 FPGA如何实现FP16格式点积级联运算
FPGA如何实现FP16格式点积级联运算
通过使用Achronix Speedster7t FPGA中的机器学习加速器MLP72,开发人员可以轻松选择浮点/定点格式和多种位宽,或快速应用块浮点,并通过内部级联可以达到理想性能。
神经网络架构中的核心之一就是卷积层,卷积的最基本操作就是点积。向量乘法的结果是向量的每个元素的总和相乘在一起,通常称之为点积。此向量乘法如下所示:
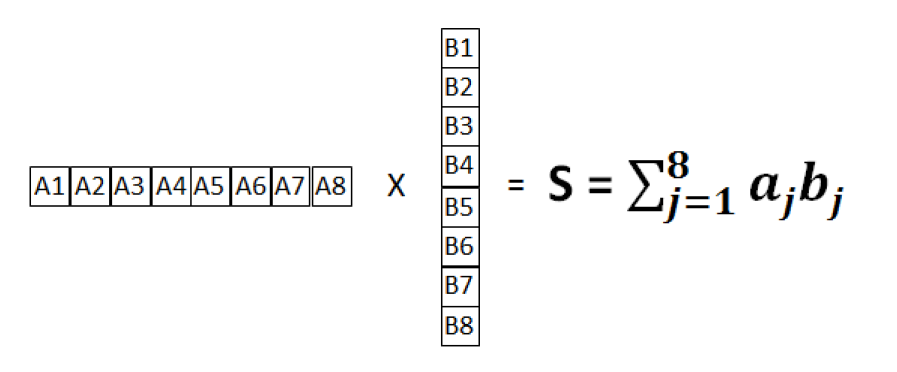
图1点积操作
该总和S由每个矢量元素的总和相乘而成,因此
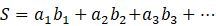 本文讲述的是使用FP16格式的点积运算实例,展示了MLP72支持的数字类型和乘数的范围。
此设计实现了同时处理8对FP16输入的点积。该设计包含四个MLP72,使用MLP内部的级联路径连接。每个MLP72将两个并行乘法的结果相加
本文讲述的是使用FP16格式的点积运算实例,展示了MLP72支持的数字类型和乘数的范围。
此设计实现了同时处理8对FP16输入的点积。该设计包含四个MLP72,使用MLP内部的级联路径连接。每个MLP72将两个并行乘法的结果相加 ,每个乘法都是i_a输入乘以i_b输入(均为FP16格式)的结果。来自每个MLP72的总和沿着MLP72的列级联到上面的下一个MLP72块。在最后一个MLP72中,在每个周期上,计算八个并行FP16乘法的总和。
最终结果是多个输入周期内的累加总和,其中累加由i_first和i_last输入控制。i_first输入信号指示累加和归零的第一组输入。i_last信号指示要累加和加到累加的最后一组输入。最终的i_last值可在之后的六个周期使用,并使用i_last o_valid进行限定。两次运算之间可以无空拍。
,每个乘法都是i_a输入乘以i_b输入(均为FP16格式)的结果。来自每个MLP72的总和沿着MLP72的列级联到上面的下一个MLP72块。在最后一个MLP72中,在每个周期上,计算八个并行FP16乘法的总和。
最终结果是多个输入周期内的累加总和,其中累加由i_first和i_last输入控制。i_first输入信号指示累加和归零的第一组输入。i_last信号指示要累加和加到累加的最后一组输入。最终的i_last值可在之后的六个周期使用,并使用i_last o_valid进行限定。两次运算之间可以无空拍。
- 配置说明

表1 FP16点积配置表
- 端口说明

表2 FP16点积端口说明表
- 时序图
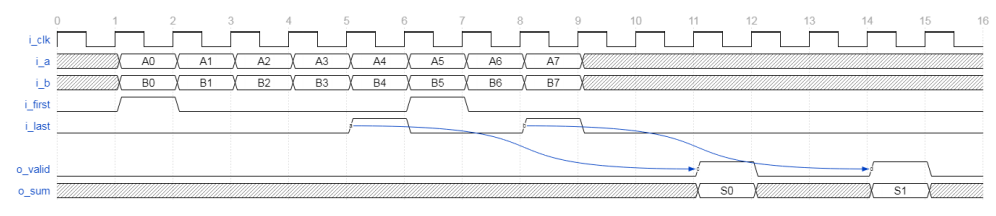
图2 FP16点积时序图
其中,
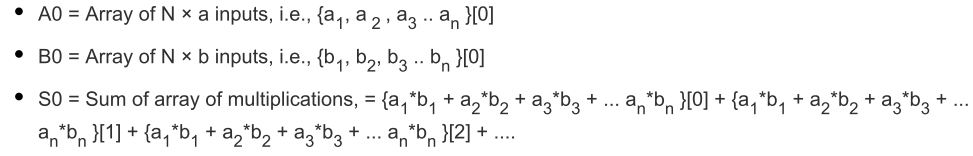 那么,以上运算功能如何对应到MLP内部呢?其后的细节已分为MLP72中的多个功能阶段进行说明。
那么,以上运算功能如何对应到MLP内部呢?其后的细节已分为MLP72中的多个功能阶段进行说明。
- 进位链
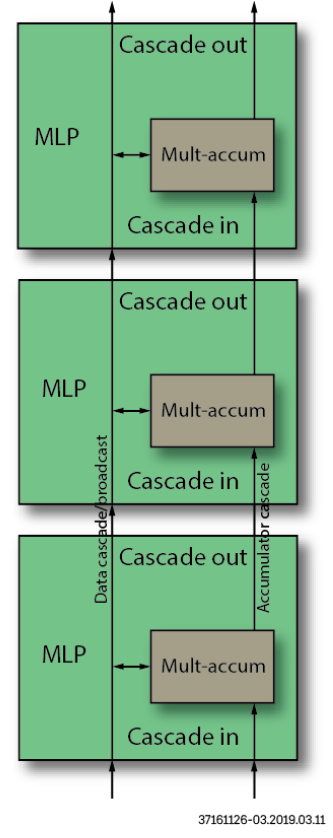
图3 MLP进位链
- 乘法阶段
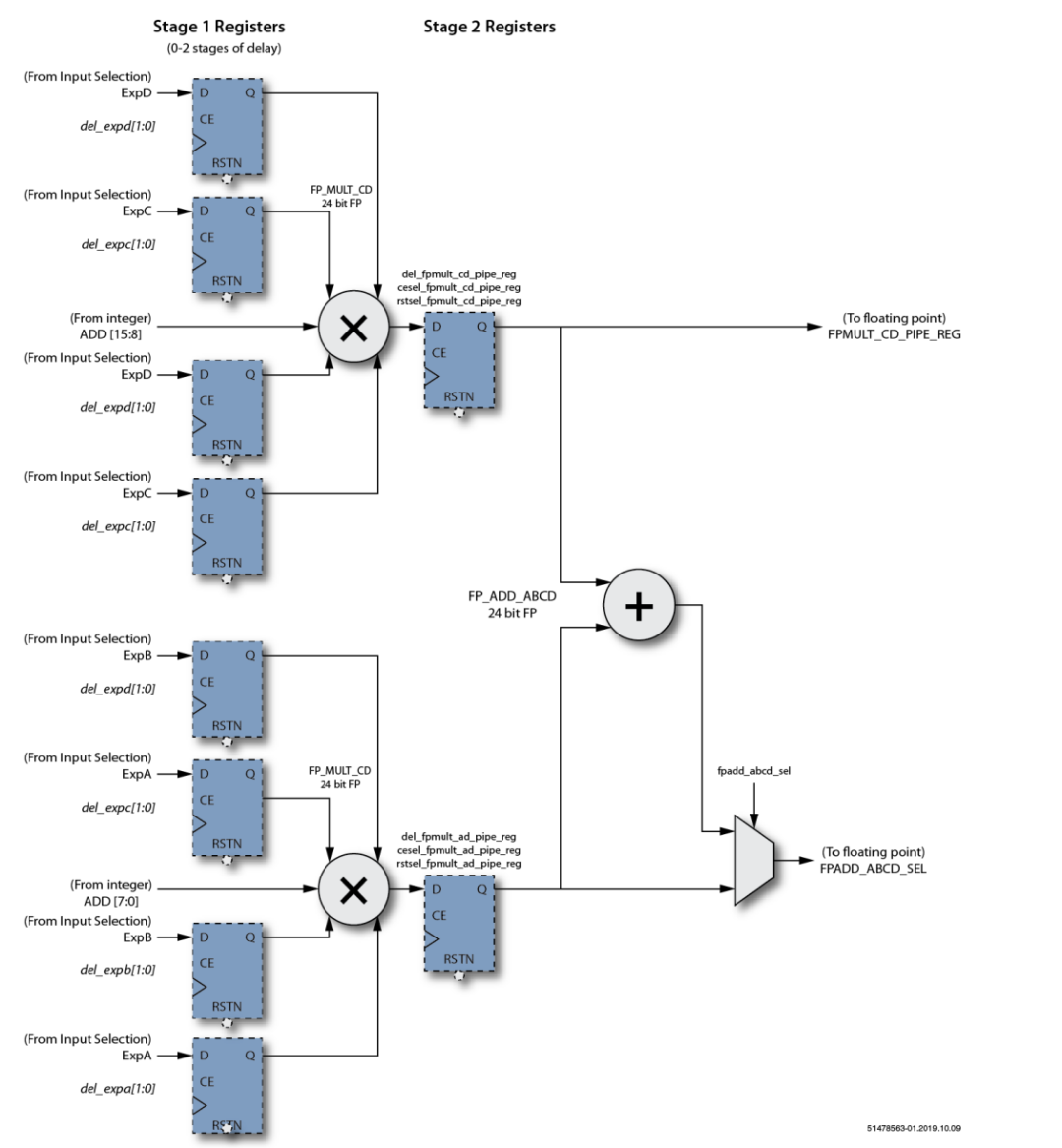
图4 MLP乘法功能阶段框图
MLP72浮点乘法级包括两个24位全浮点乘法器和一个24位全浮点加法器。两个乘法器执行A×B和C×D的并行计算。加法器将两个结果相加得到A×B + C×D。 乘法阶段有两个输出。下半部分输出可以在A×B或(A×B + C×D)之间选择。上半部分输出始终为C×D。 乘法器和加法器使用的数字格式由字节选择参数以及和参数设置的格式确定。 浮点输出具有与整数输出级相同的路径和结构。MLP72可以配置为在特定阶段选择整数或等效浮点输入。输出支持两个24位全浮点加法器,可以对其进行加法或累加配置。进一步可以加载加法器(开始累加),可以将其设置为减法,并支持可选的舍入模式。 最终输出阶段支持将浮点输出格式化为MLP72支持的三种浮点格式中的任何一种。此功能使MLP72可以外部支持大小一致的浮点输入和输出(例如fp16或bfloat16),而在内部以fp24执行所有计算。
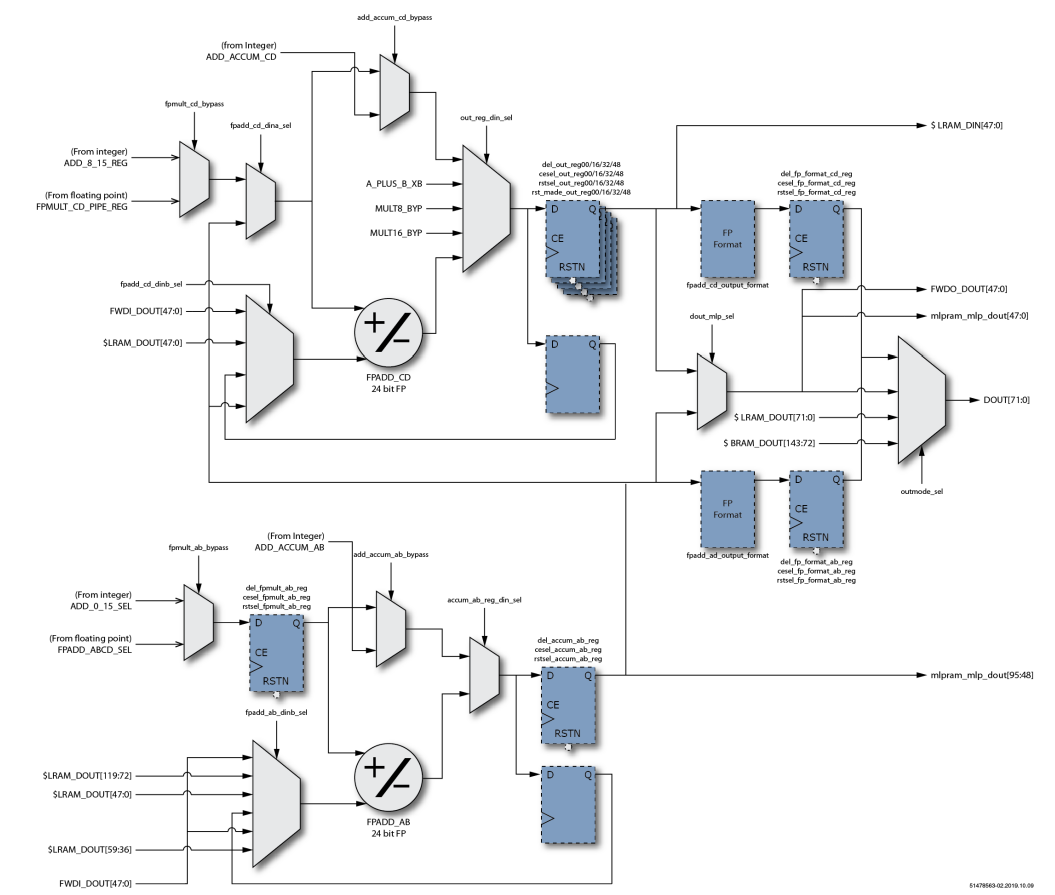
图5 MLP浮点输出阶段框图
需要强调的是本设计输入和输出都是FP16格式,中间计算过程,即进位链上的fwdo_out和fwdi_dout 都是FP24格式。具体逻辑框图如下所示:
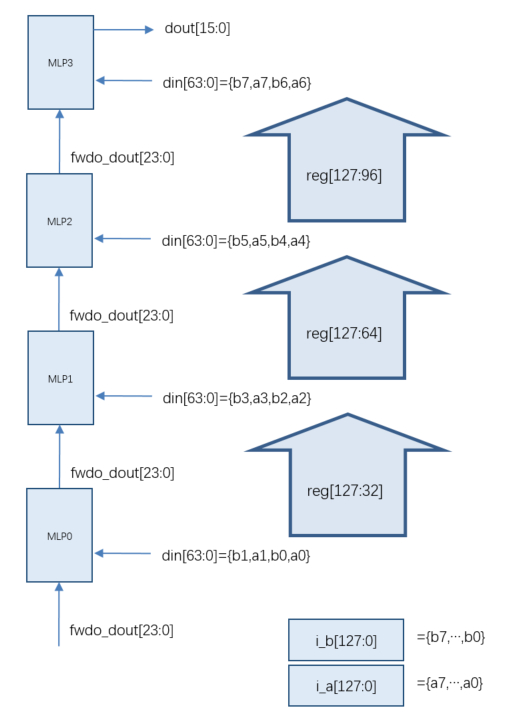
图6 FP16点积逻辑框图
MLP内部数据流示意图:
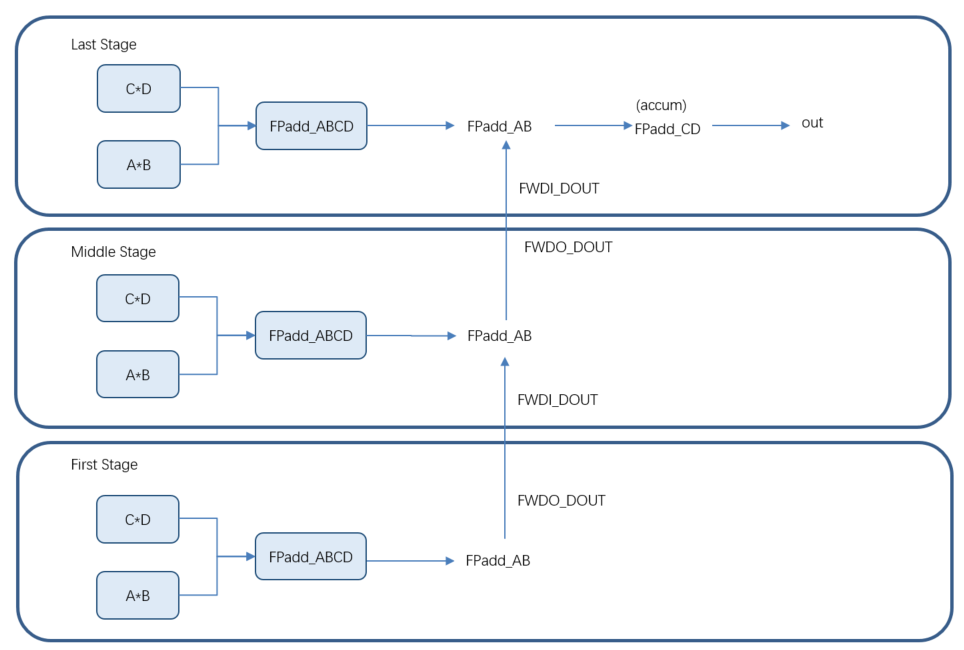
图7 FP16点积在MLP内部数据流图
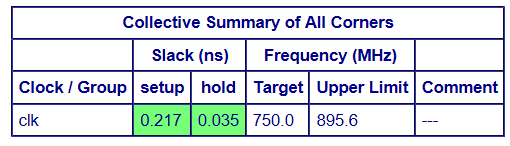
最终ACE的时序结果如下:
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
FPGA
+关注
关注
1603文章
21331浏览量
593304 -
机器学习
+关注
关注
66文章
8136浏览量
130584 -
MLP
+关注
关注
0文章
56浏览量
4074
原文标题:详解FPGA如何实现FP16格式点积级联运算
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
Python:从串口读取数据并以16进制格式展示
本文凌顺实验室(lingshunlab.com)简单实现Python读取串口数据,并且按16进制格式显示出来。

求助,请问12位传感器数据如何变成YUY2格式?
请教下传感器输出的12位并行数据RAW通过FPGA采集出来,然后要转成YUY2格式通过GPIF接口传给FX3,再通过USB显示实时图像视频。现在问题是12位传感器数据如何变成YUY2格式?通过slaveFIFO时序
发表于 02-28 07:25
缝缝补补的浮点数进制转换器
[浮点数]()在计算机科学中是一种重要的数据类型,用于表示实数。其中,FP32和FP16是两种常见的浮点数格式,分别占用32位和16位。
FlashAttention2详解(性能比FlashAttention提升200%)
GPU performance characteristics. GPU主要计算单元(如浮点运算单元)和内存层次结构。大多数现代GPU包含专用的低精度矩阵乘法单元(如Nvidia GPU的Tensor Core用于FP16/BF16

为什么研究浮点加法运算,对FPGA实现方法很有必要?
,浮点加法器是现代信号处理系统中最重要的部件之一。FPGA是当前数字电路研究开发的一种重要实现形式,它与全定制ASIC电路相比,具有开发周期短、成本低等优点。 但多数FPGA不支持浮点运算

无法使用MYRIAD在OpenVINO trade中运行YOLOv7自定义模型怎么解决?
的export.py 脚本将 YOLOv7 模型转换为 ONNX 格式。
转换ONNX 模型到 IR,精度为 FP16:
mo -m yolov7.onnx --reverse_input_channel
发表于 08-15 08:29
基于算能第四代AI处理器BM1684X的边缘计算盒子
英码IVP03X智能工作站搭载算能全新一代AI处理器BM1684X,八核ARM Cortex-A53,主频2.3GHz;INT8算力高达32Tops,FP16算力达16 TFLOPS,FP32算力 2 TFLOPS,边缘端少有的
发表于 08-10 09:46
•759次阅读

elcdif可以使用kELCDIF_ PixelFormatRAW8格式,输出带宽为kELCDIF_ DataBus16Bit吗?
elcdif可以使用 kELCDIF_ PixelFormatRAW8 格式,输出带宽为 kELCDIF_ DataBus16Bit 吗?请问如何实现
发表于 05-09 10:57





 工商网监
工商网监
评论