 Python爬虫 你真的会写爬虫吗?
Python爬虫 你真的会写爬虫吗?
咱们直接进入今天的主题---你真的会写爬虫吗?为啥标题是这样,因为我们日常写小爬虫都是一个py文件加上几个请求,但是如果你去写一个正式的项目时,你必须考虑到很多种情况,所以我们需要把这些功能全部模块化,这样也使我们的爬虫更加的健全。
2基础爬虫的架构以及运行流程
首先,给大家来讲讲基础爬虫的架构到底是啥样子的?JAP君给大家画了张粗糙的图:
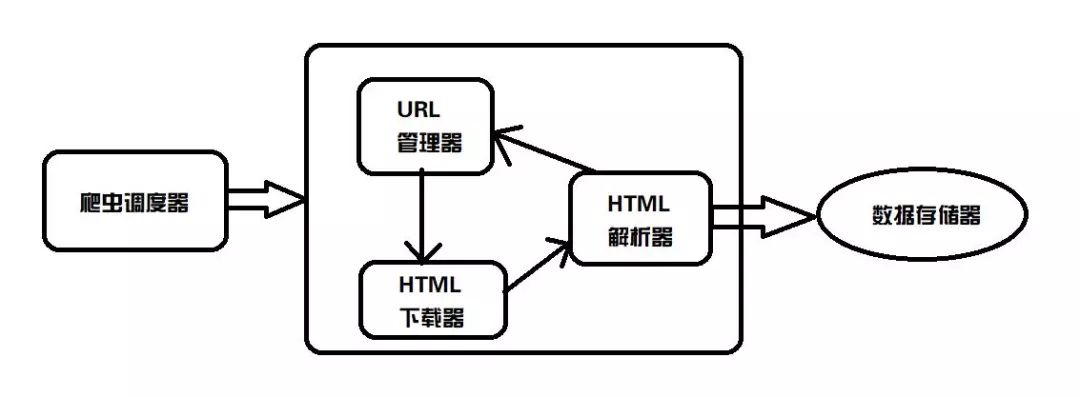
从图上可以看到,整个基础爬虫架构分为5大类:爬虫调度器、URL管理器、HTML下载器、HTML解析器、数据存储器。
下面给大家依次来介绍一下这5个大类的功能:
爬虫调度器,主要是配合调用其他四个模块,所谓调度就是取调用其他的模板
URL管理器,就是负责管理URL链接的,URL链接分为已经爬取的和未爬取的,这就需要URL管理器来管理它们,同时它也为获取新URL链接提供接口。
HTML下载器,就是将要爬取的页面的HTML下载下来
HTML解析器,就是将要爬取的数据从HTML源码中获取出来,同时也将新的URL链接发送给URL管理器以及将处理后的数据发送给数据存储器。
数据存储器,就是将HTML下载器发送过来的数据存储到本地
3实战爬取菜鸟笔记信息
差不多就介绍这么些东西,相信大家对整体的架构有了初步的认识,下面我简单找了个网站给大家演示一遍用爬虫架构来爬取信息:
(目标站点)
我们来获取上面列表中的信息,这里我就省略了分析网站的一步,如果大家不会分析,可以去看我之前写的爬虫项目。
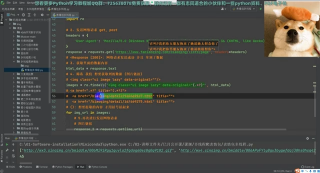
首先,我们来写一下URL管理器(URLManage.py)
class URLManager(object): def __init__(self): self.new_urls = set() self.old_urls = set() def has_new_url(self): # 判断是否有未爬取的url return self.new_url_size()!=0 def get_new_url(self): # 获取一个未爬取的链接 new_url = self.new_urls.pop() # 提取之后,将其添加到已爬取的链接中 self.old_urls.add(new_url) return new_url def add_new_url(self, url): # 将新链接添加到未爬取的集合中(单个链接) if url is None: return if url not in self.new_urls and url not in self.old_urls: self.new_urls.add(url) def add_new_urls(self,urls): # 将新链接添加到未爬取的集合中(集合) if urls is None or len(urls)==0: return for url in urls: self.add_new_url(url) def new_url_size(self): # 获取未爬取的url大小 return len(self.new_urls) def old_url_size(self): # 获取已爬取的url大小 return len(self.old_urls)
在这里主要就是两个集合,一个是已爬取URL的集合,另一个是未爬取URL的集合。这里我使用的是set类型,因为set自带去重的功能。
接下来,HTML下载器(HTMLDownload.py)
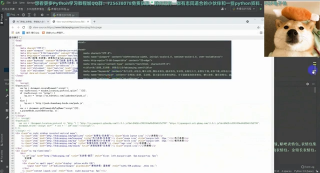
importrequestsclassHTMLDownload(object): def download(self, url): if url is None: return s = requests.Session() s.headers['User-Agent'] ='Mozilla / 5.0(Windows NT 10.0;WOW64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 63.0.3239.132Safari / 537.36' res = s.get(url) # 判断是否正常获取 if res.status_code == 200: res.encoding='utf-8' res = res.text return resreturnNone
可以看到这里我们只是简单的获取了,url中的html源码
接着看HTML解析器(HTMLParser.py)
import refrombs4importBeautifulSoupclass HTMLParser(object): def parser(self, page_url, html_cont): ''' 用于解析网页内容,抽取URL和数据 :param page_url: 下载页面的URL :param html_cont: 下载的网页内容 :return: 返回URL和数据 ''' if page_url is None or html_cont is None: return soup = BeautifulSoup(html_cont, 'html.parser') new_urls = self._get_new_urls(page_url, soup) new_data = self._get_new_data(page_url, soup) return new_urls, new_data def _get_new_urls(self,page_url,soup): ''' 抽取新的URL集合 :param page_url:下载页面的URL :param soup: soup数据 :return: 返回新的URL集合 ''' new_urls = set() for link in range(1,100): # 添加新的urlnew_url="http://www.runoob.com/w3cnote/page/"+str(link) new_urls.add(new_url) print(new_urls) return new_urls def _get_new_data(self,page_url,soup): ''' 抽取有效数据 :param page_url:下载页面的url :param soup: :return: 返回有效数据 ''' data={} data['url'] = page_url title = soup.find('div', class_='post-intro').find('h2') print(title) data['title'] = title.get_text() summary = soup.find('div', class_='post-intro').find('p') data['summary'] = summary.get_text()returndata
在这里,我们将HTML下载器的源码进行了分析和解析,从而得到了我们想要拿到的数据,如果BeautifulSoup不懂的可以去看一下我之前写的文章。
继续看,数据存储器(DataOutput.py)
importcodecsclass DataOutput(object): def __init__(self): self.datas = [] def store_data(self,data): if data is None: return self.datas.append(data) def output_html(self): fout = codecs.open('baike.html', 'a', encoding='utf-8') fout.write("") fout.write("
") fout.write("") fout.write("| %s | "%data['url']) fout.write("《%s》 | " % data['title']) fout.write("[%s] | " % data['summary']) fout.write("
大家可能发现我这里是将数据存储到一个html的文件当中,在这里你当然也可以存在Mysql或者csv等文件当中,这个看自己的选择,我这里只是为了演示所以就放在了html当中。
最后一个,爬虫调度器(SpiderMan.py)
from base.DataOutput import DataOutputfrom base.HTMLParser import HTMLParserfrom base.HTMLDownload import HTMLDownloadfrom base.URLManager import URLManagerclass SpiderMan(object): def __init__(self): self.manager = URLManager() self.downloader = HTMLDownload() self.parser = HTMLParser() self.output = DataOutput() def crawl(self, root_url): # 添加入口URL self.manager.add_new_url(root_url) # 判断url管理器中是否有新的url,同时判断抓取多少个url while(self.manager.has_new_url() and self.manager.old_url_size()<100): try: # 从URL管理器获取新的URL new_url = self.manager.get_new_url() print(new_url) # HTML下载器下载网页 html = self.downloader.download(new_url) # HTML解析器抽取网页数据 new_urls, data = self.parser.parser(new_url, html) print(new_urls) # 将抽取的url添加到URL管理器中 self.manager.add_new_urls(new_urls) # 数据存储器存储文件 self.output.store_data(data) print("已经抓取%s个链接" % self.manager.old_url_size()) except Exception as e: print("failed") print(e) # 数据存储器将文件输出成指定的格式 self.output.output_html()if __name__ == '__main__': spider_man = SpiderMan() spider_man.crawl("http://www.runoob.com/w3cnote/page/1")
相信这里大家都能看懂,我就是将前面我们写的四个模板在这里把它们调用了一下,我们运行后的结果:
4总结
我们这里简单的讲解了一下,爬虫架构的五个模板,无论是大型爬虫项目还是小型的爬虫项目都离不开这五个模板,希望大家能够照着这些代码写一遍,这样有利于大家的理解,大家以后写爬虫项目也要按照这种架构去写,这样你的爬虫看起来就会更加的规范、健全。
-
URL
+关注
关注
0文章
134浏览量
14826 -
python
+关注
关注
51文章
4675浏览量
83466 -
爬虫
+关注
关注
0文章
77浏览量
6514
原文标题:Python爬虫|你真的会写爬虫吗?
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
全球新闻网封锁OpenAI和谷歌AI爬虫
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
Python网络爬虫Selenium的简单使用
如何看待Python爬虫的合法性?
Python 一个超快的公共情报搜集爬虫
crawlerdetect:Python 三行代码检测爬虫
feapder:一款功能强大的爬虫框架
网络爬虫 Python和数据分析





 工商网监
工商网监
评论