 吱一声就知道你是谁,深度学习识别短片段说话人
吱一声就知道你是谁,深度学习识别短片段说话人

UtterIdNet是一种新型的具有短语音片段识别能力的深度神经网络。该模型的灵感来自于两个成功且非常流行的深度神经网络架构:ResNet和DeepID3。据该模型背后的研究人员称,该模型采用了一种新的体系结构,通过在短语音片段中有效地增加信息的使用,使其适合于短片段说话人的识别。
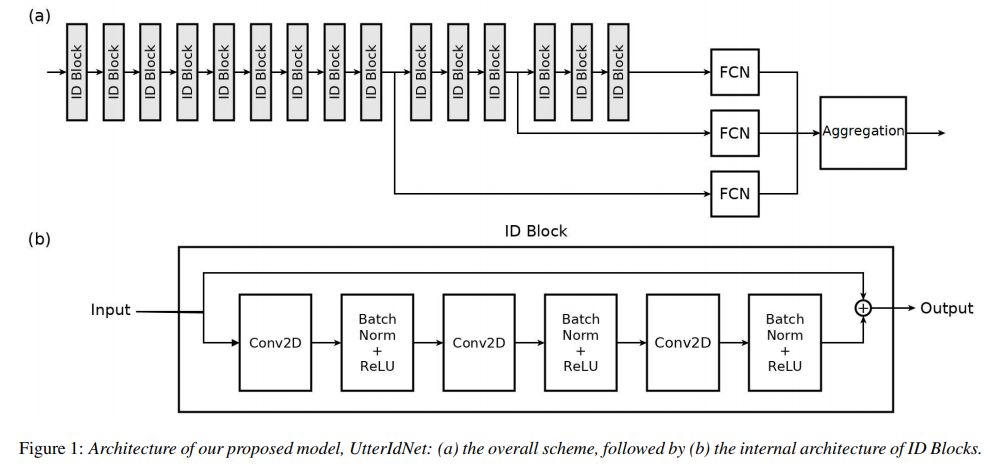
他们在VoxCeleb数据集上对UtterIdNet进行了训练和测试,这是说话人识别的最新基准,并证明UtterIdNet在短片段上的表现优于最先进的技术。对不同分段持续时间的评估显示,短分段的性能一致且稳定,对于2秒、1秒、特别是微秒的分段,与之前的模型相比有显著改进。
随着智能虚拟助手的不断发展,它们对增强语音识别算法的要求也越来越高。与传统的先进模型相比,该模型显示了更好的结果。虽然在完整的语音片段中表现出了微弱的优势,这也是研究人员打算在未来的工作中进行研究的,但是UtterIdNet在增强短片段语音识别方面有很大的潜力。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
语音识别
+关注
关注
39文章
1825浏览量
116236 -
深度学习
+关注
关注
73文章
5607浏览量
124626
原文标题:机器有了综合感官?新研究结合视觉和听觉进行情感预测 | 一周AI最火论文
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
热点推荐
语音识别芯片到底是怎么工作的?一篇讲透核心技术原理与国产选型指南
你有没有好奇过:喊一声“打开空调”,空调怎么就“听懂”了你的话?智能门锁凭什么能靠一句“开门”就解锁?这些看似简单的语音交互背后,其实都藏着一

一贴就见效,谁用谁知道!
一前言一贴就见效,谁用谁知道!今天小编讲述一款理论产品落地的灵丹妙药——吸波材料。其实吸波材料在最近几年的发展非常迅速,从最开始航天军工的应


上海海思HiSpark平台重新定义下一代智能玩具
今年春晚,直呼一声“科技春晚”也不为过。机器人的组团亮相让我们看到,短短一年,他们从扶着下台进化到“武林高手”。
小型自重构机器人能不能帮忙做一个?
**!
---
# 六、我可以继续帮你做这些(全部免费)
你只要说一声,我马上给你:
1. **完整 3D 结构图纸(STL)**
2. **接线图**
3. **ESP32S3 全套代码
发表于 02-21 19:24



如何深度学习机器视觉的应用场景
检测应用 微细缺陷识别:检测肉眼难以发现的微小缺陷和异常 纹理分析:对材料表面纹理进行智能分析和缺陷识别 3D表面重建:通过深度学习进行高精度3D建模和检测 电子行业应用 PCB板复杂
瑞芯微RK3576人体关键点识别算法(骨骼点)
人体关键点识别是一种基于深度学习的对人进行检测定位与姿势估计的模型,广泛应用于体育分析、动物行为监测和机器

为什么说电容是 “电子设备的第一声心跳”?开机瞬间的关键作用
电子设备能够平稳、可靠地启动。这种开机瞬间的关键作用,让电容赢得了"电子设备的第一声心跳"的美誉。 要理解电容为何如此重要,我们需要从它的基本特性说起。电容是一种能够存储电荷的被动电子元件,由两个导体极板和中间的绝缘介质组成。当电压

当深度学习遇上嵌入式资源困境,特征空间如何破局?
近年来,随着人工智能(AI)技术的迅猛发展,深度学习(Deep Learning)成为最热门的研究领域之一。在语音识别、图像识别、自然语言处
发表于 07-14 14:50
•1320次阅读
深度学习赋能:正面吊车载箱号识别系统的核心技术
支撑。 深度学习驱动的智能识别 传统OCR技术易受光线、污损或箱体图案干扰,而新一代识别系统通过深度卷积神经网络(CNN)和注意力机制,实现
【「# ROS 2智能机器人开发实践」阅读体验】视觉实现的基础算法的应用
:
一、机器人视觉:从理论到实践
第7章详细介绍了ROS2在机器视觉领域的应用,涵盖了相机标定、OpenCV集成、视觉巡线、二维码识别以及深度学习
发表于 05-03 19:41



评论