 高速率低延时Viterbi译码器的设计与实现
高速率低延时Viterbi译码器的设计与实现
摘要:
在Vitebi译码器的实现中,由于路径存储方式的不同分为回溯和寄存器交换模式,效果是延时与资源消耗一般只能二取其一,互为矛盾。采取3~6长度的RE-寄存器交换,混合回溯模式,极大地减少了回溯时间,并减少了路径存储空间需求,付出的代价是每ACS增加2~5 LUT;再结合其他Viterbi译码器优化算法,如分支度量一次计算,每ACS查找——即4选1等措施,实现了高吞吐量(340 Mb/s)、低延时、低资源消耗的全并行Viterbi译码器。
0 引言
Viterbi译码是1967年由VITERBI A J提出的一种概率译码算法,且是最大似然译码法。后来发现,这种算法可用于多种数字估值问题,如码间干扰下的判决、连续相位FSK信号的最佳接收、语词识别、序列跟踪和源编码等。Viterbi算法的这些应用都可以归结为时间离散、状态有限的马氏过程的最佳估值问题,因而它不仅是卷积码的一种重要译码算法,而且在理论上也有较大意义。
由于卷积码优良的纠错性能和Viterbi硬件译码器简单(容易实现高速译码),被广泛应用于深空通信、卫星通信、IEEE 802.11、超宽带(UWB)系统、DAB、DVB、2G、3G、LTE、Wimax以及电力线通信中。
自1986年以来,国际上发表了很多关于Viterbi译码器设计的文章,如文献[1]~[6]。为追求译码速度,大多采用全并行结构,吞吐量可高达1.74 Gb/s[3]、2.8 Gb/s[4],同时目前各大FPGA厂商都已经提供了很多的IP核[7]。
由于内部互连机制不同,基于FPGA的译码器与结构化ASIC以及定制ASIC的工作速度不可同日而语,在FPGA上实现的译码器工作频率一般在140~510 MHz[6,7]之间,同样的设计结构若采取定制ASIC实现,应能达到与文献[3-4]相近的工作频率(800 MHz~1.4 GHz)。
从工程应用角度看,对Viterbi 译码器的性能评价指标主要有译码速度、处理时延和资源占用等。传统的Viterbi译码器结构难以兼具资源消耗少和时延小的优点。而在高速通信系统中,很多时候对译码时延要求很高。本文提出了一种采用部分寄存器交换的办法可兼顾译码延时和消耗逻辑资源的性能。测试结果表明,采用这种部分寄存器交换的回溯方式存储幸存路径,具有寄存器交换时延小的优点,而所需逻辑资源与普通回溯法相当,所需存储单元大大小于普通回溯法。
1 部分寄存器交换方式的路径存储
1.1 传统的路径存储
幸存路径存储器的结构主要有两种:一种是寄存器交换结构(RE),另一种是回溯结构(TB)[1-2]。
前者采用专用寄存器作为存储主体,存储的是路径上的输入信号信息,利用数据在寄存器阵列中的不断交换来实现译码。这种方法虽然具有存储单元少、译码延时短的优点,但由于其内连关系过于复杂, 功耗大(每个新判决比特输入时寄存器都要翻转),不适合大状态Viterbi译码器的FPGA实现。
回溯法利用通用的RAM作为存储主体,存储的是幸存路径的格状连接关系,通过读写RAM来完成数据的写入和回溯输出。其优点是内连关系简单、规则;缺点一是译码延时大——一般并行译码时回溯法的延时是寄存器交换法的4倍,缺点二是存储单元要求多。具体性能区别分析如下。
设卷积码编码约束长度为L,译码深度V=6×L;对码率R=1/2的译码器而言,每系统时钟输入2 bit编码传输信息,输出1 bit译码后信息。
对于基2加比选的全并行RE方式:路径存储部分需锁存交换2L-1个状态的长V路径信息,即需V×2L-1个逻辑单元和寄存器,译码时延为V个系统时钟。
对于全并行的传统TB方式,因每译出1 bit,至少回溯V bit,为实现连续译码,一次回溯应译出多个比特,设为x。则从译码输入到准备回溯需等待V+x个系统时钟,若每系统时钟只回溯y=1 bit,则一次译码输出需回溯V+x个系统时钟。采取多片轮读(一片写,2至多片读)的模式,在回溯期间又写入V+x个符号的路径信息。
流水线方式操作时,在(n+1)x系统时钟内至少完成n次回溯译码x bit。2片读时,2x时钟内需完成(V+x)符号的回溯,因而一般取x=V。
这样,2x时钟内读的2片RAM深度分别为2V,宽度2L-1个状态的1 bit路径信息,共计4V深度(按之前4V系统时钟内写入顺序标记为1a、1b,之后启动写2a、2b的深度为2V的2片RAM),写入2V深度之后启动回溯读出1b、1a;V深度后另一片读出2a、1b,这样回溯出1a、1b处的传输信息,同时写入2b、1a路径。
在这段时间内又写入2V深度的路径信息(1a,1b),与2片读的RAM中的前一片2V深度RAM读出信息(1b,1a)交叉。当路径存储RAM采用一读一写的双端口RAM实现时,2片RAM即可实现1片写,2片读的写入及回溯功能。
所以,总存储单元应为深度为4V个符号的宽度2L-1个状态路径信息,即4V×2L-1bit存储单元,实际深度取满足(M=2N>4V)的最小正整数N对应的M。
译码延时:从译码器开始接收到准备回溯需2V个时钟,回溯(V+x)即2V深度需2V个系统时钟,共计4V个系统时钟。
1.2 改进的部分寄存器交换回溯方式
从上述传统TB方式可以看出,为减小译码延时和存储单元,可采取一次并行读出多比特符号的路径信息。本文提出采用部分寄存器交换方法,累积多符号(2~6)的路径信息后,一次存储写入一个地址的存储单元,从而加快之后的读过程。
设部分RE的长度为y。采取1片存储单元1读1写方式,每次回溯译出x比特,则回溯延时为t=(V+x)/y;在此回溯期间又写入t比特路径信息,为保证路径信息存储单元不发生有用信息覆盖,要求t≤x,即x≥(V+x)/y,也即x≥V/(y-1)。一般x取满足条件的最小整数值。
译码延时为等待时间加回溯时间。对每段译码信息而言从开始接收到回溯前的等待时间为:V+x比特的译码信息接收时间V+x个系统时钟。译码延时共计V+x+t≈V+2x。
路径信息存储单元为(V+2x)/y深(实际深度取满足M=2N>(V+2x)/y的最小正整数N对应的M),y×2L-1宽,总比特数为(V+2x)×2L-1。
另外,回溯时要多消耗y个2L-1选一的逻辑资源,即y×2L-1的组合LUT;由于采用部分寄存器交换,需要2L-1个长为y的寄存器锁存当前路径信息。
2 其他优化措施
采用了文献[5]中提到的分支度量线性变换3 bit量化解调信号时,分支度量仍为3 bit的非负数,简化了之后的路径度量溢出处理。
分支度量一次计算多次查找——对于(2,1,n)码即4选一。
简单的累积路径度量溢出,对于(2,1,7)3 bit量化卷积码,路径度量的最大最小范围在3+log27位内。因所有路径度量及分支度量都是非负数,这样再补充一位最高位溢出位,确定了存储路径度量的寄存器位宽为3+log27+17。
由于采用全并行结构,一个时钟内必须完成一次ACS(Add-Compare-Select,加比选),因而ACS部分未采用文献[7]中流水线结构,ACS是制约全并行结构Viterbi译码器最高工作频率的因素之一。但采取了缓解分支度量选择的时延,两级计算锁存的分支度量算法,较一级分支度量锁存提高了约10 MHz的最高工作频率。
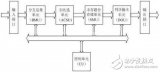
3 译码器设计
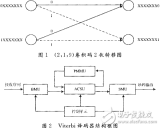
译码器的结构框图如图1所示。
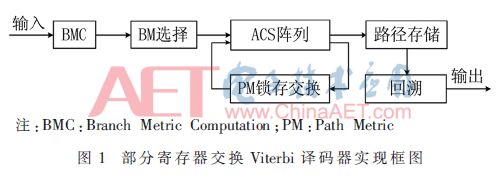
4 资源占用实验性能
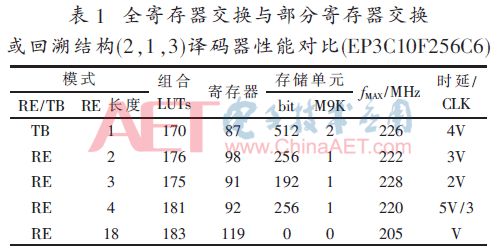
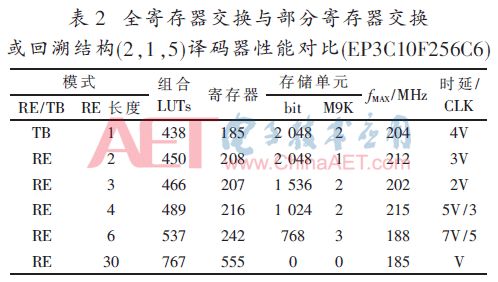
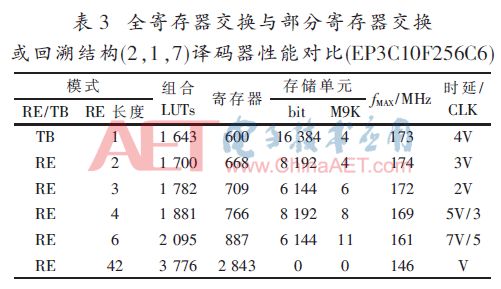
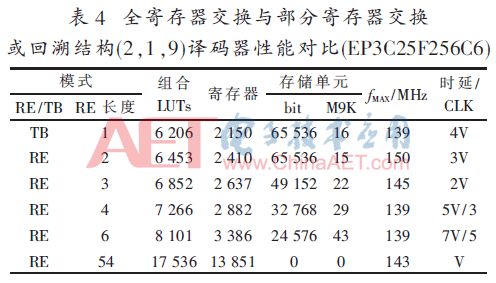
按照图1设计的基2全并行译码器在Quartus9.1下时序仿真正确后,综合适配结果如表1~表4所述,其中:V=6×L,量化比特数为3。
5 译码器其他性能
5.1 译码器译码性能
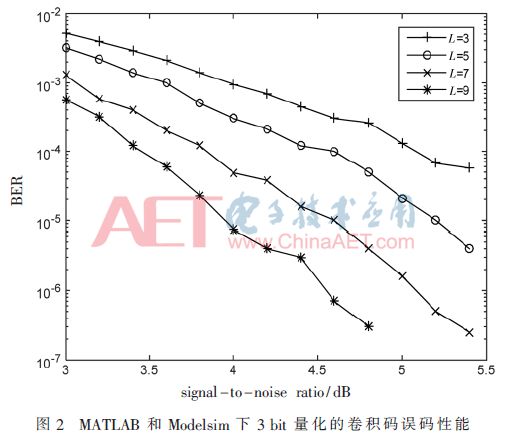
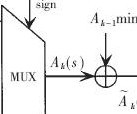
在MATLAB下3 bit量化定点仿真和Modelsim下3 bit量化前仿真:分别对(2,1,3)、(2,1,5)、(2,1,7)、(2,1,9)的50段(信噪比小于等于4.4 dB时)或100段(信噪比大于4.4 dB时)长度为40 000的已编码序列经信噪比(SNR=Eb/no)为3~5.4 dB(仅在MATLAB下,而在Modelsim下每种卷积码仅选择译码BER=10-3及10-4两种情况)的AGWN BPSK信道传输的接收信号进行模拟,误码性能如图2所示。后仿真[2,7]时对(2,1,3)、(2,1,5)、(2,1,7)、(2,1,9)4种卷积码分别选取了5.2 dB、4.8 dB、4.0 dB、3.4 dB下长度为40 000的有噪已编码接收序列进行误码性能测试,与图2完全一致。
5.2 吞吐量
当吞吐量定义为译码器输出信息速率时(而文献[5]中吞吐量定义为译码器输入速率,与量化比特无关),对于本文中的基2全并行码率R=1/2的Viterbi译码器,吞吐量为2fmax。即在CycloneIII上实现的(2,1,7)全并行译码器吞吐量在290~350 Mb/s之间。
在结构化ASIC器件如HardCopyIII上消耗逻辑资源与在CycloneIII上相当时(2,1,7)卷积码的最高工作频率340 Hz,吞吐量680 Mb/s。
若采用定制ASIC实现,吞吐量应可满足引言中提到的目前各种使用Viterbi译码的标准(500 Mb/s)的需求。
5.3 与其他文献的并行译码器性能对比
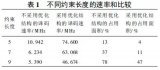
与其他文献的(2,1,3)全并行译码器性能对比(EP3-C10F256C6)如表5所示。
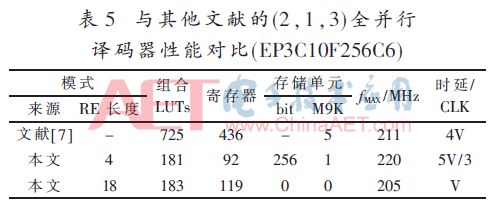
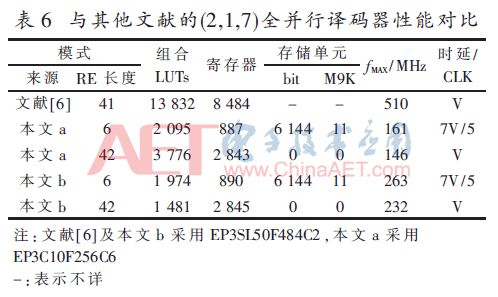
由表中数据可以看出,本文设计的(2,1,3)卷积码全并行译码器明显优于Altera公司提供的IP核,逻辑资源占用量仅其25%,译码时延也仅其25%。与其他文献的(2,1,7)全并行译码器性能对比如表6所示。
6 结论
本文采用部分寄存器交换的译码器在交换长度为3时与简单回溯模式相比消耗逻辑资源几乎相近,存储单元减少25%~66%的条件下实现译码延时减半的效果。
对于短约束长度的卷积码,如(2,1,3)、(2,1,5)采用全寄存器交换资源消耗不会增加太多,但译码延时比交换长度为3时又减少50%,更具实用价值。
而对于长约束长度的卷积码,如(2,1,7)、(2,1,9)采用全寄存器交换资源消耗增加太多,选用寄存器交换长度为4或6时较合适,此时的时延与完全寄存器交换相近,但消耗的逻辑资源与简单回溯模式相当,存储器单元比简单回溯小很多(小50%或62.5%),虽然在本文中的FPGA下实现时消耗的存储块数更多,但那是由于CycloneIII的每块存储块比较大(深度大而宽度受限),若采用最小深度为16的小存储块时(比如定制ASIC技术)其优势将明显显现出来。
-
寄存器
+关注
关注
30文章
5028浏览量
117715 -
译码器
+关注
关注
4文章
310浏览量
49906 -
Viterbi
+关注
关注
0文章
13浏览量
9770
原文标题:【学术论文】高速率低延时Viterbi译码器的设计与实现
文章出处:【微信号:ChinaAET,微信公众号:电子技术应用ChinaAET】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是硬判决和软判决Viterbi 译码算法 ?
应用于LTE-OFDM系统的Viterbi译码在FPGA中的实现
基于IP核的Viterbi译码器实现
基带芯片中Viterbi译码器的研究与实现
从FPGA实现的角度对大约束度Viterbi译码器中路径存储
短帧Turbo译码器的FPGA实现
Viterbi译码器的低功耗设计
Viterbi译码器回溯算法实现

基于ASIC的高速Viterbi译码器设计
基于FPGA的指针反馈式低功耗Viterbi译码器的性能分析和设计

关于基于Xilinx FPGA 的高速Viterbi回溯译码器的性能分析和应用介绍
通过采用FPGA器件设计一个Viterbi译码器
浅谈FPGA的指针反馈式低功耗Viterbi译码器设计






 工商网监
工商网监
评论