 IBM Research AI团队用大规模的模拟存储器阵列训练深度神经网络
IBM Research AI团队用大规模的模拟存储器阵列训练深度神经网络
IBM 近日提出的全新芯片设计可以通过在数据存储的位置执行计算来加速全连接神经网络的训练。研究人员称,这种「芯片」可以达到 GPU 280 倍的能源效率,并在同样面积上实现 100 倍的算力。该研究的论文已经发表在上周出版的 Nature 期刊上。
在最近发表在Nature上的一篇论文中,IBM Research AI团队用大规模的模拟存储器阵列训练深度神经网络(DNN),达到了与GPU相当的精度。研究人员相信,这是在下一次AI突破所需要的硬件加速器发展道路上迈出的重要一步。
未来人工智能将需要大规模可扩展的计算单元,无论是在云端还是在边缘,DNN都会变得更大、更快,这意味着能效必须显著提高。虽然更好的GPU或其他数字加速器能在某种程度上起到帮助,但这些系统都不可避免地在数据的传输,也就是将数据从内存传到计算处理单元然后回传上花费大量的时间和能量。
模拟技术涉及连续可变的信号,而不是二进制的0和1,对精度具有内在的限制,这也是为什么现代计算机一般是数字型的。但是,AI研究人员已经开始意识到,即使大幅降低运算的精度,DNN模型也能运行良好。因此,对于DNN来说,模拟计算有可能是可行的。
但是,此前还没有人给出确凿的证据,证明使用模拟的方法可以得到与在传统的数字硬件上运行的软件相同的结果。也就是说,人们还不清楚DNN是不是真的能够通过模拟技术进行高精度训练。如果精度很低,训练速度再快、再节能,也没有意义。
在IBM最新发表的那篇Nature论文中,研究人员通过实验,展示了模拟非易失性存储器(NVM)能够有效地加速反向传播(BP)算法,后者是许多最新AI进展的核心。这些NVM存储器能让BP算法中的“乘-加”运算在模拟域中并行。
研究人员将一个小电流通过一个电阻器传递到一根导线中,然后将许多这样的导线连接在一起,使电流聚集起来,就实现了大量计算的并行。而且,所有这些都在模拟存储芯片内完成,不需要数字芯片里数据在存储单元和和处理单元之间传输的过程。
IBM的大规模模拟存储器阵列,训练深度神经网络达到了GPU的精度
(图片来源:IBM Research)
由于当前NVM存储器的固有缺陷,以前的相关实验都没有在DNN图像分类任务上得到很好的精度。但这一次,IBM的研究人员使用创新的技术,改善了很多不完善的地方,将性能大幅提升,在各种不同的网络上,都实现了与软件级的DNN精度。
单独看这个大规模模拟存储器阵列里的一个单元,由相变存储器(PCM)和CMOS电容组成,PCM放长期记忆(权重),短期的更新放在CMOS电容器里,之后再通过特殊的技术,消除器件与器件之间的不同。研究人员表示,这种方法是受了神经科学的启发,使用了两种类型的“突触”:短期计算和长期记忆。
这些基于NVM的芯片在训练全连接层方面展现出了极强的潜力,在计算能效 (28,065 GOP/sec/W) 和通量(3.6 TOP/sec/mm^2)上,超过了当前GPU的两个数量级。
这项研究表明了,基于模拟存储器的方法,能够实现与软件等效的训练精度,并且在加速和能效上有数量级的提高,为未来设计全新的AI芯片奠定了基础。研究人员表示,他们接下来将继续优化,处理全连接层和其他类型的计算。
-
IBM
+关注
关注
3文章
1671浏览量
74272 -
存储器
+关注
关注
38文章
7148浏览量
161979 -
AI芯片
+关注
关注
17文章
1652浏览量
34380
原文标题:GGAI 前沿 | IBM全新AI芯片设计登上Nature:算力是GPU的100倍
文章出处:【微信号:ggservicerobot,微信公众号:高工智能未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
FPGA在深度学习应用中或将取代GPU
用STM32CubeMX导入神经网络,aiRun的indata应该定义成什么格式呢?
详解深度学习、神经网络与卷积神经网络的应用

Kaggle知识点:训练神经网络的7个技巧

大规模神经网络优化:超参最佳实践与规模律

《 AI加速器架构设计与实现》+第一章卷积神经网络观后感
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别
卷积神经网络算法代码matlab
卷积神经网络模型训练步骤
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法
浅析三种主流深度神经网络
浅析三种主流深度神经网络
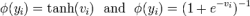






 工商网监
工商网监
评论