 python为什么叫爬虫
python为什么叫爬虫
python为什么叫爬虫
作为一门编程语言而言,Python是纯粹的自由软件,以简洁清晰的语法和强制使用空白符进行语句缩进的特点从而深受程序员的喜爱。举一个例子:完成一个任务的话,c语言一共要写1000行代码,java要写100行,而python则只需要写20行的代码。使用python来完成编程任务的话编写的代码量更少,代码简洁简短可读性更强,一个团队进行开发的时候读别人的代码会更快,开发效率会更高,使工作变得更加高效。
这是一门非常适合开发网络爬虫的编程语言,而且相比于其他静态编程语言,Python抓取网页文档的接口更简洁;相比于其他动态脚本语言,Python的urllib2包提供了较为完整的访问网页文档的API。此外,python中有优秀的第三方包可以高效实现网页抓取,并可用极短的代码完成网页的标签过滤功能。
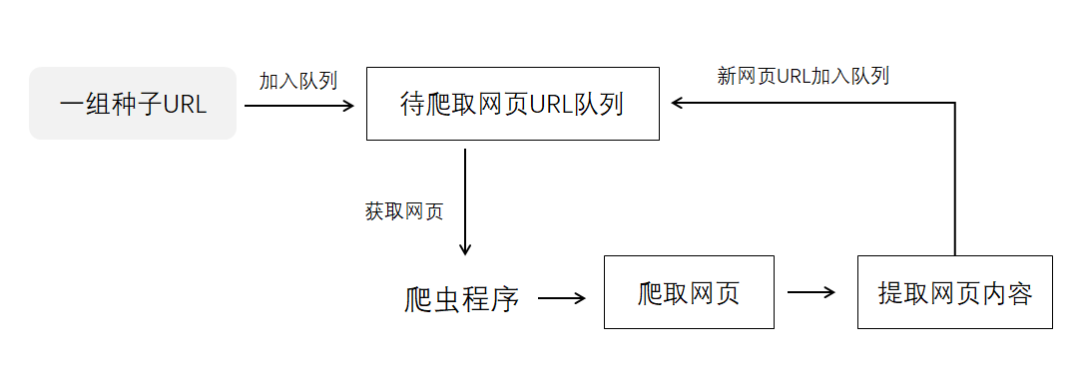
python爬虫的构架组成如下图:
1、URL管理器:管理待爬取的url集合和已爬取的url集合,传送待爬取的url给网页下载器;
2、网页下载器:爬取url对应的网页,存储成字符串,传送给网页解析器;
3、网页解析器:解析出有价值的数据,存储下来,同时补充url到URL管理器。
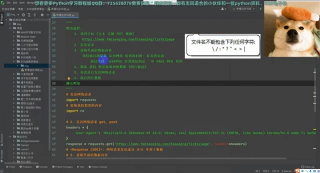
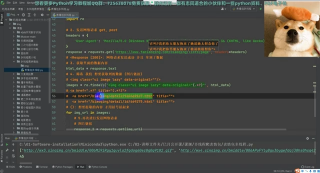
而python的工作流程则如下图:
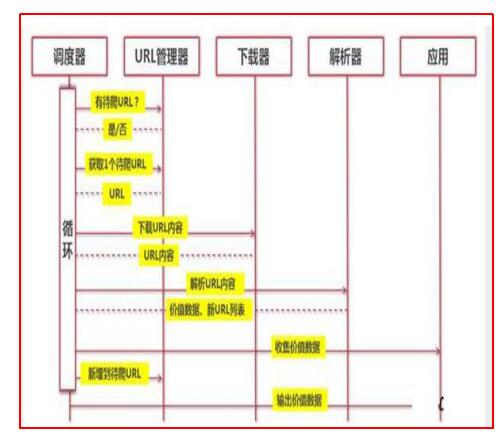
(Python爬虫通过URL管理器,判断是否有待爬URL,如果有待爬URL,通过调度器进行传递给下载器,下载URL内容,并通过调度器传送给解析器,解析URL内容,并将价值数据和新URL列表通过调度器传递给应用程序,并输出价值信息的过程。)
Python是一门非常适合开发网络爬虫的编程语言,提供了如urllib、re、json、pyquery等模块,同时又有很多成型框架,如Scrapy框架、PySpider爬虫系统等,本身又是十分的简洁方便所以是网络爬虫首选编程语言!
-
python
+关注
关注
51文章
4675浏览量
83466 -
爬虫
+关注
关注
0文章
77浏览量
6516
发布评论请先 登录
相关推荐
全球新闻网封锁OpenAI和谷歌AI爬虫
如何解决Python爬虫中文乱码问题?Python爬虫中文乱码的解决方法
爬虫的基本工作原理 用Scrapy实现一个简单的爬虫
Python2与Python3的差异
Python网络爬虫Selenium的简单使用
如何看待Python爬虫的合法性?
Python 一个超快的公共情报搜集爬虫
crawlerdetect:Python 三行代码检测爬虫
feapder:一款功能强大的爬虫框架
Python调用JS的 4 种方式
网络爬虫 Python和数据分析





 工商网监
工商网监
评论