打造AI影像解决方案,涵盖HDR融合、MFNR多帧降噪、视频EIS防抖、夜景增强、人像

基于米尔MYC-LR3576开发板的实时视频识别系统设计与实现
基于米尔MYC-LR3576开发板的实时视频识别系统设计与实现
摘要本文基于米尔电子MYC-LR3576开发板(搭载瑞芯微RK3576处理器)的硬件平台与Debian 12操作系统,构建了一套高
发表于 12-01 21:23
国产芯片真的 “稳” 了?这家企业的 14nm 制程,已经悄悄渗透到这些行业…
最近扒了扒国产芯片的进展,发现中芯国际(官网链接:https://www.smics.com)的 14nm FinFET 制程已经不是 “实验室技术” 了 —— 从消费电子的中端处理器,到汽车电子
发表于 11-25 21:03

OPPO Pad 5搭载MediaTek天玑9400+芯片
OPPO Pad 5 搭载 3nm 先进制程的天玑 9400+ 旗舰芯,全大核架构设计,内建大容量高速缓存,以更高的单线程和多线程任务处理性能,带来令人惊叹的日常应用、游戏等全场景应用体验,内置
OPPO Find X9系列搭载MediaTek天玑9500芯片
OPPO Find X9 系列搭载天玑 9500 旗舰芯,该芯片采用第三代全大核架构设计,凭借其先进的第三代 3 纳米制程,在端侧 AI、专业影像、主机级游戏体验以及网络通信等方面提供
瑞芯微这几年为啥那么火?
还支持8K视频编解码。
异构计算架构:瑞芯微很多CPU采用“CPU+GPU+NPU”异构计算架构,例如旗舰芯片RK3588集成8核CPU、高性能GPU和
发表于 10-20 15:50
12 路 1080P 满负载!米尔 RK3576 补全车载 360° 全景影像视野
RK3576 开发板的价值,不止于 12 路 1080P 流的 “处理与显示”,更通过内置 6TOPS 算力 NPU,让全景影像从 “被动观察” 升级为 “主动预警”:
· 基于 12 路视
发表于 09-11 17:16
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
RK3576:6TOPS NPU 的能效比标杆,重新定义中端 AIoT 旗舰作为瑞芯微 2024 年推出的 AIoT 核心平台,RK3576 基于 8nm 制程打造,集成
发表于 08-29 18:08
创新突破 | 度亘核芯推出高功率1470nm/1550nm半导体激光单管芯片
度亘核芯推出1470nm和1550nm两大波长系列芯片,其额定输出功率达到7.5W,创业界新高!基于度亘核芯强大的平台化技术优势,形成了5.

WAIC 上,国产 6nm ARM 架构 CPU 在端侧 AI 领域遍地开花
万众瞩目的 2025 世界人工智能大会(WAIC 2025)上,此芯 P1 系列芯片集中亮相,交出了一份在端侧 AI 落地方面的成绩单。 作为高能效异构 SoC,此芯 P1 基于6nm
发表于 07-30 09:58
•6965次阅读

砺算6nm GPU与RTX 4060差距大?官方回应来了
电子发烧友网综合报道 根据Geekbench的最新信息,砺算科技首款6nm GPU G100在OpenCL通用计算测试中得分为15,524分。这一成绩与13年前的英伟达GTX 660 Ti(约
又一颗国产GPU芯片成功点亮!6nm制程,自研TrueGPU架构
款GPU芯片G100采用6nm制程,基于自研的TrueGPU架构,这是全球首个融合高性能图形渲染与AI推理能力的GPU架构。其核心优势在于通过unified shader+tensor engine
发表于 05-29 00:48
•2802次阅读
瑞芯微NPU使用攻略
核心要点:定义与功能硬件加速单元:RKNPU是集成在瑞芯微芯片中的专用NPU,专注于加速深度学习算法,如图像识别、目标检测、语音处理等,同时优化功耗与性能平衡。支




评论