 微操作μ-op与宏操作macro-op
微操作μ-op与宏操作macro-op
一微操作μ-op与宏操作macro-op
英特尔SunnyCove内核前端
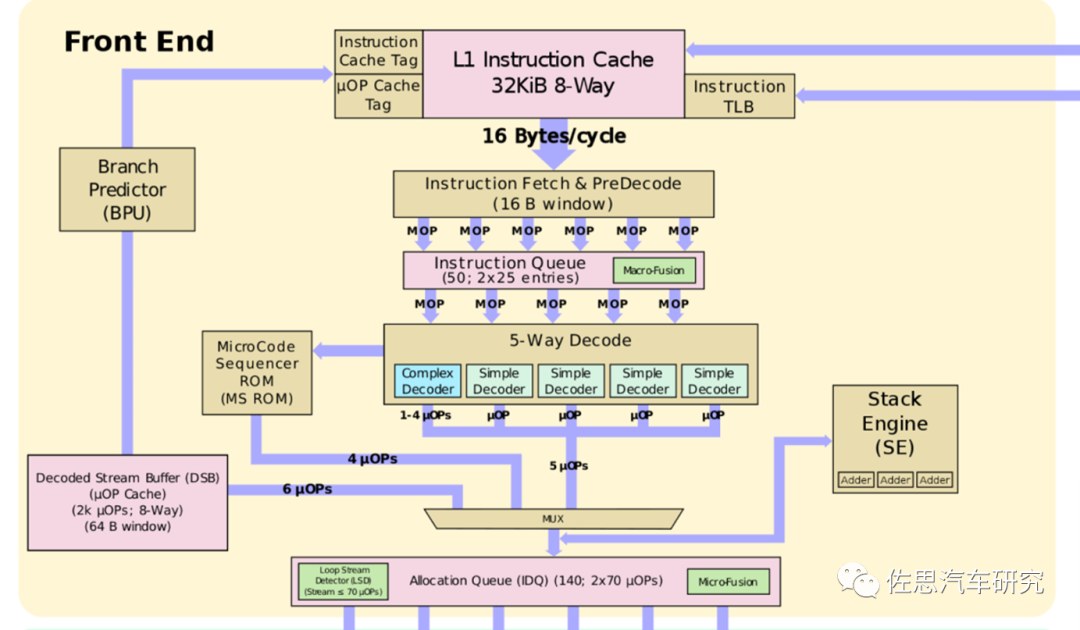
图片来源:英特尔
上图为英特尔Sunny Cove内核前端。因为CISC的指令长度不确定,且比较复杂,英特尔将这些指令切割成固定长度,这个微指令从Pentium Pro开始在IA架构出现。处理器接受的是x86指令(CISC指令,复杂指令集),而在执行引擎内部执行的却不是x86指令,而是一条一条的类RISC指令,Intel 称之为Micro Operation,即micro-op或μ-op,一般用比较方便的写法来替代掉希腊字母: u-op或者uop。相对地,融合了多条指令的操作就称之为Macro Operation或macro-op,即宏操作。 英特尔逐渐改进微指令,后来加入微指令缓存即uOP cache,也有的地方叫L0级缓存,表面看来,uOP cache被定位为一个2级指令cache单元,是1级指令cache单元的子集。其独特之处在于它所存储的是译码之后的指令(uOPs)。早期Micro-op cache是由32组8条cacheline组成。每条cacheline最多保留6条uOps,共计1536条uOps,Sunny Cove是48组,也就是2304条uOps。这个Cache是在两个线程之间共享的,并保留了指向micro sequencer ROM的指针。它也是虚拟地址寻址,是L1指令cache的严格的子集。每条cacheline还包括其包含的uop数量及其长度。 内核一直都在处理来自指令流(Instruction Stream)的连续的32byte信息。同样地,uOPcache也是基于32byte窗口。因此uOP cache可以基于LRU(Least Recently Used)策略存储或者放弃整个窗口。英特尔将传统的流水线称为“legacy decode pipeline”。在首次迭代时,所有的指令都是经过“legacy decode pipeline”。一旦整个指令流窗口被译码并且发送到分配队列,窗口的拷贝就被发送到uOP cache。这是与所有其他操作同时发生的,因此这个功能没有增加额外的流水线阶段。后续的迭代,被缓存的已经解码好的指令流就可以直接被发送到分配队列了,省却了取指、预译码和译码的阶段,节省功耗,增加了吞吐量。这也是一个更短的流水线,延迟也减小了。 uOP cache有着高于80%的命中率。在取指期间,分支预测器将会读取uOPscache的tags。如果命中了cache,会可以每周期发送至多4条uops(可能包含了fused macro-ops)到Instruction Decode Queue(IDQ),绕开了其他所有本该进行的预译码和译码。
ARMCortex-A77微架构
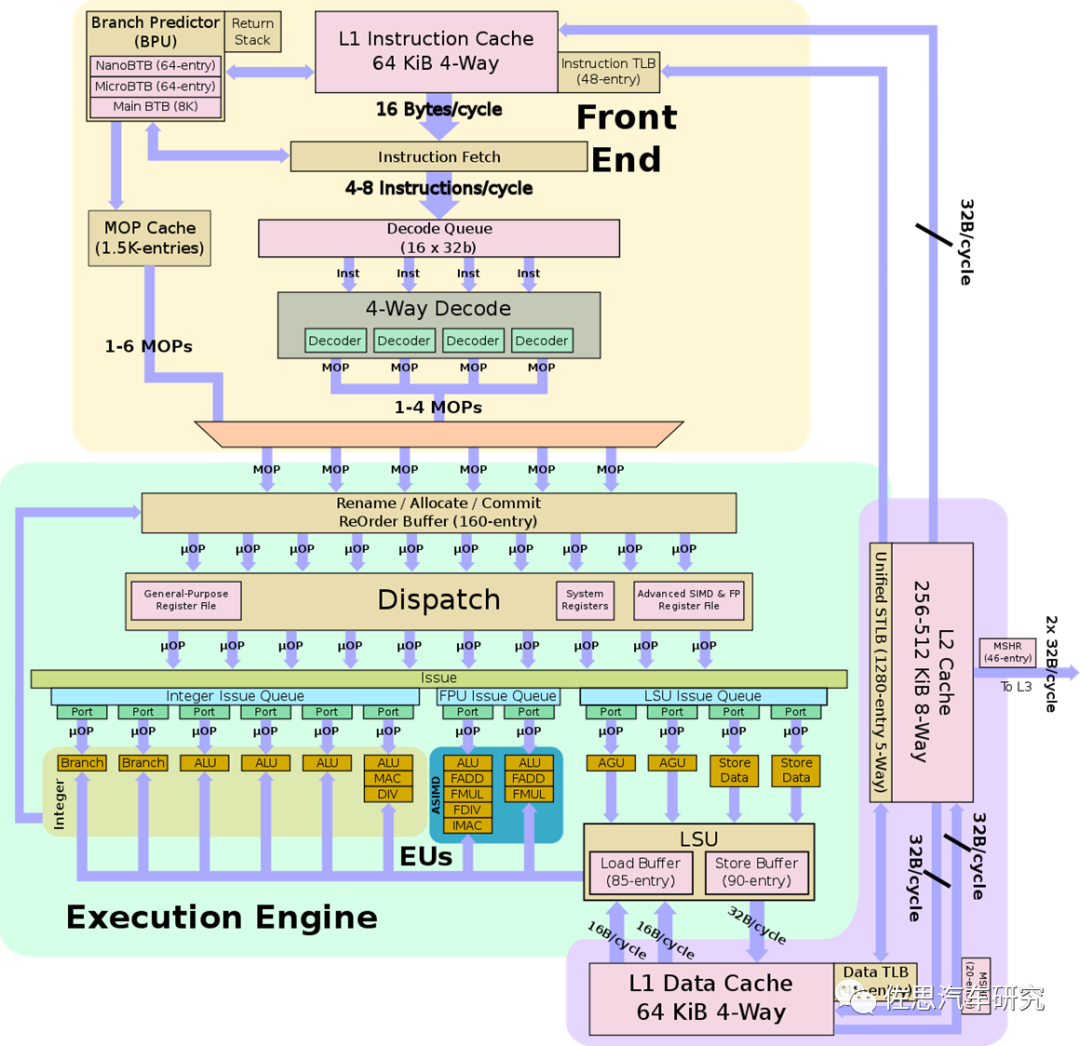
图片来源:ARM
上图为ARM Cortex-A77的架构图,自A77开始,ARM也添加了经解码后的指令缓存,与英特尔的uOP缓存高度类似,只不过ARM反其道用之,英特尔是把CISC指令切割成微指令,ARM是融合,把定长定格式的RISC指令融合成宏操作MOP(Macro Operation),然后再分割成uOP。这样做可能是RISC指令分得太散,有些是可以融合的,这样效率更高。再有就是解码器通常比后端吞吐量更高,有足够的MOP缓存可以让后端工作更饱和,利用率更高。 A78也是如此,每周期4个指令,6个MOPs,X1则不同,每周期5个指令,8个MOPs。
A78译码到分布

图片来源:互联网
二
发射与执行
ARM和AMD的执行单元一般将整数计算(ALU)与浮点计算(FPU)分开,英特尔则是合二为一,执行端关键的参数是发射宽度(Issue Width),目前最宽的是ARM的V1,多达15位,宽度越宽,ALU和FPU数量可以越多。通常ALU是4个,整数运算单元4个就够。V1有4个ALU,4个针对浮点的NEON,其中包含两个SVE。3个Load加载,2个写入Store。还有两个分支针对特定计算类型。

图片来源:互联网
所有计算机程序的本质,是指令的执行过程,从根本上说,也就是处理器的寄存器(Register)到内存之间的数据交互过程。这个交互,无非两个步骤:读内存,也就是加载操作(load), 从内存读到寄存器,写内存,就是存储操作(store),从寄存器写入到内存,LSU就是Load Store Unit。 LSU部件是指令流水线的一个执行部件,其上接收来自内核的LSU发射序列,其下连接着存储器子系统即数据缓存。其主要功能是将来自CPU的存储器请求发送到存储器子系统,并处理其下存储器子系统的应答数据和消息。在许多微架构中,引入了AGU(寻址生成器)计算有效地址以加速存储器指令的执行,使用ALU(计算单元,通常是标量计算单元)的部分流水处理LSU中的数据。而从逻辑功能上看,AGU和ALU所做的工作依然属于LSU。
三
定点与浮点
所谓定点格式,即约定机器中所有数据的小数点位置是固定不变的。通常将定点数据表示成纯小数或纯整数,为了将数表示成纯小数,通常把小数点固定在数值部分的最高位之前;而为了将数表示成纯整数,则把小数点固定在数值部分的最后面。
比如十进制的3.75,那么你可以用011+0.11,但是这种加法首先要对齐位宽,对齐目的就是让大家的单位一致。你可以把011扩展为011.00,把0.11扩展为000.11,这样一相加就得到011.11,就是十进制的3.75了,存在电脑的时候,电脑是没有小数点的,只会存为01111。如果是定点格式,这个小数点的位置就固定了,无法变动,由于计算的时候必须对齐位宽,这使得电脑能处理的数据范围受到限制,不能太大,也不能太小。假设以一个字节表示小数,小数点固定在5.3的位置,高5位表示整数,低3位表示小数:11001_001 —— 11001.001,转换一下:整数部分11001= 25, 小数部分001 = 1(分子部分) 分母是1000(8),所以小数部分1/8(二级制只有0和1)。最终的小数表示是 25+ 1/8,即存在 0/8, 1/8,2/8, …. 7/8共八个档,表示精度为1/8,所以定点小数存在数值范围和数值精度的问题!数值范围与精度是一对矛盾,一个变量要想能够表示比较大的数值范围,必须以牺牲精度为代价;而想精度提高,则数的表示范围就相应地减小。在实际的定点算法中,为了达到最佳的性能,必须充分考虑到这一点,即权衡动态范围和精度。
如果是逻辑运算或简单的整数运算还可以,如果要显示比较大的变量,小数点的位置必须可以自由移动,这就是浮点。

图片来源:互联网
比如123.45用十进制科学计数法可以表示为1.2345x102,其中1.2345为尾数,10为基数,2为指数。浮点数利用指数达到了浮动小数点的效果,从而可以灵活地表达更大范围的实数。IEEE754指定了:两种基本的浮点格式:单精度和双精度。其中单精度格式具有24位有效数字(即尾数)精度,总共占用32位;双精度格式具有53位有效数字(即尾数)精度,总共占用64位。
两种扩展浮点格式:单精度扩展和双精度扩展。此标准并未规定这些格式的精确精度和大小,但指定了最小精度和大小,例如IEEE双精度扩展格式必须至少具有64位有效数字精度,并总共占用至少79位。
浮点运算和定点运算(整数运算)不同,它通常是6个步骤:1. 异常检测:主要检测NAN(非数) 2. 对阶,尾数右移:不同阶码尾数不能直接相加减,所以需要对阶,比如1.1 * 2 E 1 + 1.1 * 2 E 2 尾数就不能运算,对阶,尾数右移,最终阶码一致。3 . 尾数求和求差,将对阶后的尾数按定点加减运算规则进行运算。4. 规格化:把非规格的小数转换为规格化的小数。5. 在对阶和右移过程中,可能会将尾数的低位丢失,引起误差,影响精度,为此可用舍入法来提高尾数的精度。IEEE754标准列出了四种可选的舍入处理方法:向上舍入,向下舍入,向最近舍入,直接截去。6. 溢出检查,与定点数运算不同的是,浮点数的溢出是以其运算结果的阶码的值是否产生溢出来判断的。若阶码的值超过了阶码所能表示的最大正数,则为上溢,进一步,若此时浮点数为正数,则为正上溢。若浮点数为负数,则为负上溢。进一步,若此时浮点数为正数,则为正下溢,若浮点数为负数,则为负下溢。正下溢和负下溢都作为机器零处理,即将尾数各位强制为零。
四
具体CPU微架构
特斯拉使用AMD的CPU,因此特别对AMD的微架构做以说明。

图片来源:互联网
这是Zen 2代微架构的前端,ITLB就是 Instruction Translation Lookaside Buffer,另一种说法是指令转换后备缓冲区。AMD的L0/L1/L2缓存与传统的缓存定义不同,它解签了软件意义上的缓存而非硬件,L1里有BTB缓存,Hash路径缓存表,ITLB缓存好几种。Zen3代则将L1的BTB缓存由512条扩展到1024条,提高分支预测准确度。虽然L1缓存异常复杂,但总容量还是32K,分8路。Return Stack是方法返回栈,可能是分支预测异常的返回地址。
分支预测器经过Micro tags最终变为8个宏操作Marco Ops,进入宏操作缓存,缓存量为4K条,指令缓存排成序列,进入译码器,译码器宽度是4位,8个宏操作和4个译码后的指令进入OC/IC,分解为微操作序列,再分别进入堆叠引擎和存储独立侦测系统还有微码序列ROM,再进入分发站。
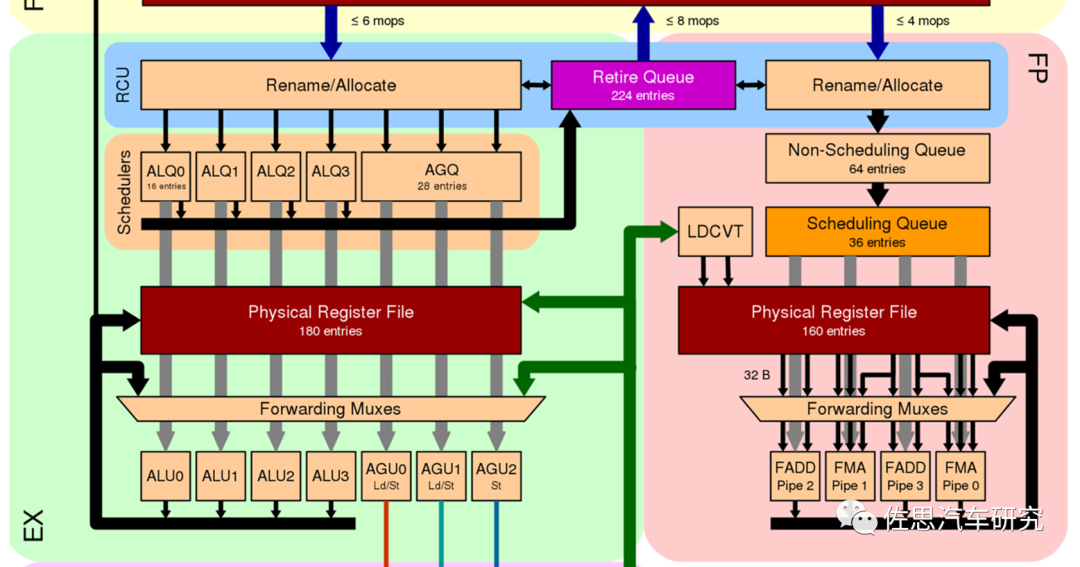
图片来源:互联网
Zen2代微架构的执行端,执行端分整数和浮点两大执行器,绿色为整数,粉色为浮点。整数部分指令经过重命名和定位后进入序列器,完成后提交或者说退出Retire再进入物理寄存器文件,再前向混合,进入ALU4个算数计算器,3个地址生成器。Zen3代的寄存器条目增加到212个。浮点方面寄存器略少,FADD和FMA分别是加法和乘法管线,管线有4条,Zen3代增加到6条,不过计算管线还是4条。
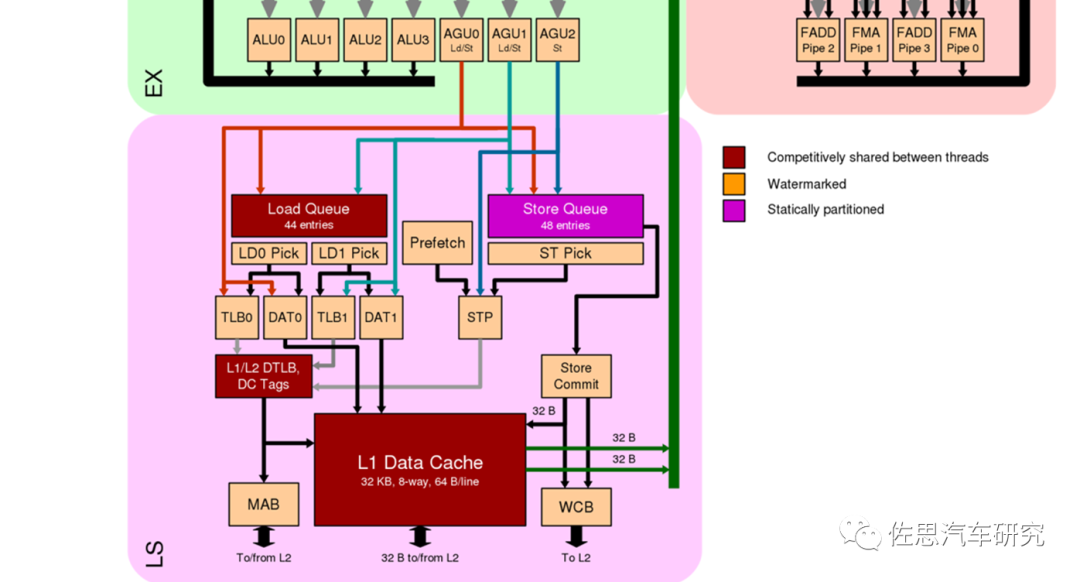
图片来源:互联网
最后是加载和写入部分。
Zen2 Die Shot

图片来源:互联网
Zen 2代一个核的透视图,可以看到缓存占芯片的面积最大,其次是浮点运算用的SIMD,然后是分支预测,加载与写入,译码,计算用的ALU所占面积很小。
审核编辑 :李倩
-
芯片
+关注
关注
447文章
47804浏览量
409173 -
cpu
+关注
关注
68文章
10446浏览量
206574
原文标题:深入了解汽车系统级芯片SoC连载之六:CPU微架构
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
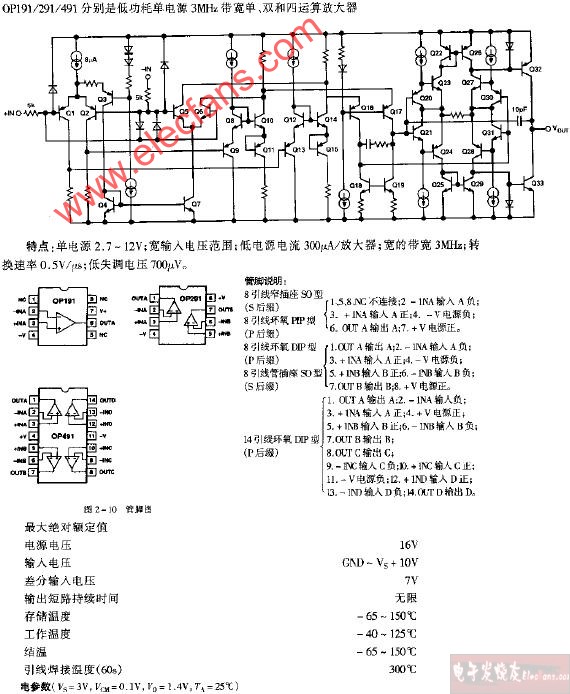
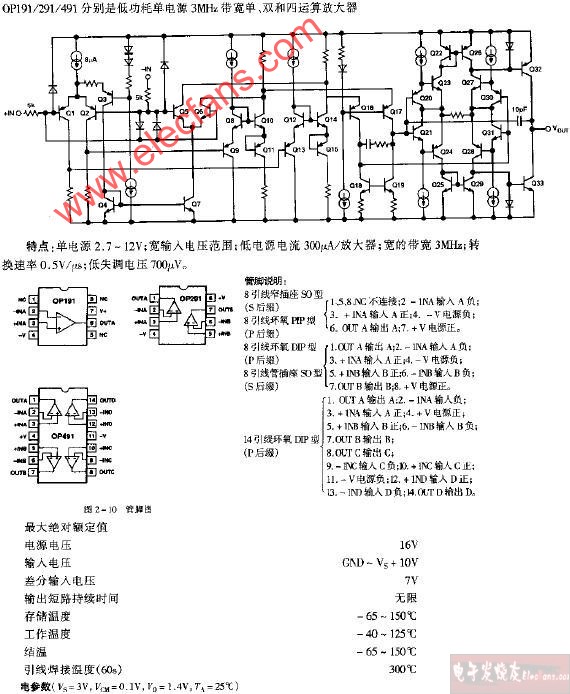



OP0401文本显示器操作指南
OP系列可编程操作显示器
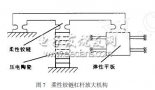
基于压电陶瓷驱动的微操作手研究
西门子OP27、OP37中文使用手册
AD7245/AD7248:LC-OP-2-OP-OP-MOS 12位DAPORT






 工商网监
工商网监
评论