 中山大学提出新型行人重识别方法和史上最大最新评测基准
中山大学提出新型行人重识别方法和史上最大最新评测基准

行人重识别,又称行人再识别,是利用 CV 技术判断图像或视频序列中是否存在特定行人的技术。常规的行人重识别方法往往需要高昂的人工标注成本,计算复杂度也很大。在本文中,中山大学研究者提出的弱监督行人重识别方法恰恰克服了这两方面的障碍,并发布了一个大型行人重识别数据集。
近期,中山大学发布了一种基于可微图学习的弱监督行人重识别(person re-ID)方法和一个大型数据集。该方法结合可微图学习和弱监督学习方法,为行人重识别深度神经网络加入自动生成训练标签的模块并与其一体训练。相比普通的行人重识别方法,该方法不需要高昂的人工标注成本,并且几乎不增加计算复杂度也能达到领先的模型性能。 正是因为标注的简单,一个大型行人重识别数据集也诞生了,即 SYSU-30k。SYSU-30k 数据集包含 30,000 个行人身份类别,约是 CUHK03 和 Market-1501 的 20 倍。如果一个行人身份类别相当于一个物体类别的话,则 SYSU-30k 相当于 ImageNet 的 30 倍。该数据集总共包含 29,606,918 张图像。 就原理而言,该方法首先将行人图像按拍摄时间段分组成袋并分配袋类别标签,然后结合图模型和深度神经网络捕获一个袋中所有图像之间的依赖关系,从而为每张图像生成可靠的伪行人类别标签,作为行人重识别模型训练的监督信息;接着进一步将图模型可微化,实现图模型和行人重识别模型的一体训练;最后将图模型损失和重识别损失的线性组合作为总损失函数,利用反向传播算法更新网络所有层的参数。相关论文发表在国际期刊 TNNLS 上。
背景 目前,行人重识别问题主要有三种实现方法:(1)提取判别特征;(2)学习一个稳定的度量或子空间进行匹配;(3)联合上述两种方法。然而,大部分实现方法需要强监督训练标签,即需要人工标注数据集中的每张图像。 此外也有不需要人工标注的基于无监督学习的行人重识别方法,这类方法使用局部显著性匹配或聚类模型,但很难建模跨摄像机视图的显著差异,因此很难达到高精度。 相比之下,本文提出的弱监督行人重识别方法是一种优秀的训练方法,不需要高昂的人工标注成本也能达到较高的精度。弱监督行人重识别的问题定义如下图 1 所示,其中图 1(a)是常规全「监督」行人重识别问题,图 1(b)是弱监督行人重识别问题,图 1(c)是测试阶段,两种方式的测试阶段一致。
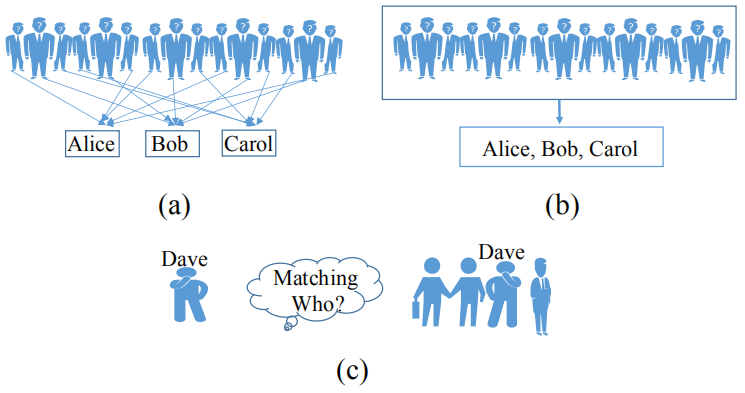
图 1:弱监督行人重识别的问题定义 具体而言,该方法主要包括以下四个过程:
将行人图像按拍摄时间段分组成袋并分配袋类别标签;
结合图模型和深度神经网络捕获一个袋中所有图像之间的依赖关系来为每张图像生成可靠的伪行人类别标签,作为行人重识别模型训练的监督信息;
进一步将图模型可微化,实现图模型和行人重识别模型的一体训练;
将图模型损失和重识别损失的线性组合作为总损失函数,利用反向传播算法更新网络所有层的参数。
本文的主要贡献有以下几点: 第一,研究者定义了一个弱监督行人重识别问题,利用袋类别标签代替常规行人重识别中的图像类别标签。这个问题值得进一步探讨,因为弱监督行人重识别问题可以大大减少标注代价,并为收集大尺度行人重识别数据集提供了可能。 第二,由于存在的基准数据集忽略了弱监督行人重识别问题,研究者收集了一个新的大规模行人重识别数据集 SYSU-30k,为未来研究行人重识别问题提供了便利。SYSU-30k 数据集包含 30,000 个行人身份类别,大约是 CUHK03 数据集(1,300 个行人身份)和 Market-1501 数据集(1,500)的 20 倍,是 ImageNet(1,000 个类别)的 30 倍。SYSU-30k 包含 29,606,918 张图像。SYSU-30k 数据集不仅仅是弱监督行人重识别的一个评测平台,更有一个和现实场景相似的挑战性测试集。 第三,研究者引入了一个可微图模型来处理弱监督行人重识别中不精准的标注问题。
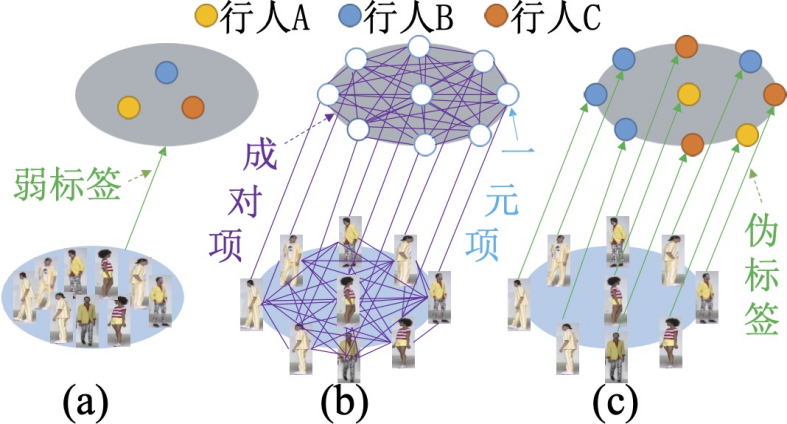
图 2:方法示意图 SYSU-30k 数据集 目前没有公开发布的「弱监督」行人重识别数据集。为了填补这个空白,研究者收集了一个新的大规模行人重识别数据 SYSU-30k,为未来行人重识别研究提供了便利。他们从网上下载了许多电视节目视频。考虑电视节目视频的原因有两个:第一,电视节目中的行人通常是跨摄像机视角,它们是由多个移动的摄像机捕捉得到并经过后处理。因此,电视节目的行人识别是一个真实场景的行人重识别问题;第二,电视节目中的行人非常适合标注。在 SYSU-30k 数据集中,每一个视频大约包含 30.5 个行人。 研究者最终共使用的原视频共 1000 个。标注人员利用弱标注的方式对视频进行标注。具体地,数据集被切成 84,930 个袋,然后标注人员记录每个袋包含的行人身份。他们采用 YOLO-v2 进行行人检测。三位标注人员查看检测得到的行人图像,并花费 20 天进行标注。最后,29,606,918(≈30M)个行人检测框共 30,508(≈30k)个行人身份被标注。研究者选择 2,198 个行人身份作为测试集,剩下的行人身份作为训练集。训练集和测试集的行人身份没有交叠。 SYSU-30k 数据集的一些样例如下图 3 所示。可以看到,SYSU-30k 数据集包含剧烈的光照变化(第 2,7,9 行)、遮挡(第 6,8 行)、低像素(第 2,7,9 行)、俯视拍摄的摄像机(第 2,5,6,8,9 行)和真实场景下复杂的背景(第 2-10 行)。
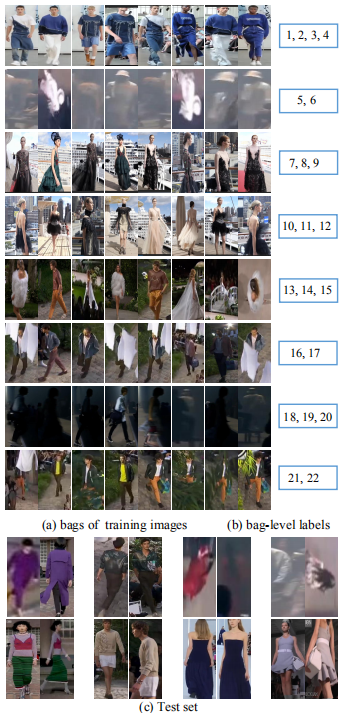
图 3:SYSU-30k 数据集样例。 SYSU-30k 数据集的统计特性 SYSU-30k 包含 29,606,918 张行人图像,共计 30,508 个行人身份类别,被切分成 84,930 个袋(仅在训练集中按袋切分)。图 4(a)总结了袋的数量与每个袋含有的图像数量的直方图统计。每个袋平均有 2,885 张图像。该直方图展示了现实场景中袋的行人图像数量分布,没有经过人工手动细分和清理。这里,数据集的标签是以袋级别进行标注的。
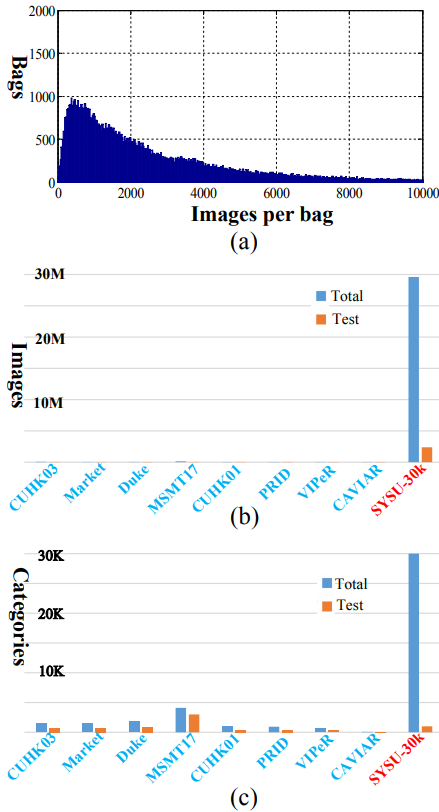
图 4:数据集统计特性。 对比现有的行人重识别基准数据集 研究者对 SYSU-30k 和现有行人重识别数据集进行对比,包括 CUHK03、Market-1501、Duke、MSMT17、CUHK01、PRID、VIPeR 和 CAVIAR。图 4(b)和 4(c)分别展示了图像的数量和行人身份类别的数量。可以看出,SYSU-30k 数据集比已有的数据集都大很多。 为了评估弱监督行人重识别的性能,研究者从 SYSU-30k 数据集中随机选择 2,198 个行人身份作为测试集。需要注意,这些行人身份类别没有在训练集中出现。研究者对该测试集进行精细的图像级别的行人身份标注,并且也对测试集图像的数量和行人身份类别数量进行了对比,如图 4(b)和 4(c)。可以看出,SYSU-30k 的测试集比现有数据集更大更有挑战性。多亏了袋级别的标注方式,SYSU-30k 测试集能够反映真实场景的设置。SYSU-30k 不仅仅是弱监督行人重识别的大型基准数据集,也是一个评估真实场景中全监督行人重识别性能的标准平台。 SYSU-30k 数据集和其他数据集的进一步对比如下表 1(a)所示,包括行人身份类别数量、场景、标注方式以及摄像机数量和图像数量。 研究者总结出了 SYSU-30k 的新特色,有如下几个方面:第一,SYSU-30k 是首个弱监督行人重识别数据集;第二,SYSU-30k 的行人身份数量和图像数量都是现有行人重识别数据集中最大的;第三,SYSU-30k 数据集更具挑战性,包括摄像机数量、真实的室内环境和室外场景和不精准的袋级别标注;第四,SYSU-30k 的测试集不仅仅适合于弱监督行人重识别问题,也是一个评估真实场景中全监督行人重识别的标准平台。

表 1(a):对比存在的行人重识别数据集。 除了和行人重识别社区的数据集对比之外,研究者还对比了 SYSU-30k 和通用图像分类中著名的 ImageNet-1k 基准数据集。如下表 1(b)所示,SYSU-30k 有以下几个吸引人的优点:第一,SYSU-30k 比 ImageNet-1k 有更多的类别,即 30,000 对比 1,000;第二,由于有效的弱标注方法,SYSU-30k 标注需要的代价更低。

表 1(b):对比 ImageNet-1k 数据集。 评估方式 SYSU-30k 的评估方式和先前常规行人重识别数据集的评估方式类似。研究者固定训练集和测试集的划分。在测试集中,他们从 1,000 个不同的行人身份类别中分别选择一张行人图像,共得到 1,000 张行人图像作为查询集。 此外,为了符合实际场景中行人重识别的可拓展性,研究者提供了一个包含大量干扰行人图像的候选集。具体地,对于每张查询图,在候选集中仅含有一张图像和该查询图身份类别一样,其他 478,730 张行人图像是不匹配的。因此,这个评估方式就类比于大海捞针,和真实场景中警察从大量监控视频中搜索疑犯一样具有巨大的挑战性。研究者采用 rank-1 准确率作为评估指标。 方法从有监督行人重识别到弱监督行人重识别 用 b 表示包含 p 张图像的一个袋,即 b=x_1,x_2,…x_j…x_p,y=y_1,y_2,…y_j…y_p 为行人身份类别标签,用 l表示袋类别标签。有监督行人重识别需要用行人身份类别标签 y 监督模型的分类预测;弱监督行人重识别只有袋类别标签 l 可用,需要先为每张图像估计一个伪行人类别标签,用一个概率向量Y表示。假设 包含 n个行人类别,整个训练集共有 m个行人类别,用袋类别标签限制Y,则每张图像的行人类别标签的概率向量为:
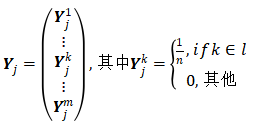
(1)
基于可微图学习的弱监督行人重识别
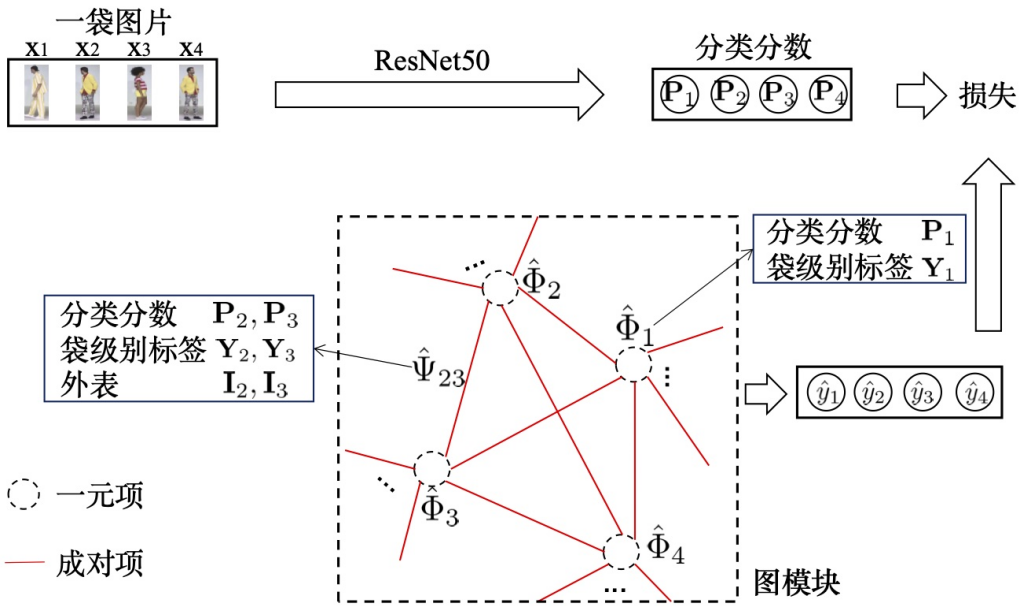
图 5:可微图学习模型。
1. 图模型行人重识别
如上图 5 所示,定义一个有向图,每个节点代表一个袋中的一张图像 x_i,每条边代表图像之间的关系,在图上为节点 x分配行人类别标签 y 的能量函数为:
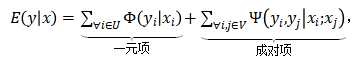
(2)
其中 U 和 V 分别表示节点和边,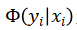 是计算为图像 x_i 分配标签 y_i 的代价的一元项,
是计算为图像 x_i 分配标签 y_i 的代价的一元项,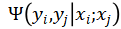 是计算为图像对 (x_i , x_j) 分配标签的惩罚的成对项。公式(2) 消除了弱监督学习生成的错误的伪标签。
是计算为图像对 (x_i , x_j) 分配标签的惩罚的成对项。公式(2) 消除了弱监督学习生成的错误的伪标签。
2. 一元项
公式 (2) 中的一元项定义为:
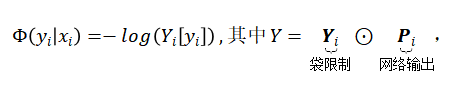
(3)
其中P_i 是神经网络为图像 x_i 计算的行人类别标签的概率,Y_i 是公式 (1) 表示的袋限制,
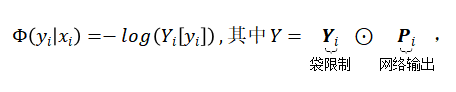
表示逐元素乘积,
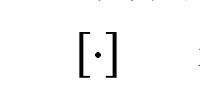
表示向量索引。
3. 成对项
由于不同图像的一元项输出相互独立,一元项不稳定,需要用成对项平滑:
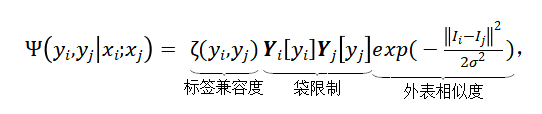
(4)
其中用一个基于 RGB 颜色的高斯核计算外表相似度,超参数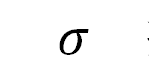 控制高斯核的尺寸,限制外表相似的图像有相同的标签;标签兼容度
控制高斯核的尺寸,限制外表相似的图像有相同的标签;标签兼容度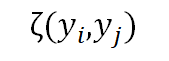 用玻茨模型表示:
用玻茨模型表示:
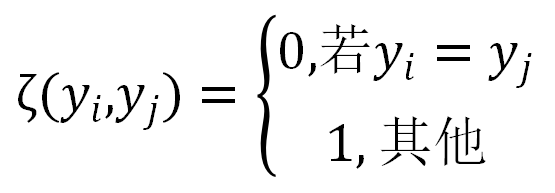
(5)
4. 袋限制
实际上,袋类别标签含有额外信息改善伪标签的生成:将估计的伪标签纠正为袋中预测分数最高的行人分类;促使部分图像被分配到没有被预测的行人类别。
5. 伪行人类别标签的推理
通过最小化公式 (2) 可以得到每张图像的伪行人类别标签:
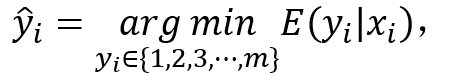
(6)
其中 {1,2,3…,m} 表示训练集中所有的行人身份类别。 6. 图学习可微化 上述弱监督行人重识方法不是一体训练的,因为首先需要用一个外部图模型得到伪行人类别标签,用于监督行人重识别深度神经网络的训练。最小化公式 (2) 得到伪标签的计算是不可微的,使得该图模型与深度神经网络不兼容,因此需要松弛公式 (2) 为:
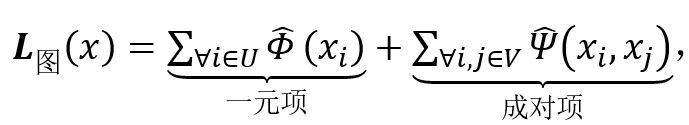
(7)
将离散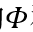 的和
的和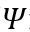 连续化:
连续化:
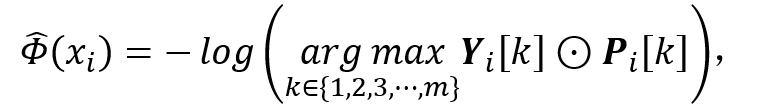
(8)
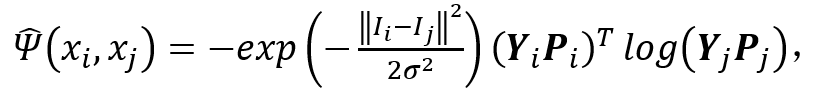
(9)
公式 (8) 和公式 (3) 的区别是,在不可微图模型中,需要给能量函数输入所有可能的 y,将能量最低的 y 作为最优解;在可微图模型中,直接将图像 x 输入深度神经网络得到 y 的预测。公式 (9) 和公式 (4) 的区别是,用交叉熵项
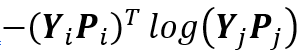
近似公式 (4) 中不可微的项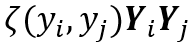 。
。
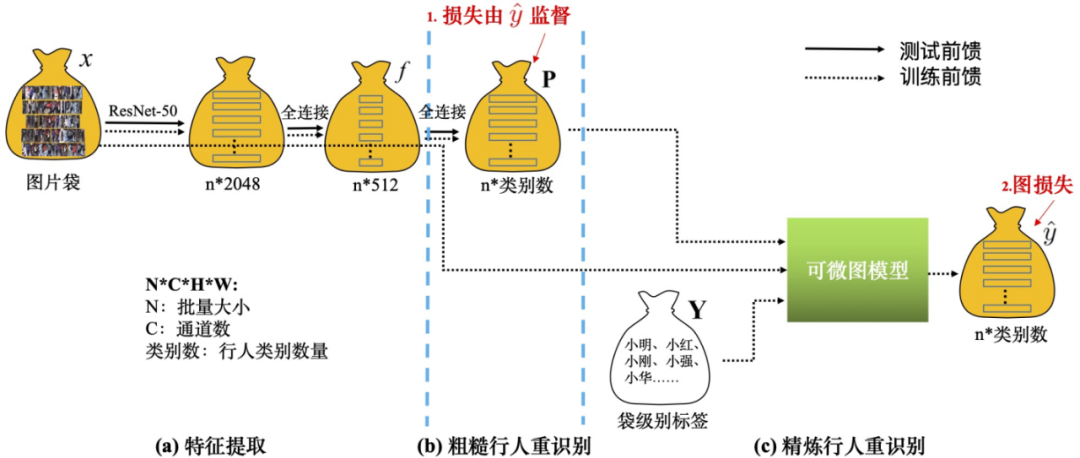
图 6:整体框架图 整体神经网络结构 上图 6 为训练和推理的网络结构,虚线表示训练数据流,实线表示推理数据流,其中图模型只参与训练阶段。整体结构包含三个主要模块: 1.特征提取模块 如图 6(a),运用 ResNet-50 作为骨干网络,去掉原始 ResNet-50 的最后一层,换成一个输出为 512 维的全连接层(FC)、一个批规范化(BN)、一个带泄露线性整流函数 (Leaky ReLU) 和一个 dropout 层。 2. 粗糙行人重识别模块 如图 6(b),在特征提取模块的顶部再加一个输出维度与行人类别数量相同的全连接层,再使用归一化指数交叉熵作为损失函数。行人类别预测分数作为粗糙行人重识别估计,表示袋中图像的行人类别的概率。 3. 精炼行人重识别模块 如图 6(c),按照公式 (8) 和(9)将粗糙行人重识别分数、外表和袋限制输入图模型,图模型生成的伪标签就能像人工标注的真实标签一样被用来更新网络参数。 优化 得到伪行人类别标签就能计算整体损失值对于深度神经网络参数的梯度,利用反向传播算法,将梯度回传给网络的所有层,实现该弱监督模型的所有参数的一体训练。 1. 损失函数 本方法的优化目标包含图模型损失L_图和分类 / 重识别损失L_分类,L_分类是伪标签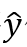 作为监督的归一化指数交叉熵损失函数:
作为监督的归一化指数交叉熵损失函数:
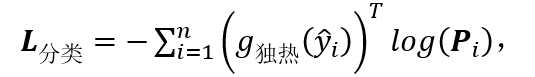
(10)
其中 表示将
表示将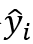 转换成独热向量的函数,表示一个袋中的图片数量,P_i 表示神经网络计算的行人类别的概率,是网络输出对数 z 的归一化指数函数:
转换成独热向量的函数,表示一个袋中的图片数量,P_i 表示神经网络计算的行人类别的概率,是网络输出对数 z 的归一化指数函数:
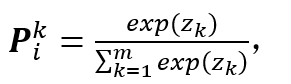
(11)
其中 m表示训练集的行人类别数量。 总损失函数 L 是这两个损失函数的线性组合:

(12)
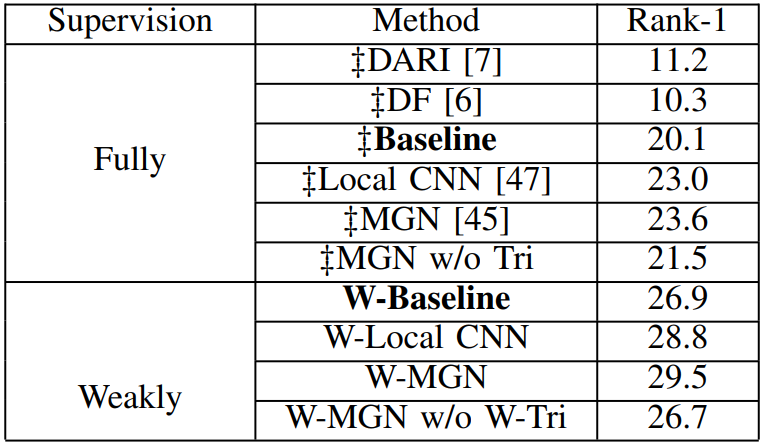
其中w_分类和w_图分别表示两个损失的权重,本方法设置为 1 和 0.5。 实验数据集。本文在 SYSU-30k 和 Market-1501 评估这种弱监督行人重识别方法,更多数据集分析见原文。Market-1501 数据集是一个广泛应用的大型行人重识别的基准数据集。Market-1501 数据集由 6 个摄像机拍摄得到,包含 32,668 张行人图像,共 1,501 个行人身份类别。数据集划分为两部分:12,936 张行人图像共 751 个行人身份类别作为训练集,19,732 张图像共 750 个行人身份作为测试集。在测试集中,3,368 张图像共 750 个行人图像通过手工截取作为查询集。 实验配置。研究者采用 ResNet-50 作为骨干网络,使用 ImageNet 预训练模型。其他参数使用正态分布进行初始化。实验使用 SGD 优化器。批次设置为 90,初始学习率为 0.01(全连接层初始学习率为 0.1)。冲量设置为 0.9,权重衰减设置为 0.0005,在单卡 GPU 上训练 SYSU-30k 大约需要 10 天。 实验结果 SYSU-30k 是一个弱监督行人重识别数据集,本文方法是弱监督行人重识别方法。由于传统全监督行人重识别方法不能直接在 SYSU-30k 数据集上训练,研究者利用迁移学习的方法将传统全监督行人重识别方法应用到 SYSU-30k 数据集上。具体地,6 种经典的全监督行人重识别模型(包括 DARI,DF,TriNet,Local CNN,MGN 和无 triplet 的 MGN)首先在 CUHK03 数据集上训练。然后,模型被应用于 SYSU-30k 数据集上进行跨数据集评估。而本文的弱监督行人重识别方法直接在 SYSU-30k 上训练并在 SYSU-30k 的测试集上测试。 研究者在 SYSU-30k 数据集上对比最先进的方法。如下表 2 所示,虽然本文方法使用的是弱监督学习方式,但 W-MGN 得到了最佳的效果(29.5%)。本文方法的有效性归因于以下两点:第一,图模型学习可以产生可靠的伪类标来补偿缺失的强标签;第二,SYSU-30k 数据集提供了丰富的知识来提升模型的能力,即使是以弱标签的方式给出。
研究者也提供了定性分析,可视化了 W-MGN 几张查询样本的检索结果,具体如下图 8 所示。每一行代表一个查询结果。第一张图为查询图,后面紧接着是按照相似性从大到小依次排序的结果。红色框代表和查询图身份类别匹配的行人图像。在失败的例子中,一些非匹配的行人图像相似性排名比真实匹配的行人图像还要高。非匹配的行人图像看起来更像查询图的行人类别。
图 8:SYSU-30k 数据集上 W-MGN 检索结果样例。 Market-1501 数据集是图像级别标注的行人重识别数据集。为了进行弱监督行人重识别评估,研究者利用该图像级别标注的数据集模拟产生袋级别的弱监督行人重识别数据集。具体而言,对于 Market-1501 的训练集,利用弱标签代替强标签;对于 Market-1501 的测试集,则保持不变。研究者将本文方法和全监督的行人重识别方法进行对比。对比方法包括 15 种经典的全监督方法,包括 MSCAN、DF、SSM、SVDNet、GAN、PDF、TriNet、TriNet + Era. + reranking、PCB 和 MGN。 对比结果如下表 3 所示。可以看出,本文方法可以获得竞争性的实验结果。比如,W-MGN 和 W-Local CNN 得到 95.5% 和 95.7% 的 rank-1 准确率,比很多全监督方法要好。这说明本文方法的有效性。
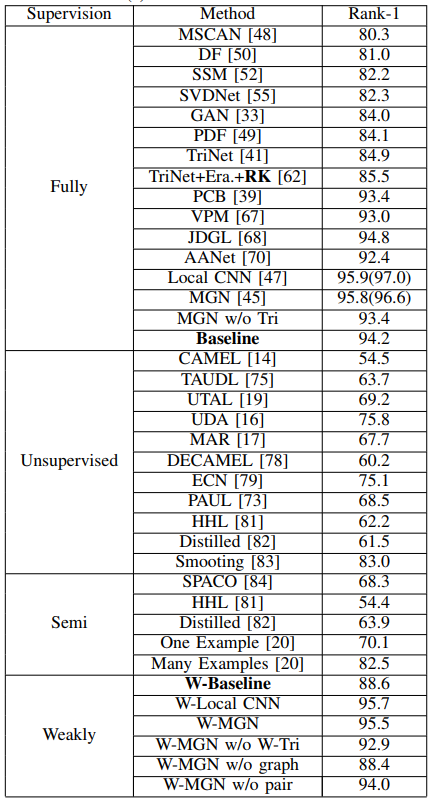
表 3:Market-1501 数据集上对比最先进的方法。
原文标题:可微图学习&弱监督,中山大学提出新型行人重识别方法和史上最大最新评测基准
文章出处:【微信公众号:通信信号处理研究所】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
神经网络
+关注
关注
42文章
4847浏览量
108484 -
人工智能
+关注
关注
1821文章
50552浏览量
267994 -
CV
+关注
关注
0文章
54浏览量
17696
原文标题:可微图学习&弱监督,中山大学提出新型行人重识别方法和史上最大最新评测基准
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
常见元器件的极性识别方法

传音相关研究成果入选计算机视觉顶会CVPR 2026

厚声电阻的精度标记识别方法

科技老登戴辉回顾 华南理工大学和我不得不说的故事

CET中电技术荣获广东省太阳能协会“年度优秀企业”及“年度影响力品牌-光伏电站运维单位”称号

第三届开放原子大赛vivo蓝河操作系统创新赛圆满收官
上海理工大学:直接发出圆偏振光的显示技术
电解电容极性的识别方法及注意事项

智汇虹科 | 中山大学原副校长李善民教授一行莅临虹科考察指导

AI+IMS工业软件新范式 | 盘古信息携手中山大学驱动IMS系统全面智能化升级

华为携手复旦大学附属中山医院打造智慧医疗全球标杆
中科曙光携手中山大学附属第一医院打造精准医学高性能计算平台
洲明数字文化科技与中山大学旅游学院达成战略合作
紫光同创携手中山大学助力集成电路产业创新人才培养
中山大学:用于呼吸识别和非接触式人机交互的均匀快速响应湿度场传感阵列的可扩展制备




评论