 一种简单而高效的QoS机制:IEEE802.1Q下的预整形机制
一种简单而高效的QoS机制:IEEE802.1Q下的预整形机制

1.案例背景汽车工业正在迅速向以太网作为车载通信的高速通信网络发展,因此这需要超出传统以太网且必须提供的协议,以便为诸如ADAS系统(高级驾驶员辅助系统)或音频/视频流等要求苛刻的应用提供额外的QoS。
当前为此目的考虑的主要协议是IEEE802.1Q,具有基于信用的整形器机制的AVB/CBS(IEEE802.1Qav)和具有其时间感知整形器的TSN/TAS(IEEE802.1Qbv)。AVB / CBS和TSN / TAS都提供有效的QoS机制,并且可以组合使用,这为设计人员提供了许多可能性。
但是,使用它们需要专用的硬件和软件组件,在TAS的情况下需要时钟同步。先前的研究还表明,这些协议的效率在很大程度上取决于手头的应用和配置参数的值。
在此次案例中,探索在IEEE802.1Q下针对突发流量(例如音频/视频流)使用预整形策略,作为AVB / CBS和TSN / TAS的一种简单有效的替代方法。
预整形意味着在发送突发的连续帧之间(例如,在发送摄像头报文帧时发生的情况下)在发送方进行“精心选择”的插入,然后将流量的所有其他特征保持不变。我们在雷诺汽车案例研究中展示了如何对音频/视频流使用预整形如何在最大程度上减少尽力而为流的通信等待时间,同时满足其余流量的时序约束。
2.现有解决方案的局限性虽然现阶段使用的的QoS协议(优先级机制、CBS、TAS)在某些情况下有效,但它们各自都有缺点和局限性:
仅使用优先级会导致性能下降,即严重的抖动和最大延迟,并且可能导致低优先级流量(以下也称为尽力而为流量)的匮乏。此外,当流量(例如视频流)突发时,交换机中避免丢包所需的内存可能变得很重要;
到现在为止,AVB / CBS确保尽力而为流量的性能要好得多,但是标准的AVB类不够灵活,无法满足所有通信需求。使用AVB自定义类有助于最大程度地发挥AVB的作用,但这并不总是足够的。此外,为自定义类定义参数需要最坏情况的可调度性分析和用于设置CBS IdleSlopes的优化算法;
TSN / TAS,特别是与CBS结合使用时,提供了很多可能性,但是,为了使其有效,必须对所有发送者和交换机共同完成TAS门调度表的配置,这会导致复杂的优化问题。同样,TSN / TAS需要同步协议来建立和维护全局时钟,这会导致一些开销和复杂性,并降低系统的整体鲁棒性。
3.预整形机制预整形机制将标准静态优先级调度与流量整形相结合,流量的所有其他特征保持不变。利用插入的空闲时间更快地传输穿过预整形流路径的较低优先级或相同优先级的帧。 预整形并不是针对提高优先级较高的流量的通信延迟,而是可以与帧抢占结合使用,配置为属于流集合的预整形流,而不是被高优先级抢占。在汽车领域,可以在中间件级别或通信驱动程序级别的软件中实现预整形。预整形机制的系统模型:
T是分段报文的周期
N是组成报文的帧数
D是报文的相对截止时间,即报文释放后的时间,所有接收站必须已接收到报文最后一帧
I是插入报文的每个帧之间的空闲时间
E是报文帧的最长传输时长(E = L / C,当C为链路传输速率,L为帧长:包括帧间间隙和前导码)
形成报文的帧数N取决于每个帧中包含的数据有效载荷。设计者还可以在协议允许的间隔内(即46到1500字节)确定此参数。较小的数据有效载荷会导致较高的开销,同时对其余流量的干扰也较小。最简单,最实用的方法是本研究案例中尝试的方法,它是不更改帧的大小,而仅使用报文的连续帧之间的空闲时间来实现流量整形。
假设摄像头数据帧以周期T进行发送。每条数据流均以N帧的形式发送,每N个时间单位将其释放以进行发送。报文的最后一帧将在时间(N-1)∙I释放,并且必须在截止时间之前接收。在Image数据流发布后,最后一帧将排队在(I + E)·(N-1)个时间单位。因此,如果最后一帧的通信等待时间受Rmax限制,则必须在0和(D-Rmax)/(N-1)– E之间选择空闲时间I。
后一个上限将连续传输扩展到最长时间间隔确保在截止时间之前完成,从而为位于优先级较低的流量类别中的帧提供最大可能的带宽。本研究中使用的工具RTaW-Pegase中可用的PRESH算法的基础策略。
4.案例:雷诺原型以太网网络架构4.1 拓扑结构和流量案例研究是雷诺汽车的一个原型以太网网络,包括5个交换机和14个节点:4个摄像头(CAM),4个显示器(Display),3个控制单元(ECU)和3个域主站(DM),如图5所示。域主机3(DM3) 和交换机3之间链路上的传输速率为1Gbit/s,其他所有链路上的数据传输速率均为100Mbit/s。
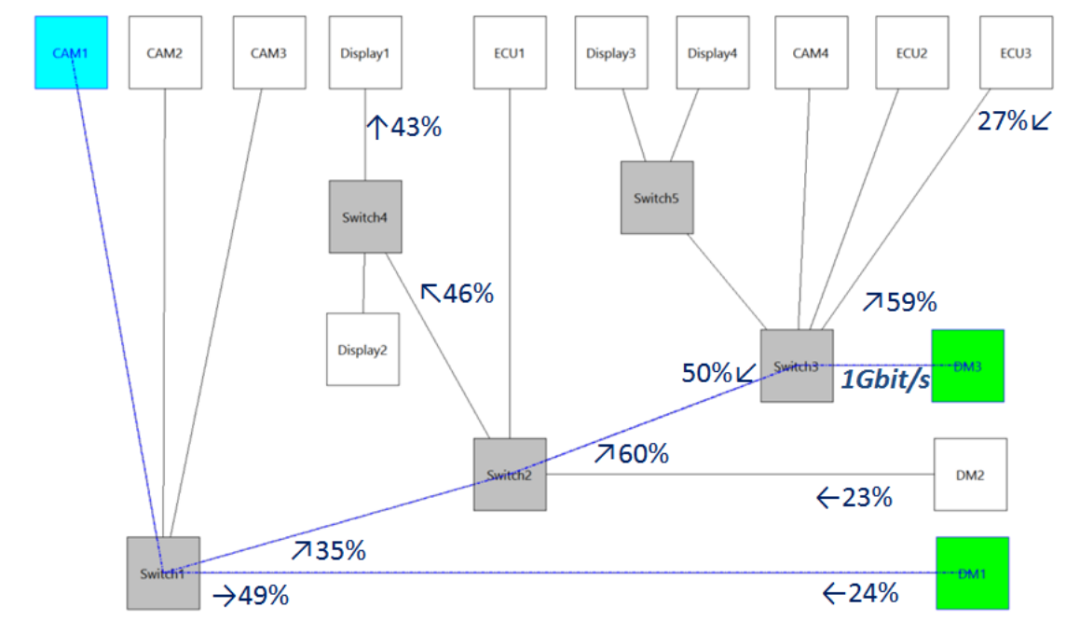
案例研究使用的原型网络拓扑结构(RTaW-Pegase软件截图)
上图显示的多播流从摄像机1到域主机1和3,该图显示了10个负载最大的链路(最大负载为60%)和单个速率为1Gbit / s链路。流量由四个类别组成,总共41个流,其特征下表中进行了概述:音频流8个数据流
128和256字节帧
截止时间:10ms以下
软实时要求
视频流2个ADAS流+ 6个vision流
每16ms(60FPS)或每33ms
(30FPS)最多30 * 1446byte帧
截止时间:10ms(ADAS),30ms(Vision)
硬实时+软实时要求
Command & Control11个流,256到1024字节帧
截止时间:10ms以下
硬实时要求
尽力而为流:File, data transfer, diagnostics14个流,包括TFTP流量模式
0.2ms的周期
吞吐量保证(每个流高达20Mbits)
软实时要求
4.2验证技术和协议配置这项研究是使用时序精确的仿真和最先进的网络演算实现方法进行的最坏情况遍历时间(WCTT)分析进行的。两种技术是互补的,虽然WCTT是最安全的方法,但是其本质上是考虑的最坏情况。此外,它不提供诸如延迟分布之类的统计信息,也不提供对类似FTP的流可以实现的吞吐量的准确评估。
使用的设计和时序分析工具是RTaW-Pegase v2.4.5,模拟样本是通过长时间的模拟(2天不间断运行,在500ms的最低频率帧进行约35万次传输)收集的,每个站点的时钟漂移设为±200ppm ,在本研究的其余部分中,我们将比较以下QoS协议的性能:
静态优先级以太网,不进行预整形(以下称为IEEE802.1Q),其优先级分配按优先级降序排列, 优先级从高到低为:命令和控制(最高优先级),然后是音视频,最后是尽力而为流(最低优先级);
具有预整形的静态优先级以太网(称为具有预整形的IEEE802.1Q),用于视频流。使用预整形机制一节中描述的策略完成了预整形配置,从而使下图中所示的配置符合所有性能约束。对于没有预先成形的解决方案,优先级分配保持不变;
具有自定义类的AVB / CBS,不使用标准的125 / 250us CMI和标准的空闲斜率。在交换机和发送节点中都使用CBS,路径上每个输出端口上的CBS空闲斜率已使用RTaW-Pegase中实现的严格空闲斜率算法进行了设置。该算法计算出可能的最小空闲斜率,从而满足AVB流量的时序约束,从而将对较低优先级流产生的干扰降至最低。就优先级而言,音频流的优先级最高(AVB为最高优先级),其次为视频流(AVB为第二优先级),然后是命令与控制,最后是尽力而为流。
4.3 尽力而为流的平均延迟下图显示了所研究的三种协议下所有尽力而为流的平均通信延迟。与标准IEEE802.1Q(黑色曲线)相比,预整形(红色曲线)将尽力而为流的平均延迟平均提高了54%,最高可提高86%。如果不进行预整形,IEEE802.1Q将是不可行,因为无法满足尽力而为流的吞吐量限制。
预整形机制和AVB自定义类在这里都是可行的解决方案,它们在尽力而为流的平均延迟方面的表现几乎相同。但是,除了不需要专用硬件外,预整形还具有优于AVB的性能,即命令和控制流以最高优先级发送,从而减少了等待时间。对于系统的鲁棒性也是有益的。
4.4尽力而为流的最坏情况延迟下图显示了所有尽力而为流的最坏情况下的通信延迟。IEEE802.1Q下的预整形可将尽力而为流的最坏情况延迟平均提高66%,最高可提高90%。再次,可观察到预整形和AVB自定义类之间的相似性能。该实验表明,通过预整形,还可以显着降低延迟的变化,从而降低接收时的抖动。
4.5对Command & Control流的影响下图显示了以下两种情况下C&C流的最坏情况网络遍历时间(WCTT)和平均网络遍历时间(AVRG):
具有和不具有预整形的IEEE802.1Q;
AVB / CBS,用于音频/视频流,配置有严格的空闲斜率机制。
流量类别的相对优先级如协议配置小节中所定义。我们首先观察到的是,预整形对C&C流量的WCTT没有影响。这可以很好的解释,因为在WCTT计算中较低优先级帧的干扰仅通过阻塞因子,即最大的较低优先级帧的大小(其值在预成形时保持不变)。
当将AVB tight IdleSlope用于音频/视频流时,C&C的WCTT明显大于IEEE802.1Q(平均增加 42%,最高129%)。这可以通过AVB流量类别带来的干扰来解释,该类别的优先级高于C&C流量。在平均通信延迟方面,这对于C&C帧通常不是最重要的指标,这三种解决方案的效果都非常好,几乎是等效的。
4.6交换机中的内存使用情况到目前为止,已经假定不会由于没有足够的存储器来存储等待传输的数据包而发生数据包丢失,无论该数据包是在终端系统中还是在交换机中。在实践中,确定内存量的大小以使数据包不丢失对于交换机尤为重要。
通过网络演算分析获得的交换机输出端口中内存使用率的上限。带有预整形的AVB / CBS和IEEE802.1Q都以有效的方式对流量进行整形,从而导致最低的内存使用量。在柱形图的另一端,没有预整形的IEEE802.1Q会生成帧突发,这些突发会累积在交换机中。
与不进行预整形的IEEE802.1Q相比,在传输中具有预整形的IEEE802.1Q平均将内存使用量提高了两倍。AVB Tight Idle-Slope可能会在出口端口之间的传输之间插入延迟,因此比具有预整形的IEEE802.1Q所需的内存更多(平均增加28%)。
5.案例总结
在实际案例研究中进行的实验表明,将预整形应用于生成帧突发的流是减少较低优先级流的通信延迟的有效机制。另外,预整形不需要专用硬件,并且可以以最小的开销在软件中实现。在这方面,它与CAN中的偏移机制具有相似之处,该机制已在汽车工业中成功使用了多年。 虽然简单有效,但具有静态优先级调度的预整形策略将具有一些局限性:
该节点会发送超出其规范的帧。例如,由于硬件或软件故障而将继续发送帧并淹没网络的节点。可以使用两种解决方案:按类整形(如在AVB中使用CBS)或按流整形(如在AFDX或PSFP(IEEE802.1Qci)中);
添加新功能或新ECU(这会导致向系统中添加框架)可能会要求重新配置所有流的预整形参数,因为最大通信延迟会发生变化。此限制不是特定于预整形的,它会影响大多数QoS协议,除了具有最高优先级的AVB类的标准AVB之外;
当通过反复试验手动完成时,为要受预整形机制影响的流设置参数是一项耗时的任务,并且可能不会导致最佳结果。设置参数的过程需要专用的工具支持;
从OEM的角度来看,预整形对ECU供应商提出了额外的要求,这也就相应的增加l成本。其次,就像CAN中的传输偏移一样,预整形只能在减少的节点子集上实现,例如在我们的案例中,研究14个节点中只有5个在传输中使用了预整形。
编辑:jq
-
存储器
+关注
关注
39文章
7770浏览量
172458 -
CAN
+关注
关注
59文章
3109浏览量
473868 -
ecu
+关注
关注
14文章
1002浏览量
57582 -
AVB
+关注
关注
0文章
16浏览量
5719
原文标题:【虹科】RTaW-Pegase应用案例 | 一种简单而高效的QoS机制:IEEE802.1Q下的预整形机制
文章出处:【微信号:Hongketeam,微信公众号:广州虹科电子科技有限公司】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
深度解析AS32S601芯片CAN Bus Off机制

一种基于电压监控器与内置自检机制的汽车摄像头功能安全设计方法

一文看懂PCIe中断机制

【量产烧录】Verify通过还报错?拆一次CRC校验的实现机制就明白问题在哪
操作系统运行机制
芯片引脚成型与整形:电子制造中不可或缺的两种精密工艺
如何利用Trace机制实现LLCP预览功能
教程来啦!LuatOS中的消息通信机制详解及其应用场景

边聊安全 | 安全芯片的守护神:BIST机制的深度解析

浅谈Sn-Bi-Ag低温锡膏的晶界强化机制
虹科干货 | 信用整形机制Qav:如何平衡流量整形和缓存大小?

电容瞬态放电原理:大电流的产生机制




评论