 一个使用YoloV5的深度指南,使用WBF进行性能提升
一个使用YoloV5的深度指南,使用WBF进行性能提升

导读
一个使用YoloV5的深度指南,使用WBF进行性能提升。
网上有大量的YoloV5教程,本文的目的不是复制内容,而是对其进行扩展。我最近在做一个目标检测竞赛,虽然我发现了大量创建基线的教程,但我没有找到任何关于如何扩展它的建议。此外,我想强调一下YoloV5配置中影响性能的最重要部分,因为毕竟数据科学主要是关于实验和超参数调整。
在这之前,我想说使用目标检测模型和使用图像分类模型在框架和库的工作方式上是不同的。这是我注意到的,我花了很长时间才弄明白。大多数流行的目标检测模型(如YoloV5、EfficientDet)使用命令行接口来训练和评估,而不是使用编码方法。这意味着,你所需要做的就是获取特定格式的数据(COCO或VOC),并将命令指向它。这通常与使用代码训练和评估模型的图像分类模型不同。
数据预处理
YoloV5期望你有两个目录,一个用于训练,一个用于验证。在这两个目录中,你需要另外两个目录,“Images”和“Labels”。Images包含实际的图像,每个图像的标签都应该有一个带有该图像标注的.txt文件,文本文件应该有与其对应的图像相同的名称。
标注格式如下:
<'class_id'><'x_center'><'y_center'>
要在代码中做到这一点,你可能需要一个类似的函数,在原始数据帧中有图像项,它们的类id和它们的边界框:
defcreate_file(df,split_df,train_file,train_folder,fold): os.makedirs('labels/train/',exist_ok=True) os.makedirs('images/train/',exist_ok=True) os.makedirs('labels/val/',exist_ok=True) os.makedirs('images/val/',exist_ok=True) list_image_train=split_df[split_df[f'fold_{fold}']==0]['image_id'] train_df=df[df['image_id'].isin(list_image_train)].reset_index(drop=True) val_df=df[~df['image_id'].isin(list_image_train)].reset_index(drop=True) fortrain_imgintqdm(train_df.image_id.unique()): withopen('labels/train/{train_img}.txt','w+')asf: row=train_df[train_df['image_id']==train_img] [['class_id','x_center','y_center','width','height']].values row[:,1:]/=SIZE#Imagesize,512here row=row.astype('str') forboxinrange(len(row)): text=''.join(row[box]) f.write(text) f.write(' ') shutil.copy(f'{train_img}.png', f'images/train/{train_img}.png') forval_imgintqdm(val_df.image_id.unique()): withopen(f'{labels/val/{val_img}.txt','w+')asf: row=val_df[val_df['image_id']==val_img] [['class_id','x_center','y_center','width','height']].values row[:,1:]/=SIZE row=row.astype('str') forboxinrange(len(row)): text=''.join(row[box]) f.write(text) f.write(' ') shutil.copy(f'{val_img}.png', f'images/val/{val_img}.png')
注意:不要忘记保存在标签文本文件中的边界框的坐标**必须被归一化(从0到1)。**这非常重要。另外,如果图像有多个标注,在文本文件中,每个标注(预测+边框)将在单独的行上。
在此之后,你需要一个配置文件,其中包含标签的名称、类的数量以及训练和验证的路径。
importyaml classes=[‘Aorticenlargement’, ‘Atelectasis’, ‘Calcification’, ‘Cardiomegaly’, ‘Consolidation’, ‘ILD’, ‘Infiltration’, ‘LungOpacity’, ‘Nodule/Mass’, ‘Otherlesion’, ‘Pleuraleffusion’, ‘Pleuralthickening’, ‘Pneumothorax’, ‘Pulmonaryfibrosis’] data=dict( train=‘../vinbigdata/images/train’,#trainingimagespath val=‘../vinbigdata/images/val’,#validationimagespath nc=14,#numberofclasses names=classes ) withopen(‘./yolov5/vinbigdata.yaml’,‘w’)asoutfile: yaml.dump(data,outfile,default_flow_style=False)
现在,你需要做的就是运行这个命令:
pythontrain.py—img640—batch16—epochs30—data./vinbigdata.yaml—cfgmodels/yolov5x.yaml—weightsyolov5x.pt
从经验中需要注意的事情:
好了,现在我们已经浏览了基本知识,让我们来看看重要的东西:
别忘了归一化坐标。
如果你的初始性能比预期的差得多,那么最可能的原因(我在许多其他参赛者身上看到过这种情况)是你在预处理方面做错了什么。这看起来很琐碎,但有很多细节你必须注意,特别是如果这是你的第一次。
YoloV5有多种型号(yolov5s、yolov5m、yolov5l、yolov5x),不要只选择最大的一个,因为它可能会过拟合。从一个基线开始,比如中等大小的,然后试着改善它。
虽然我是在512尺寸的图像上训练的,但我发现用640来infer可以提高性能。
不要忘记加载预训练的权重(-weights标志)。迁移学习将大大提高你的性能,并将为你节省大量的训练时间(在我的例子中,大约50个epoch,每个epoch大约需要20分钟!)
Yolov5x需要大量的内存,当训练尺寸为512,批大小为4时,它需要大约14GB的GPU内存(大多数GPU大约8GB内存)。
YoloV5已经使用了数据增强,你可以选择喜欢或不喜欢的增强,你所需要做的就是使用yolov5/data/hyp.scratch.yml文件去调整。
默认的yolov5训练脚本使用weights and biases,说实话,这非常令人印象深刻,它在模型训练时保存所有度量。但是,如果你想关闭它,只需在训练脚本标记中添加WANDB_MODE= " dryrun "即可。
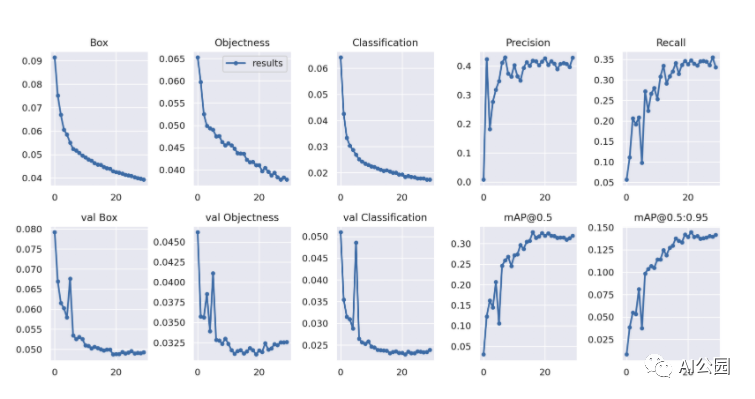
我希望早就发现的一件事是,YoloV5将大量有用的指标保存到目录YoloV5 /runs/train/exp/中。训练之后,你可以找到“confusion_matrix.png”和“results.png”,其中的result .png应该是这样的:
使用WBF预处理
好了,现在你已经调整了超参数,升级了你的模型,测试了多种图像大小和交叉验证。现在是介绍一些提高性能的技巧的时候了。
加权框融合是一种在训练前(清理数据集)或训练后(使预测更准确)动态融合框的方法。如果你想知道更多,你可以在这里查看我的文章:
WBF:优化目标检测,融合过滤预测框 (qq.com)
要使用它对数据集进行预处理,这将大多数参赛者的性能提高了大约10-20%,你可以这样使用:
fromensemble_boxesimport* forimage_idintqdm(df['image_id'],leave=False): image_df=df[df['image_id']==image_id].reset_index(drop=True) h,w=image_df.loc[0,['height','width']].values boxes=image_df[['x_min','y_min','x_max','y_max']].values.tolist() #Normalisealltheboundingboxes(bydividingthembysize-1 boxes=[[j/(size-1)forjini]foriinboxes] scores=[1.0]*len(boxes)#setallofthescoresto1sinceweonlyhave1modelhere labels=[float(i)foriinimage_df['class_id'].values] boxes,scores,labels=weighted_boxes_fusion([boxes],[scores],[labels],weights=None,iou_thr=iou_thr, skip_box_thr=skip_box_thr) list_image.extend([image_id]*len(boxes)) list_h.extend([h]*len(boxes)) list_w.extend([w]*len(boxes)) list_boxes.extend(boxes) list_cls.extend(labels.tolist()) #bringtheboundingboxesbacktotheiroriginalsize(bymultiplyingbysize-1)list_boxes=[[int(j*(size-1))forjini]foriinlist_boxes] new_df['image_id']=list_image new_df['class_id']=list_cls new_df['h']=list_h new_df['w']=list_w #Unpackthecoordinatesfromtheboundingboxes new_df['x_min'],new_df['y_min'], new_df['x_max'],new_df['y_max']=np.transpose(list_boxes)
这意味着要在将边框坐标保存到标注文件之前完成。你还可以尝试在用YoloV5以同样的方式预测边界框之后使用它。
首先,在训练YoloV5之后,运行:
!pythondetect.py—weights/runs/train/exp/weights —img640 —conf0.005 —iou0.45 —source$test_dir —save-txt—save-conf—exist-ok
然后提取框、分数和标签:
runs/detect/exp/labels
然后传递到:
boxes,scores,labels=weighted_boxes_fusion([boxes],[scores],[labels],weights=None,iou_thr=iou_thr, skip_box_thr=skip_box_thr)
最后的思考
我希望你已经学到了一些关于扩展你的基线YoloV5的知识,我认为最重要的事情总是要考虑的是迁移学习,图像增强,模型复杂性,预处理和后处理技术。这些是你可以轻松控制和使用YoloV5来提高性能的大部分方面。
责任编辑:lq
-
图像分类
+关注
关注
0文章
97浏览量
12531 -
目标检测
+关注
关注
0文章
234浏览量
16544 -
迁移学习
+关注
关注
0文章
74浏览量
5856
原文标题:高级YoloV5指南,使用WBF来提升目标检测性能
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
米尔RK3576+Hailo-8突破6 TOPS极限,让高帧率摄像头真正“实时”
【NPU实战】在迅为RK3588上玩转YOLOv8:目标检测与语义分割一站式部署指南

基于迅为RK3588开发板实现高性能机器狗主控解决方案- AI能力实战:YOLOv5目标检测例程

迅为如何在RK3576上部署YOLOv5;基于RK3576构建智能门禁系统

一个提升蜂鸟E203性能的方法:乘除法器优化
使用ROCm™优化并部署YOLOv8模型
技术分享 | RK3588基于Yolov5的目标识别演示

基于瑞芯微RK3576的 yolov5训练部署教程

树莓派5超频指南:安全高效地提升性能!

在k230上使用yolov5检测图像卡死,怎么解决?
yolov5训练部署全链路教程




评论