 采用硬件加速实现的基本思维有哪些
采用硬件加速实现的基本思维有哪些

很多图像算法不涉及对颜色的识别,仅需要识别灰度目标的变化即可,因此很多时候需要将彩色图像转换为灰度图像,在进行进一步的处理。彩色转灰度计算公式如下:Y=0.299*R + 0.587*G + 0.144*B,作者以05年的嵌入式系统计算,采用640*480的图像进行试验,一系列的图像优化如下(只是类比,不要太在意数据):
1)一维数组索引比三维快,因此先将RGB三维数组转成一维数组,再直接用上述公式进行计算,嵌入式系统计算时间为120秒;
2)由于Windows位图是ARGB8888的精度,因此计算结果仅需要8bit整形,可忽略小数,假定左右扩大1000倍去转定点计算,则新的公式如下:Y=(299R + 587*G + 144*B)/1000,此时嵌入式系统计算时间加快到45秒;
3)除法计算太慢,扩大2N次方可转移位操作,假定扩大4096倍转定点,则新的公式如下:Y=(R*1224+G*2404+B*467)>>12,计算进一步加快到30秒;
4)由于RGB的取值是固定的[0,255],因此公式中每一步运算其实都可以提前计算好,然后直接索引——查找表,这样将执行计算转换成了执行索引,此时再测试计算速度惊人的提升到了2秒;
5)接着作者再马力全开,采用2个ALU并行计算,并且将查找表从int型改成unsigned short型,以及函数声明为inline,减少CPU的调用开销,最后在嵌入式系统上将计算速度提升到了0.5秒。
以上为conquer 05年《让你的软件飞起来》中的相关数据,通过软件优化的提升,从最初的120S提升到了0.5S,将近240倍,足以见得一个优秀的软件工程师的重要性,也许IOS和Windows的性能差距那么大,也由此方面原因吧。
目前多媒体视频普遍到了2K/4K的分辨率,以4K视频为例,其运算量是640*480的30.7倍((4096*2304)/(640*480)≈30.7),那么0.5*30.7=15.35秒怎么做到实时视频处理/显示呢(60FPS下单帧16.667ms),差92000倍呢。PC采用GPU加速处理完成图形运算,但如果是终端产品,如果没有昂贵的CPU,也没有其他加速引擎,那简直天方夜谭。那么,此时主角该上场了——硬件加速器,让我们开始他的表演。
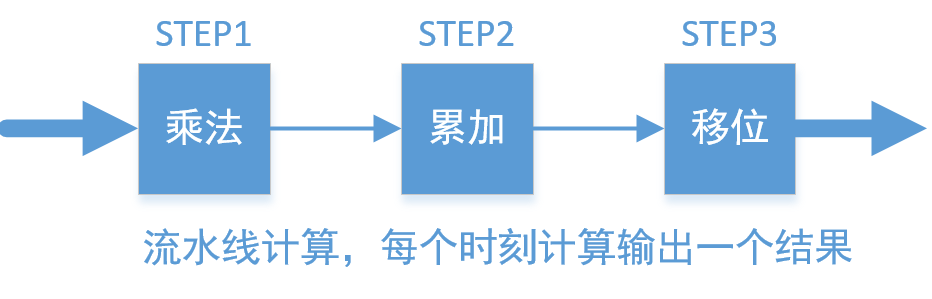
以4096*2304的4K60视频RGB转YUV为例,进行硬件思维的加速计算解说。不管是FPGA还是ASIC,以门级电路并行加速运算,时序逻辑每个时钟翻转完成一次计算。前面《让你的软件飞起来》中(2)已经完成了定点化,然后(3)采用乘法+移位的方式实现,(4)采用查找表再累加的方式实现。单从效率上考虑,两者计算一个像素的灰度均耗用3个CLK(乘法、累加、移位,或给RAM地址、读RAM数据,累加);但从资源上对比,前者占用3个乘法器和2个加法器,乘法器数量不多,但是综合速率受器件的限制,后者则需要3个19bit*256深度的RAM,占用了更多的面积,综合速率上也受到RAM的限制。两者都用了专用单元库,但采用硬件乘法器面积更小,且灵活性更强,工作量也更小(不用专门去生成),因此用硬件加速首选采用优化方式(3),具体实现流水线如下:
STEP1:采用三个乘法器,并行计算当前输入像素的RGB通道乘法,即R*1224,G*2404, B*467;
STEP2:将上述三个结果直接进行累加;同时计算下一个像素的STEP1操作;
STEP3:将累加后的结果向右移动12bit,取低8bit得到最后的结果;同时计算下一个像素的STEP1,STEP2。
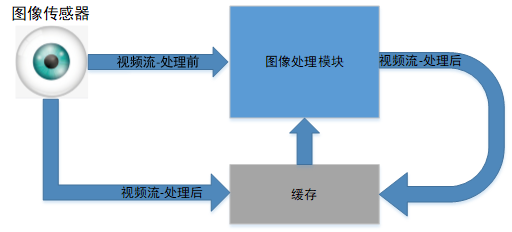
以流水线式循环操作完一副完整的图像,如果是输入到下一级算法处理,则整体的延时仅为3个CLK,因为三个时钟后得到灰度图像的1个像素,立马可以进行下一级运算;如果图像写回缓存,我们再来精算一下:以主频250MHz为例(事实上28nm ASIC跑500MHz甚至1GHz都不是问题,FPGA 45nm的250MHz也没有问题),则需要(4096*2304+2)*4ns=37.75ms>16.667ms。
直接流水线实现,貌似这还不够满足我们实时的需求,毕竟很多运算需要从内存中来,回到内存中去,还得给别的算法预留时间,彩色转灰度这只是算法的第一步而已,复杂的还没来呢。那我们继续想办法突变限制,充分利用硬件加速,挑战不可能。既然采用门级电路,那不存在线程的约束,然而我们已经采用了流水线并行计算灰度值,那进一步想是否可以同时计算n个像素的灰度值呢?答案是肯定的,如下图所示:
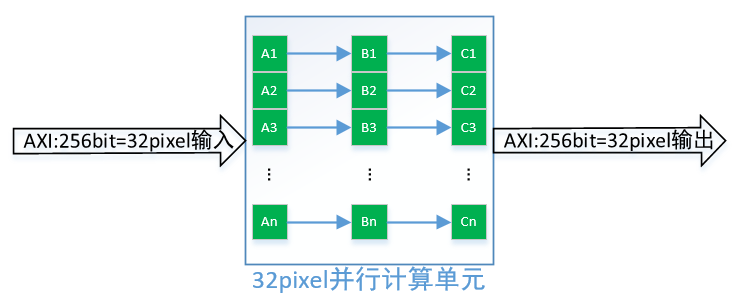
假设DDR控制器位宽是256bit,则一次性可以读取32个pixel的数据,32个像素同时计算需要96个乘法器,64个加法器,这些资源的需求甚至对低端的FPGA都不是问题,对于ASIC来说没有太大的面积影响。因此还是在主频250MHz,DDR控制器带宽256bit条件下,我们处理一副4096*2304彩转灰图像的时间为:37.35/32≈1.17ms<16.667ms,采用并行运算提升32倍效率后,4K图像仅需要1.17ms,完全能够满足实时性,甚至还给后续算法预留了90%以上的时间,可以满足系统的需求。
综上,采用硬件加速实现的几种基本思维,总结如下:
1)浮点转定点,硬件乘法+移位实现加速;
2)资源够的前提下,充分利用并行计算,在单位时间提升计算量;
3)充分利用流水线特性,算法采用Pipeline的方式进行计算,能不回内存就不回内存,能用localbuffer就用localbuffer;
4)尽量少用CPU参与计算,硬件自动完成状态跳转,除非最终结果浮点等复杂的运算;
文章出处:【微信公众号:FPGA自习室】
责任编辑:gt
-
FPGA
+关注
关注
1664文章
22571浏览量
640756 -
控制器
+关注
关注
114文章
17915浏览量
195818 -
分辨率
+关注
关注
2文章
1133浏览量
43425
原文标题:图像处理硬件加速引擎——不断突破限制(下)
文章出处:【微信号:FPGA_Study,微信公众号:FPGA自习室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
国民技术发布一款开箱即用的GMSSL硬件Engine

新思科技2026 HAV硬件加速验证技术开放日深圳站圆满落幕
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片

一文掌握瑞芯微RK系列NPU算子支持全景:覆盖6大平台,新增硬件加速算子,嵌入式AI开发不踩坑

长距传输,安全无忧——探秘NPB 2.0中的硬件MACsec技术

常用硬件加速的方法
软硬件协同技术分享 - 任务划分 + 自定义指令集
RSA加速实现思路
硬件加速模块的时钟设计
睿擎SDK V1.5.0重磅升级:EtherCAT低抖动,AMP虚拟网卡,LVGL硬件加速,多核调试等性能大幅提升|产品动态

如何验证硬件加速是否真正提升了通信协议的安全性?

有哪些方法可以确保硬件加速与通信协议的兼容性?
如何利用硬件加速提升通信协议的安全性?

RISC-V 的平台思维和生态思维
国际首创新突破!中国团队以存算一体排序架构攻克智能硬件加速难题




评论