 赛灵思FPGA与VMware vSphere相结合实现高吞吐量、低时延ML推断性能
赛灵思FPGA与VMware vSphere相结合实现高吞吐量、低时延ML推断性能

硬件加速器已在数据中心得到普遍使用,一系列新的工作负载已经能够成熟地发挥 FPGA 的加速优势及其更优异的计算效率。业界对机器学习 (ML) 的关注度不断提高,推动 FPGA 加速器在私有云、公有云、混合云数据中心环境中日益普及,从而为计算密集型工作负载加速。近期,在推动 IT 基础设施向异构计算转型的过程中,赛灵思与 VMware 展开协作,在 VMware 的云计算虚拟化平台vSphere上测试 FPGA 加速。由于赛灵思 FPGA 越来越广泛地应用于 ML 推断加速,本文将展示的是如何将赛灵思 FPGA 与 VMware vSphere 相结合,在虚拟部署和裸机部署上实现基本相同的高吞吐量、低时延 ML 推断性能。
FPGA 是一种自适应计算器件,能够灵活地进行重新编程,从而满足目标应用不同的处理需求和功能要求。该特性使 FPGA 从 GPU 和 ASIC 等架构固定的器件中脱颖而出,更是远远优于成本不断飙升的的定制 ASIC。此外,与其他硬件加速器相比,FPGA 还具备高能效、低时延的优势,使 FPGA 特别适用于 ML 推断工作。与基本依靠大量并行处理核心实现高吞吐量的 GPU 不同的是,FPGA 通过定制化硬件内核、数据流流水线和互联,助力 ML 推断同时实现高吞吐量和低时延。
01. 在 vSphere 上使用 FPGA 开展 ML 推断
VMware 在其实验室中使用赛灵思 Alveo U250 数据中心卡进行测试。使用在Vitis AI中提供的 Docker 容器——为从边缘到云端的赛灵思硬件平台提供的 ML 推断统一开发栈,ML 模型可以迅速完成配置。该容器由经过优化的工具、库、模型和示例构成。Vitis AI 支持含 Caffe 和 TensorFlow 在内的主流框架以及能够执行多种深度学习任务的最新模型。此外,Vitis AI 是一种开源应用,可通过访问GitHub获取。
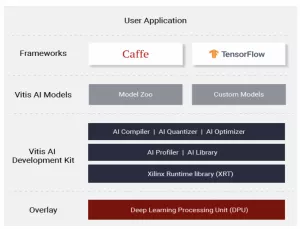
图 1:Vitis AI 软件协议栈
目前,赛灵思 FPGA 通过 DirectPath I/O 模式(直通模式)能在 vSphere 上使用。在这种模式下,我们的 FPGA 能够由运行在虚拟机内部的应用直接访问,绕过程序管理层,从而最大化性能并最大限度降低时延。配置 DirectPath I/O 模式下的 FPGA 只需简单的两步流程:首先,在主机层面上启用 ESXi,然后将器件添加到目标虚拟机。详细操作方法参见 VMware KB 一文( https://kb.vmware.com/s/article/1010789 )。请注意,如果运行的是 vSphere 7,则不再需要重启主机。
02. 高吞吐量、低时延 ML 推断性能
通过与赛灵思合作,VMware 使用四个 CNN 模型执行推断任务,对我们的 Alveo U250 加速器卡在 DirectPath I/O 模式工作下的吞吐量和时延性能进行评估。这四个模型分别为Inception_v1、Inception_v2、Resnet50 和 VGG16。这些模型在模型参数数量上不尽相同,因而具备不同的处理复杂性。
测试在搭载两颗 10 核 Intel Xeon Silver 4114 CPU 和 192GB DDR4 存储器的 Dell PowerEdge R740 服务器上进行。我们使用 ESXi 7.0 虚拟机程序管理器,将每种模型的端到端性能结果与作为基线的裸机性能进行对比。Ubuntu 16.04(内核版本 4.4.0-116)用作客户端操作系统和本地操作系统。此外,在整个测试过程中将 Vitis AI v1.1 与 Docker CE 19.03.4 结合使用。同时使用源于 ImageNet2012 的 50k 图像数据集。为进一步避免图像读取过程中遭遇磁盘瓶颈,还创建了一个 RAM 磁盘用于存储 50k 图像。
完成这些设置后,虚拟测试和裸机测试之间的性能比较可从下面的两个图中进行观察。一个针对吞吐量,另一个针对时延。y 轴代表虚拟测试和裸机测试间的吞吐量性能比值。y=1.0 代表虚拟测试和裸机测试的吞吐量性能结果相同。
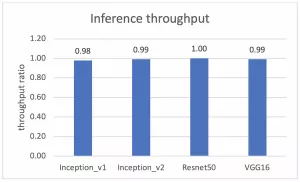
图 2:在 Alveo U250 FPGA 上运行 ML 推断时裸机测试和虚拟测试的吞吐量性能比较
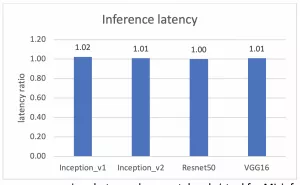
图 3:在 Alveo U250 FPGA 上运行 ML 推断时裸机测试和虚拟测试的时延性能比较
测试证明,虚拟环境和裸机间在吞吐量和时延两方面的性能差距最大不超过 2%。这说明在虚拟环境中运行在 vSphere 上的 Alveo U250 的 ML 性能与作为基线的裸机性能极为相近。
03. 云端的 FPGA 性能
在数据中心中采用 FPGA 加速器已成为普遍现象,而且为满足对异构计算和性能提升的需求,FPGA 加速器的应用还将继续增长。我们非常高兴能够与 VMware 展开合作,共同确保客户能充分发挥运行在 vSphere 平台上的赛灵思 FPGA 加速的全部优势。我们在 vSphere 上对我们的 Alveo U250 加速器卡进行 ML 推断性能测试,成功地向客户证明了该器件在 DirectPath I/O 模式下能够实现接近裸机的性能。
编辑:hfy
-
FPGA
+关注
关注
1655文章
22283浏览量
630278 -
赛灵思
+关注
关注
33文章
1797浏览量
133148 -
云计算
+关注
关注
39文章
8003浏览量
143100 -
机器学习
+关注
关注
66文章
8541浏览量
136233
发布评论请先 登录
数据吞吐量提升!面向下一代音频设备,蓝牙HDT、星闪、Wi-Fi、UWB同台竞技
使用罗德与施瓦茨CMX500的吞吐量应用层测试方案

TensorRT-LLM中的分离式服务

友思特方案 | FPGA 加持,友思特图像采集卡高速预处理助力视觉系统运行提速增效
如何评估协议分析仪的性能指标?
u-blox发布首款车规级Wi-Fi 7模块RUBY-W2
Altera SoC FPGA如何助力实现AI信道估计
CY7C65211 作为 SPI 从机模式工作时每秒的最大吞吐量是多少?
如何在Visual Studio 2022中运行FX3吞吐量基准测试工具?
FX3进行读或写操作时CS信号拉低,在读或写完成后CS置高,对吞吐量有没有影响?
国产EDA亿灵思®接入DeepSeek

高通吞吐量超高精度加工






 工商网监
工商网监
评论