 标记训练集中的数据样本是开发机器学习应用的最大瓶颈之一
标记训练集中的数据样本是开发机器学习应用的最大瓶颈之一
数据集就是机器学习行业的石油,强大的模型需要含有大量样本的数据集作为基础。而标记训练集中的数据样本是开发机器学习应用的最大瓶颈之一。
最近,谷歌与斯坦福大学、布朗大学一起,研究如何快速标记大型数据集,将整个组织的资源用作分类任务的弱监督资源,使机器学习的开发时间和成本降低一个数量级。
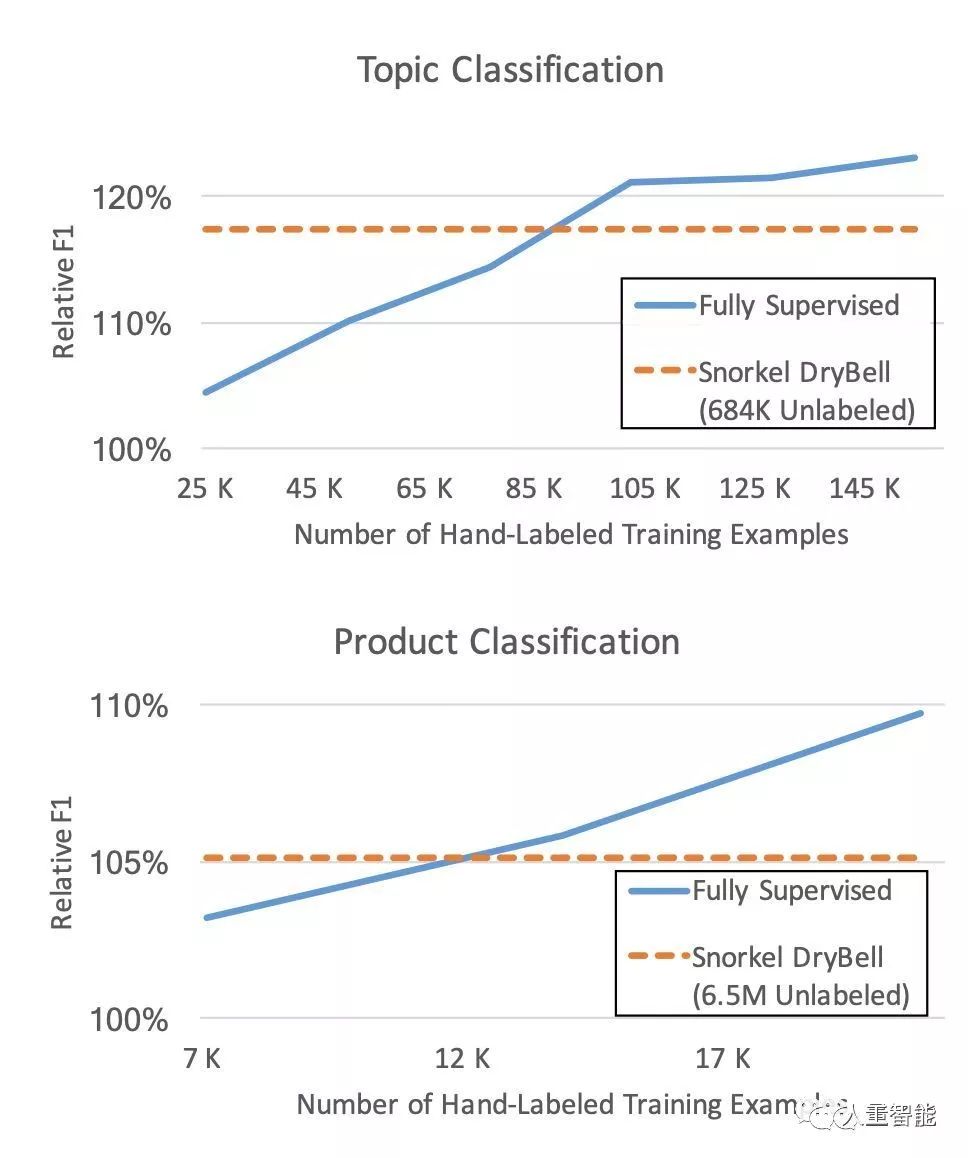
谷歌在论文中表示,这种方法能让工程师能够在不到30分钟的时间内对数百万个样本执行弱监督策略。
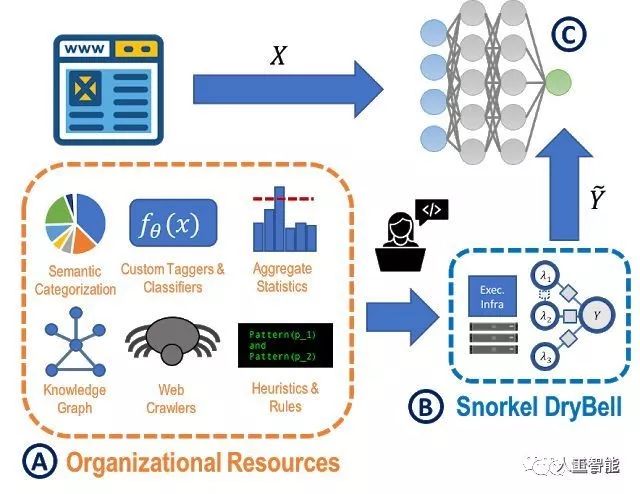
他们使用一种Snorkel Drybell系统,让开源Snorkel框架适应各种组织知识资源,生成Web规模机器学习模型的训练数据。
Snorkel是由斯坦福大学在2017年开发的系统,它可以在弱监督条件下快速创建训练数据集,该项目已经在GitHub上开源。而Snorkel Drybell的目标是在工业规模上部署弱监督学习。
而且用这种方法开发的分类器质量与手工标记样本进行训练的分类器效果相当,把弱监督分类器的平均性能提高了52%。
什么是Snorkel
Snorkel是斯坦福大学在2016年为许多弱监督学习开发的一个通用框架,由这种方法生成的标签可用于训练任意模型。

已经有人将Snorkel用于处理图像数据、自然语言监督、处理半结构化数据、自动生成训练集等具体用途。
原理
与手工标注训练数据不同,Snorkel DryBell支持编写标记函数,以编程方式标记训练数据。
过去的方法中,标记函数只是以编程方式标记数据的脚本,它产生的标签是带有噪声的。
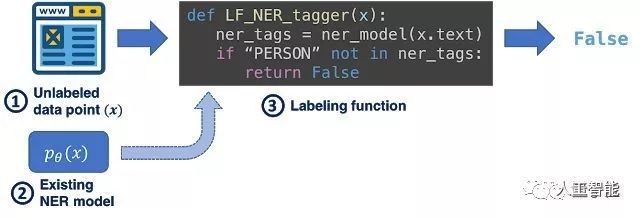
为了解决噪声等问题,Supert Drybell使用生成建模技术,以一种可证明一致的方式自动估计标记函数的准确性和相关性,而无需任何基本事实作为训练标签。然后用这种方法对每个数据点的输出进行重新加权,并组合成一个概率标签。
使用多种知识来源作为弱监督
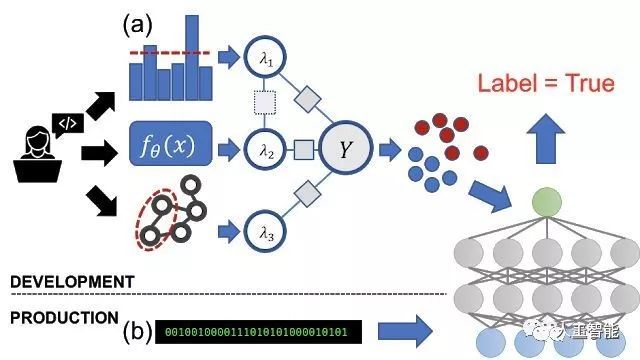
Snorkel Drybell先用多种知识来源作为弱监督,在基于MapReduce模板的pipeline中编写标记函数,每个标记函数都接受一个数据点生成的概率标签,并选择返回None(无标签)或输出标签。
这一步生成的标签带有大量噪声,甚至相互冲突,还行需要进一步的清洗才能用到最终的训练集中。
结合和重新利用现有资源对准确度建模
为了处理这些噪声标签,Snorkel DryBell将标记函数的输出组合成对每个数据点的训练标签置信度加权。这一步的难点在于,必须在没有任何真实标签的情况下完成。
研究人员使用生成建模技术,仅使用未标记的数据来学习每个标记函数的准确性。通过标签函数输出之间的一致性矩阵来学习打标签是否准确。
在Snorkel DryBell中,研究人员还实现了建模方法一种更快、无采样的版本,并在TensorFlow中实现,以处理Web规模的数据。
通过在Snorkel DryBell中使用此程序组合和建模标签函数的输出,能够生成高质量的训练标签。与两个分别有1.2万和8万个手工标记训练数据集比较,由Snorkel DryBell标记的数据集训练出的模型实现了一样的预测准确度。
将不可服务的知识迁移到可服务的模型
在许多情况下,可服务特征(可用于生产)和不可服务特征(太慢或太贵而无法用于生产)之间也有重要区别。这些不可服务的特征可能具有非常丰富的信号,但是有个问题是如何使用它们来训练,或者是帮助能在生产中部署的可服务模型呢?
在Snorkel DryBell中,用户发现可以在一个不可服务的特征集上编写标签函数,然后使用Snorkel DryBell输出的训练标签来训练在不同的、可服务的特征集上定义的模型。
这种跨特征转移将基准数据集的性能平均提高了52%。
这种方法可以被看作是一种新型的迁移学习,但不是在不同的数据集之间转移模型,而是在不同的特征集之间转移领域知识。它可以使用速度太慢、私有或其他不适合部署的资源,在廉价、实时特征上训练可服务的模型。
-
函数
+关注
关注
3文章
3868浏览量
61308 -
机器学习
+关注
关注
66文章
8122浏览量
130556 -
数据集
+关注
关注
4文章
1178浏览量
24351
原文标题:告别数据集资源匮乏,谷歌与斯坦福大学用弱监督学习给训练集打标签
文章出处:【微信号:worldofai,微信公众号:worldofai】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是零样本学习?为什么要搞零样本学习?
基于机器学习的车位状态预测方法
一文读懂制约我国高技术产业发展三大瓶颈性关键高分子材料之一——聚酰亚胺薄膜

MUS-CDB:遥感目标检测中的主动标注的具有类分布平衡的混合不确定性采样

机器学习有哪些算法?机器学习分类算法有哪些?机器学习预判有哪些算法?
利用 Superb AI Suite 和 NVIDIA TAO Toolkit 创建高质量的计算机视觉应用

小样本学习领域的未来发展方向

一个通用的自适应prompt方法,突破了零样本学习的瓶颈

机器学习相关介绍:支持向量机(低维到高维的映射)





 工商网监
工商网监
评论