 关于一项改进Transformer的工作
关于一项改进Transformer的工作
NAACL2021中,复旦大学大学数据智能与社会计算实验室(Fudan DISC)和微软亚洲研究院合作进行了一项改进Transformer的工作,论文的题目为:Mask Attention Networks: Rethinking and Strengthen Transformer,被收录为长文。
文章摘要
Transformer的每一层都由两部分构成,分别是自注意力网络(SAN)和前馈神经网络(FFN)。当前的大部分研究会拆开这两份部分来分别进行增强。在我们的研究当中,我们发现SAN和FFN本质上都属于一类更广泛的神经网络结构,遮罩注意力网络(MANs),并且其中的遮罩矩阵都是静态的。我们认为这样的静态遮罩方式限制了模型对于局部信息的建模的。因此,我们提出了一类新的网络,动态遮罩注意力网络(DMAN),通过自身的学习来调整对于局部信息的建模。为了更好地融合各个子网络(SAN,FFN,DMAN)的优势,我们提出了一种层叠机制来将三者融合起来。我们在机器翻译和文本摘要任务上验证了我们的模型的有效性。
研究背景
目前大家会从SAN或者FFN来对Transformer进行改进,但是这样的方案忽略了SAN和FFN的内在联系。
在我们的工作当中,我们使用Mask Attention Network作为分析框架来重新审视SAN和FFN。Mask Attention Networks使用一个遮罩矩阵来和键值对的权重矩阵进行对应位置的相乘操作来确定最终的注意力权重。在下图中,我们分别展示了SAN和FFN的遮罩矩阵。由于对于关系建模没有任何的限制,SAN更擅长长距离建模来从而可以更好地捕捉全局语意,而FFN因为遮罩矩阵的限制,无法获取到其他的token的信息,因而更关注自身的信息。
尽管SAN和FFN取得了相当好的效果,但是最近的一些研究结果表明,Transformer在捕捉局部信息的能力上有所欠缺。我们认为这种欠缺是因为是因为注意力矩阵的计算当中都是有静态遮罩矩阵的参与所导致的。我们发现两个不相关的token之间的权重可能因为中间词的关系而错误地产生了较大的注意力权重。例如“a black dog jumps to catch the frisbee”, 尽管“catch”和“black”关系不大,但是因为二者都共同的邻居“dog”的关系很大,进而产生了错误了联系,使得“catch”忽略了自己真正的邻居。
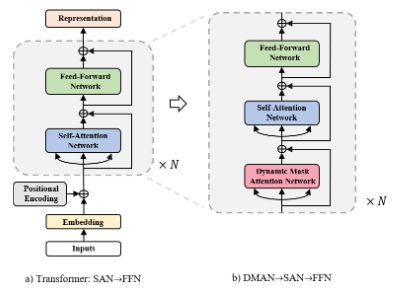
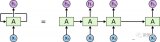
为了强化Transformer在局部建模的能力,我们提出了动态遮罩注意力网络(DMAN)。在DMAN当中, 在特定距离内的单词相比于一般的注意力机制会得到更多的注意力权重,进而得到更多的关注。另外,为了更好地融合SAN,FFN和DMAN三者的能力,我们提出使用DMAN-》SAN-》FFN这样的方式来搭建网络结构。
方法描述
回顾Transformer
SAN的注意力机制使用下面的公式来将键值对映射到新的输出。
其中是查询向量组成的有序矩阵,是键值对的组合,是的特征维度。
为了进一步增强transformer捕捉不同文本特征的的能力,对于一个文本特征的输入序列, SAN会使用多头注意力机制。
在FFN当中,每一个
的计算都是独立于其他的输入的。具体来说,它由两个全连接层组成。
定义一类新网络: Mask Attention Networks
我们在SAN的注意力函数的基础上定义带遮罩的注意力函数。
其中M是一个遮罩矩阵,它既可以是静态的,也可以是动态的。
在这个新的遮罩矩阵的基础上,我们定义一类新网络: Mask Attention Networks(MANs)
其中F是激活函数,M^i是第i个注意力上的遮罩矩阵。
接下来我们来说明SAN和FFN都是MANs当中的特例。
从MANs的视角来看,对于SAN,我们令
这个时候MANs可以写成下面的形式。这个结果告诉我们SAN是MANs当中固定遮罩矩阵为全1的特例
对于FFN,我们令
那么得到SAN是MANs当中固定遮罩矩阵为单位阵的特例。
SAN和FFN在局部建模上的问题
直观上来说,因为FFN的遮罩矩阵是一个单位阵,所以FFN只能获取自身的信息而无法获知邻居的信息。对于SAN,每一个token都可以获取到句子其它的所有token的信息。我们发现不在邻域当中的单词也有可能得到一个相当大的注意力得分。因此,SAN可能在语义建模的过程当中引入噪声,进而忽视了局部当中的有效信号。
动态遮罩注意力网络
显然地我们可以通过静态的遮罩矩阵来使模型只考虑特定邻域内的单词,从而达到更好的局部建模的效果。但是这样的方式欠缺灵活性,考虑到邻域的大小应该随着query token来变化,所以我们构建了下面的策略来动态地调节邻域的大小。
其中是当前的层数,是当前的注意力head, 和分别是两个和的位置。都是可学习的变量。
组合Mask Attention Networks当中的各类网络结构
我们采用下图的方式来组合这三种网络结构。
实验
我们的实验主要分为两个部分,机器翻译和文本摘要。
机器翻译
我们在IWSLT14 De-En和WMT14 En-De上分别对我们的模型进行了验证。相比于Transformer,我们的模型在base和big的参数大小设定下,分别取得了1.8和2.0的BLEU的提升。
文本摘要
在文本摘要的任务上,我们分别在CNN/Daily Mail和Gigaword这两个数据集上分别进行了验证。相比于Transformer,我们的模型在R-avg上分别有1.5和0.7的效果提升。
对比不同的子网络堆叠方式

我们对比了一些不同的子网络堆叠方式的结果。从这张表中我们可以发现:
C#5,C#4,C#3》C#1,C#2,这说明DMAN的参与可以提高模型的效果。
C#5,C#4》C#3,C#2,说明DMAN和SAN有各自的优点,它们分别更擅长全局建模和局部建模,所以可以更好地合作来增强彼此。
C#5》C#4,说明先建模局部再全局比相反的顺序要更好一些。
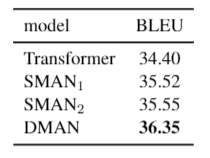
我们比较了两组不同的静态遮罩策略。
SMAN1:遮盖距离超过b的所有单词,,为句子长度。
SMAN2:b=4。
从结果来看,我们发现DMAN的效果远远好于上述两种静态遮罩方法,这说明给不同的单词确实在邻域的建模上确实存在差异。
结论
在这篇论文当中,我们介绍了遮罩注意力网络(MANs)来重新审视SAN和FFN,并指出它们是MANs的两种特殊情况。我们进而分析了两种网络在局部建模上的不足,并提出使用动态遮罩的方法来更好地进行局部建模。考虑到SAN,FFN和DMAN不同的优点,我们提出了一种DMAN-》SAN-》FFN的方式来进行建模。我们提出的模型在机器翻译和文本摘要上都比transformer取得了更好的效果。
原文标题:遮罩注意力网络:对Transformer的再思考与改进
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
网络
+关注
关注
14文章
7250浏览量
87436 -
Transforme
+关注
关注
0文章
12浏览量
8759
原文标题:遮罩注意力网络:对Transformer的再思考与改进
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
更深层的理解视觉Transformer, 对视觉Transformer的剖析
降低Transformer复杂度O(N^2)的方法汇总

关于深度学习模型Transformer模型的具体实现方案
为什么transformer性能这么好?Transformer的上下文学习能力是哪来的?
BEV人工智能transformer
基于Transformer的目标检测算法

transformer模型详解:Transformer 模型的压缩方法
基于 Transformer 的分割与检测方法

2D Transformer 可以帮助3D表示学习吗?
基于Transformer的大型语言模型(LLM)的内部机制

Transformer在下一个token预测任务上的SGD训练动态

基于transformer的编码器-解码器模型的工作原理
Transformer结构及其应用详解





 工商网监
工商网监
评论