卷积是一种线性运算,其本质是滑动平均思想,广泛应用于图像滤波。而随着人工智能及深度学习的发展,卷积也在神经网络中发挥重要的作用,如卷积神经网络。本参考设计主要介绍如何基于INTEL 硬浮点的DSP
2018-07-23 09:09:45 7322
7322 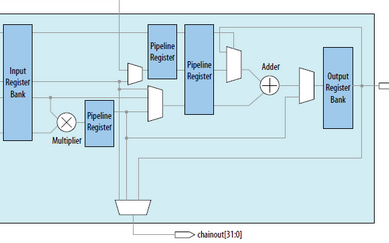
FPGA中DSP资源是宝贵的且有限,我们在计算大位宽的指数、复数乘法、累加、累乘等运算时都会用到DSP资源,如果我们不了解底层的DSP特性,很多设计可能都无法进行。逻辑综合往往是不可控的,为了能够
2020-09-30 11:48:5526638 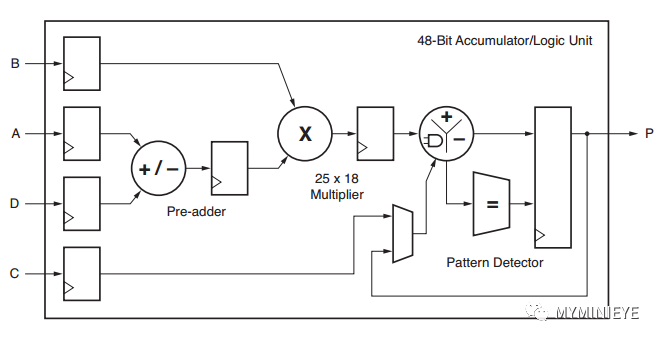
DSP48E2是zynq器件中使用的DSP类型,其主要结构包括一个27bit前加器,27x18bit的乘法器,一个48bit的可以执行加减法,累加以及逻辑功能的ALU。
2022-08-02 09:16:273378 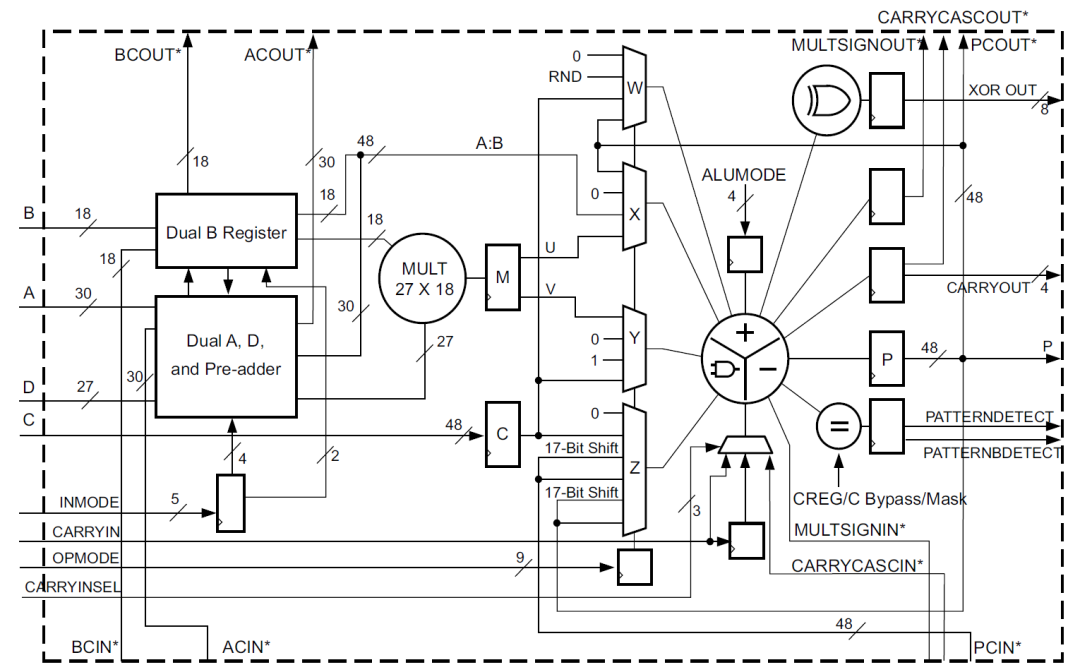
人工智慧隶属于大範畴,包含了机器学习(Machine Learning) 与深度学习(Deep Learning)。如下图所示,我们最兴趣的深度学习则是规範于机器学习之中的一项分支,而以下段落将简单介绍机器学习与深度学习的差异。
2020-12-18 15:45:313870 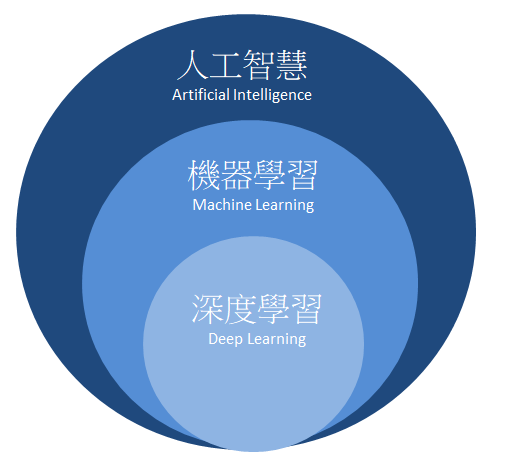
乘法器和一个三输入加法器/减法器/累加器。DSP48E1乘法器具有非对称的输入,接受18位2的补数操作数和25位2的补数操作数。乘法器阶段以两个部分乘积的形式产生一个43位2的补码结果。这些部分积在X
2021-01-08 16:46:10
7系列FPGA DSP48E1片的特点什么
2021-03-05 06:26:41
我正在实例化DSP切片并进行简单的乘法然后加法((A * B)+ C)。根据DSP48E1用户指南,当使用所有三个流水线寄存器时,它给出了最高频率为600 MHz。但就我而言,它使用流水线寄存器
2020-06-12 06:32:01
嗨,我有一个如下的指令:(D-A)* B + C.端口A,B,C,D与DSP48E1输入引脚相对应。我试图将整个操作打包在DSP单元中。 (顺便说一句,我的数据宽度是8位)在布局和布线完成后,我
2019-04-01 14:25:40
to use a DSP48E1 slice to delay data up to 48bits wide by three cycles and hence only use 1 DSP48 rather
2019-04-18 06:40:33
DSP48E1属性
2021-01-27 06:21:23
和RSTB复位(如图2-7和图2-8所示)。 P端口 每个DSP48E1片都有一个48位的输出端口p。这个输出可以通过PCOUT路径内部连接(级联连接)到相邻的DSP48E1片。PCOUT连接
2020-12-23 16:54:08
Memory,开启cache。 如DSP能对SDRAM的不同4个bank可以同时访问,此时你可以将需要同时运算的数据放入不同的bank (8)开启仿真软件的编译优化选项 在菜单相应的地方勾上
2011-10-19 10:31:23
,51的指令是一条一条的执行,DSP的指令可以多条并行处理,从而获得了更快的计算速度。2、运算能力。很多DSP器件硬件支持浮点数乘法,同时有硬件循环指令。硬件浮点乘法极大的提高了运算能力。硬件循环指令
2012-01-11 09:28:20
一、int8的输出和fp32模型输出差异比较大
解决方案:
检查前后处理是否有问题,int8网络输入输出一般需要做scale处理,看看是否遗漏?
通过量化可视化工具分析int8的输出和fp32
2023-09-19 06:09:33
深度学习常用模型有哪些?深度学习常用软件工具及平台有哪些?深度学习存在哪些问题?
2021-10-14 08:20:47
时间安排大纲具体内容实操案例三天关键点1.强化学习的发展历程2.马尔可夫决策过程3.动态规划4.无模型预测学习5.无模型控制学习6.价值函数逼近7.策略梯度方法8.深度强化学习-DQN算法系列9.
2022-04-21 14:57:39
CPU优化深度学习框架和函数库机器学***器
2021-02-22 06:01:02
具有深度学习模型的嵌入式系统应用程序带来了巨大的好处。深度学习嵌入式系统已经改变了各个行业的企业和组织。深度学习模型可以帮助实现工业流程自动化,进行实时分析以做出决策,甚至可以预测预警。这些AI
2021-10-27 06:34:15
机器学习 (ML) 是云和边缘基础设施中增长最快的部分之一。在 ML 中,深度学习推理预计会增长得更快。在本博客中,我们比较了三种 Amazon Web Services (AWS) EC2 云实例
2022-08-31 15:03:46
1. 简介随着人工智能的普及,深度学习网络的不断涌现,为了让各硬件(CPU, GPU, NPU,…)能够支持深度学习应用,各硬件芯片需要软件库去支持高性能的深度学习张量运算。目前,这些高性能计算库
2021-12-14 06:18:21
L2cache
2.2 峰值算力
峰值算力:
FP32峰值算力 = 64 * 16 * 2(FP32 MAC) * 2 * 0 55G / 1024 = 2.2 TOPS
INT8峰值算力 = 64
2023-09-19 08:11:10
学习,也就是现在最流行的深度学习领域,关注论坛的朋友应该看到了,开发板试用活动中有【NanoPi K1 Plus试用】的申请,介绍中NanopiK1plus的高大上优点之一就是“可运行深度学习算法的智能
2018-06-04 22:32:12
`Nanopi深度学习之路这一系列的日记内容如下:1. 根据深度学习任务配置Nanopi2。2. 在Nanopi2上安装Keras和TensorFlow。3. 在Nanopi2上部署一个训练好的深度
2018-06-05 17:29:51
DSP(Digital Signal Processor)和 EVE(Embedded Vision/Vector Engine),用于加速计算深度学习神经网络。相比于上一代TDA2/TDA3系列
2022-11-03 06:53:11
UltraScale DSP48 Slice架构的优势是什么?UltraScale内存架构的优势是什么?
2021-05-24 06:34:00
the slice, can't I use the DSP48A1 macro itself to test this Xapp706 application?
2019-07-04 15:36:07
,这样的输入选择有助于构建多种类型,高流水化的DSP应用。
2. DSP48E1使用
(1)DSP原语使用的每个端口及位宽如下所示:
①表示的数据通道,运算数据的输入。
②寄存器配置通道,我们可以通过
2023-06-20 14:29:51
model_deploy.py --mlir yolov5l.mlir --quantize INT8 --calibration_table yolov5l_cali_table --chip
2024-01-10 06:40:14
,使其更紧凑和更易debug,并提供了扩展的便利性。 课程内容基本上是以代码编程为主,也会有少量的深度学习理论内容。课程会一步一步从Keras环境安装开始讲解,并从最基础的Keras实现线性回归
2018-07-17 11:40:31
caffe模型(浮点),得到int8的模型,再通过sdk编程,直接部署到FPGA上,这个过程本质上应该还是使用了SDSoC的相关工具。 大佬们开发了DPU这个深度学习的IP,在不远的将来要放置到
2019-03-21 15:09:29
申请理由:1)由于刚接触到DSP不久,希望通过DSP的开发板能够快速入门,前期实现一些基本的功能;2)在学习到DSP的一些基本知识后,将逐渐运用DSP的实际项目中,先试着尝试解决一些振动数据分析
2015-09-10 11:20:00
计算公司赛灵思(NASDAQ:XLNX)宣布,收购北京人工智能(AI)芯片初创公司深鉴科技。深鉴科技拥有业界较为领先的机器学习能力,专注于神经网络剪枝、深度压缩技术及系统级优化。深鉴科技原本是一家芯片
2020-12-10 15:23:40
开始的,相比传统的CPU和GPU,在深度学习运算能力上有比较大幅度的提升。接下来在RV1109和RV1126上使用了第二代NPU,提升了NPU的利用率。第三代NPU应用在RK3566和RK3568上
2022-06-23 15:05:22
深度学习是什么意思
2020-11-11 06:58:03
,即使使用具有一定低位宽的数据,深度学习推理也不会降低最终精度。目前据说8位左右可以提供稳定的准确率,但最新的研究表明,已经出现了即使降低到4位或2位也能获得很好准确率的模型和学习方法,越来越多的正在
2023-02-17 16:56:59
本文阐述了Spartan-3 FPGA针对DSP而优化的特性,并通过实现示例分析了它们在性能和成本上的优势。
2019-10-18 07:11:35
矩阵乘,则可使用 B 与 A 矩阵乘之后进行转置进行替换,可节约一次转置运算。b. 算子融合是常见的深度学习的优化手段。算子融合虽然不能减少计算量,但是可以减少访存量,提高计算访存比,从而提升性能
2023-02-09 16:35:34
1323%DSP48E1的数量168641%设备利用率摘要(估计值)[ - ]逻辑利用用过的可得到采用切片寄存器的数量38695068736056%切片LUT的数量15269234368044%完全
2019-03-25 14:27:40
嗨,我想使用DSP45E1模块实现Multply-Add操作,其中一个要求是我需要DSP模块上的3级流水线。查看UG479 7系列DSP48E1 Slice用户指南(UG479) - Xilinx
2020-07-21 13:52:24
DSP48E1片的数学部分由一个25位的预加器、2个25位、18位的补法器和3个48位的数据路径多路复用器(具有输出X、Y和Z)组成,然后是一个3输入加法器/减法器或2输入逻辑单元(参见图2
2021-01-08 16:36:32
简化DSP48E1片操作
2021-01-27 07:13:57
切片是整个切片数量的一部分还是它们在FPGA上共享资源?2)如果我们没有进行任何DSP操作,那么DSP48E Slice是否可以用于实现某些常规逻辑,或者这些DSP Slice是否专门用于实现DSP
2019-04-04 06:36:56
DSP48E1磁贴(由2个切片和互连组成)与5个CLB具有相同的高度1 DSP48E1瓷砖与一个BRAM36K具有相同的高度1 DPS48E1 Slice水平对齐BRAM18K我读到了xilinx asmbl架构
2020-07-25 11:04:42
求大神指教:在labview的公式节点中如何定义一个静态变量(例如:static int8 i=0;这样可以吗?)
2016-04-13 21:37:29
的体系结构,熟练使用相关开发调试工具,擅长软件性能分析和优化,能在紧约束条件下充分利用硬件资源,深度优化提升软件效率; 8、勇于承担责任,良好的沟通能力和团队合作精神; 9、较好的英文阅读能力。 有兴趣的朋友,请联系我,企鹅号码:1537906585
2016-05-04 17:40:52
嗨,我正在使用两个使用级联链路连接的DSP48切片来执行所需的操作。我想尝试多泵操作以有效地使用DSP48切片。请提供DSP48 slice中的Multipumping示例。提前致谢
2019-08-06 10:42:26
本帖最后由 一只耳朵怪 于 2018-6-13 16:29 编辑
大家好,使用28335也有1年多了,这个数制问题一直困扰我,就是如何自己定义8位的int型整数?在网上搜到的 typedef CPU_INT08U uint8; //[0 255],这个能用么?谢谢大家~
2018-06-13 04:13:04
本帖最后由 一只耳朵怪 于 2018-6-25 14:58 编辑
不能是INT16字型的?INT8精度不够呀~
2018-06-25 01:12:25
与采用旧 CPU 的推理相比,在新 CPU 上推断的 INT8 模型的推理速度更快。
2023-08-15 08:28:42
High DSP Performance Platform– The DSP48E Slice– Essential DSP Building Blocks• Imaging Algorithms
2009-04-09 22:05:31 12
12 本文简要介绍了MPEG4-SP在DSP TM1300上的实现和优化过程。分析了其性能优化原理,给出了性能优化中使用到的几个技巧,最终取得了满意的优化效果。
2009-05-09 14:14:4513 CDMA网络深度覆盖的天线应用与RSSI指标优化分析,很好的网络资料,快来学习吧。
2016-04-19 11:30:4823 、乘加(MACC, ),乘加,三输入加法等等。该架构还支持串联多个DSP48E1 slice,避免使用fpga逻辑功能的繁琐。 System generator DSP48E1 模块参数 双击dsp48e1模块
2017-02-08 01:07:12595 
UltraScale DSP48E2 Slice 完美结合在一起。Prodigy KU 逻辑模块理想适用于计算密集型应用;根据 S2C 的介绍,该模块提供的 DSP 资源比市场上任何原型板都要多。除了数千
2017-02-08 12:19:14884 为了适应越来越复杂的DSP运算,Spartan-6在Spartan 3A DSP模块DSP48A 基础上,不断进行功能扩展,推出了功能更强大的DSP48A1 SLICE。
2017-02-11 08:53:13992 
为了适应越来越复杂的DSP运算,Virtex-6中嵌入了功能更强大的DSP48E1 SLICE,简化的DSP48E1模块如图5-16所示。
2017-02-11 09:17:131391 
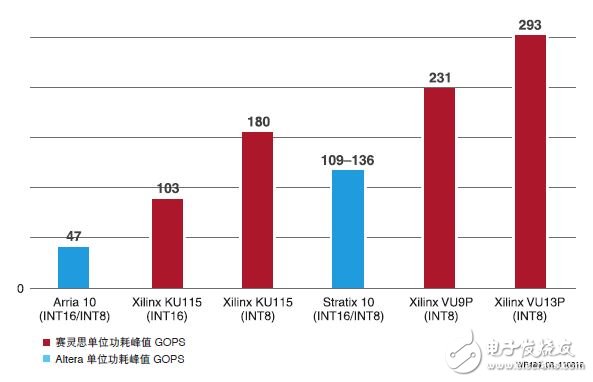
赛灵思 INT8 优化为使用深度学习推断和传统计算机视觉功能的嵌入式视觉应用提供最优异的性能和能效最出色的计算方法。与其他 FPGA/DSP 架构相比,赛灵思的集成 DSP 架构在 INT8 深度学习运算上能实现 1.75 倍的性能优势。
2017-09-22 17:27:115280 类库,用数组向量来定义和计算数学表达式。它使得在Python环境下编写深度学习算法变得简单。在它基础之上还搭建了许多类库。Keras是一个简洁、高度模块化的神经网络库,它的设计参考了Torch,用Python语言编写,支持调用GPU和CPU优化后的Theano运算。
2017-11-16 14:20:452873 这篇论文对于使用深度学习来改进IoT领域的数据分析和学习方法进行了详细的综述。
2018-03-01 11:05:127452 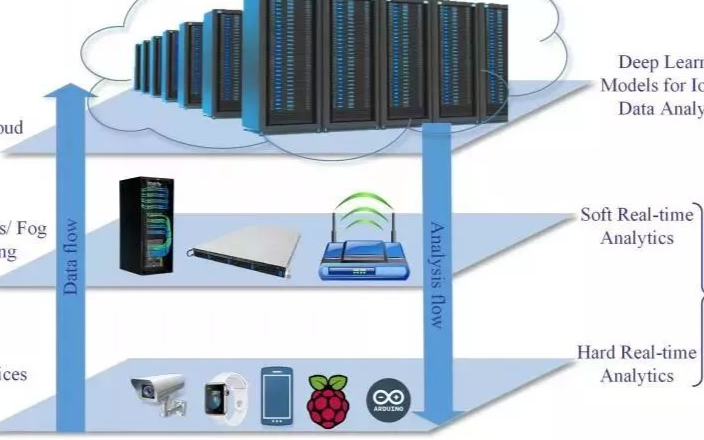
在研究基于大数据框架将深度学习的分布式实现后,王万良指出,人工智能是大数据分析领域的研究主流,基于深度学习的大数据分析方法发展最为迅速,GPU成为深度学习的更高效的硬件平台,研究分布式计算智能优化算法将解决大数据优化问题,能够提升算法的效果并降低计算复杂度。
2018-09-26 16:56:138879 了解如何为UltraScale +设计添加额外的安全级别。
该视频演示了如何防止差分功耗分析(DPA),以在比特流配置之上增加额外的安全性。
2018-11-27 06:24:002667 本视频介绍了7系列FPGA的DSP Slice功能。
此外,还讨论了Pre-Adder和Dynamic Pipeline控制资源。
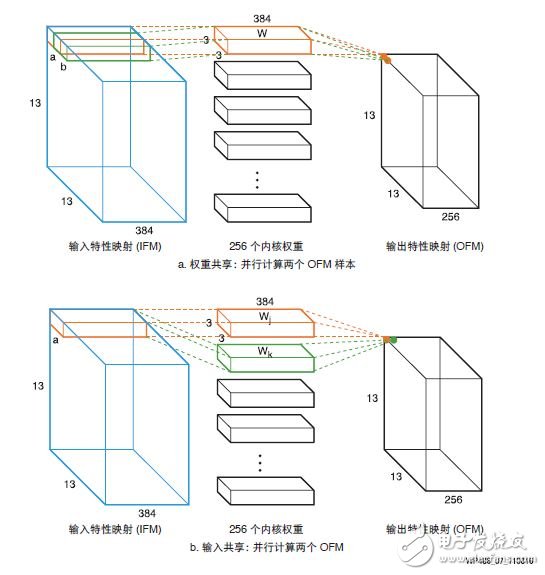
2018-11-26 06:02:006700 赛灵思的 DSP 架构和库针对 INT8 运算进行了精心优化。本白皮书介绍如何使用赛灵思 16nm 和 20nm All Programmable 器件中的 DSP48E2 Slice,在共享相同内核权重的同时处理两个并行的 INT8 MACC 运算。
2019-07-29 11:19:322303 要使用可编程逻辑上的 DSP 实现中值滤波器,可以对算法做改动。每次比较运算可以分为减法运算及后续的符号位检查。对减法运算,DSP48E2 Slice 能够以四个 12 位或两个 24 位模式进行运算。要充分利用 DSP48E2 Slice,可以并行运算多个像素。
2019-07-30 08:59:462913 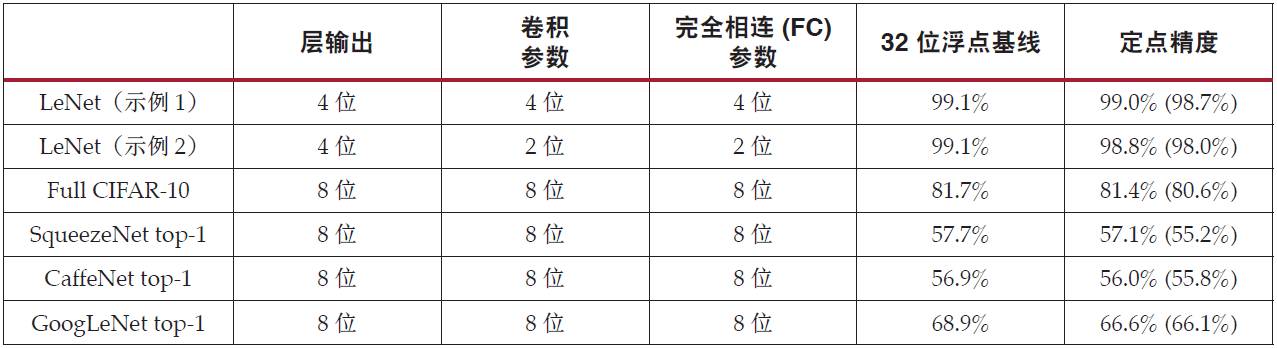
晶心科技今日宣布将携手合作,在基于AndeStar™ V5架构的晶心RISC-V CPU核心上配置高度优化的深度学习模型,使AI深度学习模型变得更轻巧、快速和节能。
2019-12-31 16:30:111002 Intel近日发布了最新版的高性能深度学习优化库DNNL 1.2,证实即将推出的全新Xe架构独立GPU的一项新技能,那就是支持Int8整数数据类型。
2020-02-04 15:31:191258 在深度学习中,有很多种优化算法,这些算法需要在极高维度(通常参数有数百万个以上)也即数百万维的空间进行梯度下降,从最开始的初始点开始,寻找最优化的参数,通常这一过程可能会遇到多种的情况
2020-08-28 09:52:452268 
DSP48最早出现在XilinxVirtex-4 FPGA中,但就乘法器而言,Virtex-II和Virtex-II Pro中就已经有了专用的18x18的乘法器,不过DSP48可不只是乘法器,其功能
2020-10-30 17:16:515770 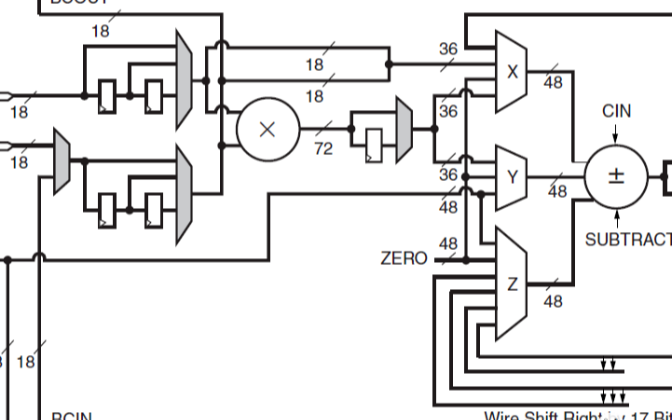
深度学习是机器学习与神经网络、人工智能、图形化建模、优化、模式识别和信号处理等技术融合后产生的一个领域。
2020-11-05 09:31:194711 A、B、C、CARRYIN、CARRYINSEL、OPMODE、BCIN、PCIN、ACIN、ALUMODE、CARRYCASCIN、MULTSIGNIN以及相应的时钟启用输入和复位输入都是保留端口。D和INMODE端口对于DSP48E1片是唯一的。本节详细描述DSP48E1片的输入端口
2022-07-25 18:00:184429 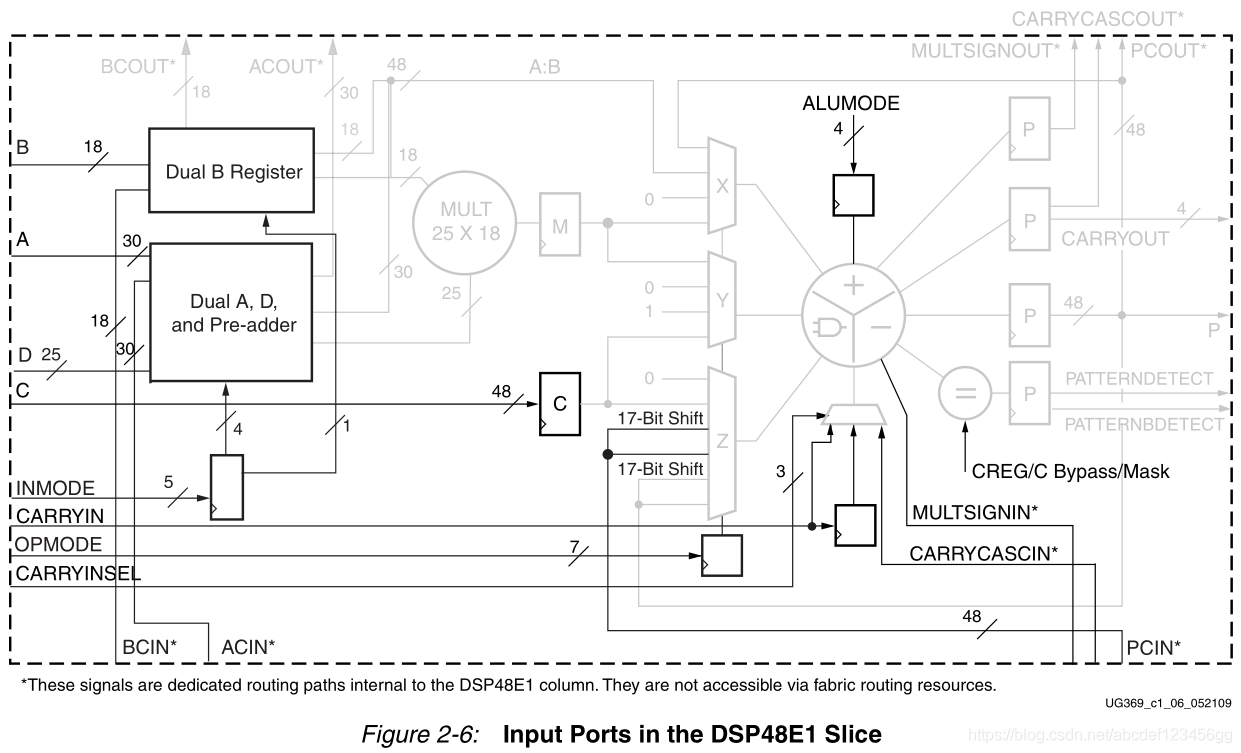
在DSP48E1列中,级联各个DSP48E1片可以支持更高级的DSP功能。两个数据路径(ACOUT和BCOUT)和DSP48E1片输出(PCOUT、MULTSIGNOUT和CARRYCASCOUT)提供级联功能。级联数据路径的能力在过滤器设计中很有用。
2021-01-27 07:34:328 A、B、C、CARRYIN、CARRYINSEL、OPMODE、BCIN、PCIN、ACIN、ALUMODE、CARRYCASCIN、MULTSIGNIN以及相应的时钟启用输入和复位输入都是保留端口。D和INMODE端口对于DSP48E1片是唯一的。本节详细描述DSP48E1片的输入端口
2021-01-27 08:18:022 深度模型中的优化与学习课件下载
2021-04-07 16:21:013 2020年开始,新手机 CPU 几乎都是 armv8.2 架构,这个架构引入了新的 fp16 运算和 int8 dot 指令,优化得当就能大幅加速深度学习框架的...
2022-01-26 18:53:190 本文是对NCNN社区int8模块的重构开发,再也不用担心溢出问题了,速度也还行。作者:圈圈虫首发知乎传送门ncnnBUG1989/caffe-int8-conver...
2022-02-07 12:38:261 FasterTransformer BERT 包含优化的 BERT 模型、高效的 FasterTransformer 和 INT8 量化推理。
2023-01-30 09:34:481283 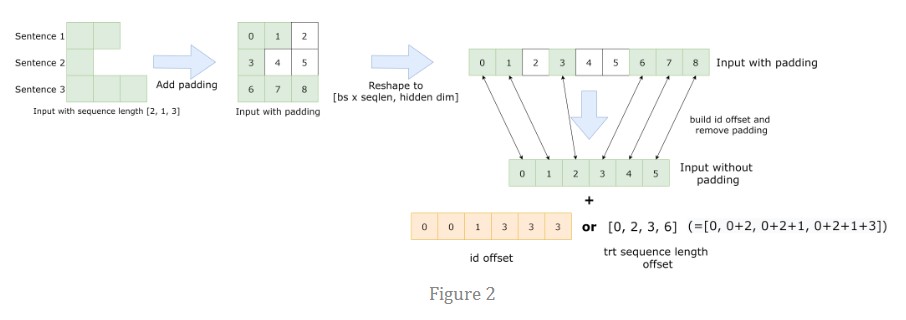
先大致讲一下什么是深度学习中优化算法吧,我们可以把模型比作函数,一种很复杂的函数:h(f(g(k(x)))),函数有参数,这些参数是未知的,深度学习中的“学习”就是通过训练数据求解这些未知的参数。
2023-02-13 15:31:481019 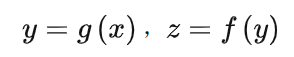
继续深度学习编译器的优化工作解读,本篇文章要介绍的是OneFlow系统中如何基于MLIR实现Layerout Transform。
2023-05-18 17:32:42389 FasterTransformer BERT 包含优化的 BERT 模型、高效的 FasterTransformer 和 INT8 量化推理。
2023-05-30 15:15:15905 
电子发烧友网站提供《PyTorch教程12.1之优化和深度学习.pdf》资料免费下载
2023-06-05 15:08:410 12.1. 优化和深度学习¶ Colab [火炬]在 Colab 中打开笔记本 Colab [mxnet] Open the notebook in Colab Colab [jax
2023-06-05 15:44:30327 
深度学习模型量化支持深度学习模型部署框架支持的一种轻量化模型与加速模型推理的一种常用手段,ONNXRUNTIME支持模型的简化、量化等脚本操作,简单易学,非常实用。
2023-07-18 09:34:572200 
INT8量子化PyTorch x86处理器
2023-08-31 14:27:07453 
可视化其他量化形式的engine和问题engine进行对比,我们发现是一些层的int8量化会出问题,由此找出问题量化节点解决。
2023-11-23 16:40:20531
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论