 HBM3万事俱备,只欠标准定稿
HBM3万事俱备,只欠标准定稿
从PC时代走向移动与AI时代,芯片的架构也从以CPU为中心走向了以数据为中心。AI带来的考验不仅包括芯片算力,也包括内存带宽。纵使DDR和GDDR速率较高,在不少AI算法和神经网络上,却屡屡遇上内存带宽上的限制,主打大带宽的HBM也就顺势成了数据中心、HPC等高性能芯片中首选的DRAM方案。
当下JEDEC还没有给出HBM3标准的最终定稿,但参与了标准制定工作的IP厂商们已经纷纷做好了准备工作。不久前,Rambus就率先公布了支持HBM3的内存子系统,近日,新思科技也公布了业界首个完整HBM3 IP与验证方案。
IP厂商先行
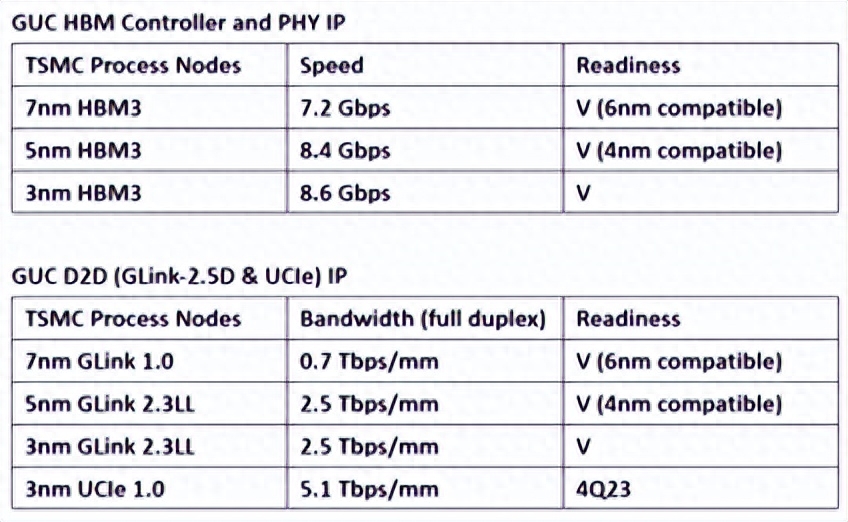
早在今年初,SK海力士就对HBM3内存产品的性能给出了前瞻,称其带宽大于665 GB/s,I/O速度大于5.2Gbps,不过这只是一个过渡的性能。同在今年,IP厂商公布的数据进一步拉高了上限。比如Rambus公布HBM3内存子系统中,I/O速度高达8.4Gbps,内存带宽最高可至1.075TB/s。
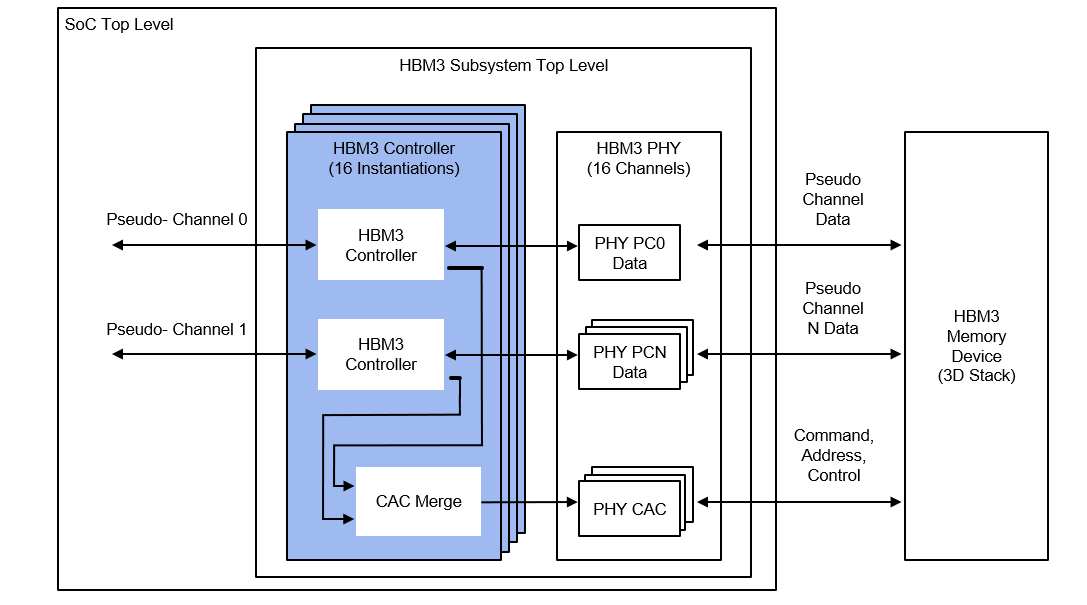
今年6月,台湾创意电子发布了基于台积电CoWoS技术的AI/HPC/网络平台,搭载了的HBM3控制器与PHY IP,I/O速度最高达到7.2Gbps。创意电子还在申请一项中介层布线专利,支持任何角度的锯齿形布线,可将HBM3 IP拆分至两个SoC上使用。
新思科技公布的完整HBM3 IP方案为2.5D多晶片封装系统提供了控制器、PHY和验证IP,称设计者可在SoC中用到低功耗更大带宽的内存。新思的DesignWare HBM3控制器与PHY IP基于经芯片验证过的HBM2E IP打造,而HBM3 PHY IP基于5nm制程打造,每个引脚的速率可达7200 Mbps,内存带宽最高可提升至921GB/s。
封装加成
以上还只是单层HBM的数据,通过2.5D封装堆叠2层或者4层后,内存带宽也将成倍突破。以英伟达的A100加速器为例,英伟达首发的80GB版本采用了4层HBM2达到了1.6TB/s的带宽,之后推出了5层HBM2E的版本,进一步将带宽提高至2TB/s。而这样的带宽表现,只需2层HBM3即可实现,四五层的配置更是远超市面上已有的内存规格。
此外,逻辑+HBM的方法已经不新鲜了,已经有不少GPU和服务器芯片都采用了类似的设计。然而随着晶圆厂不断在2.5D封装技术上发力,单个芯片上HBM的数量也在增加。比如上文中提到的台积电CoWoS技术,可在SoC芯片中集成4个以上的HBM,英伟达的P100就集成了4个HBM2,而NEC的Sx-Aurora向量处理器则集成了6个HBM2。
三星也在开发下一代的I-Cube 2.5D封装技术,除了支持集成4到6个HBM以外,也在开发两个逻辑晶片+8个HBM的I-Cube 8方案。类似的2.5D封装技术还有英特尔的EMIB,但不过HBM主要用于其Agilex FPGA。
结语
目前美光、三星、SK海力士等内存厂商都已经在纷纷跟进这一新的DRAM标准,SoC设计厂商Socionext与新思合作,在其多晶片的设计中引入HBM3,除了必定支持的x86架构外,Arm的Neoverse N2平台也已计划了对HBM3的支持,SiFive的RISC-V SoC也加入了HBM3 IP。但即便JEDEC没有“卡壳”,在年末的关头发布了HBM3正式标准,我们也可能要等到2022年下半年才能见到HBM3相关产品的面世。
大家都已经在不少高性能芯片上见到了HBM2/2E的身影,尤其是数据中心应用,比如英伟达的Tesla P100/V100、AMD的Radeon Instinct MI25、英特尔的Nervana神经网络处理器以及谷歌的TPU v2等等。
消费级应用却似乎正在与HBM渐行渐远,过去还有AMD的Radeon RxVega64/Vega 56以及英特尔的KabyLake-G这样利用了HBM的图形产品,再高一级也有英伟达的Quaddro GP100/GV100和AMD的Radeon Pro WX这样的专业绘图GPU。
如今这些产品都用回了GDDR DRAM,毕竟消费级应用目前尚未出现带宽瓶颈,速率和成本反倒才是芯片制造商最看重的,而HBM3在优点上提及了更大带宽更高的功效,却并没有降低成本。
当下JEDEC还没有给出HBM3标准的最终定稿,但参与了标准制定工作的IP厂商们已经纷纷做好了准备工作。不久前,Rambus就率先公布了支持HBM3的内存子系统,近日,新思科技也公布了业界首个完整HBM3 IP与验证方案。
IP厂商先行
早在今年初,SK海力士就对HBM3内存产品的性能给出了前瞻,称其带宽大于665 GB/s,I/O速度大于5.2Gbps,不过这只是一个过渡的性能。同在今年,IP厂商公布的数据进一步拉高了上限。比如Rambus公布HBM3内存子系统中,I/O速度高达8.4Gbps,内存带宽最高可至1.075TB/s。
今年6月,台湾创意电子发布了基于台积电CoWoS技术的AI/HPC/网络平台,搭载了的HBM3控制器与PHY IP,I/O速度最高达到7.2Gbps。创意电子还在申请一项中介层布线专利,支持任何角度的锯齿形布线,可将HBM3 IP拆分至两个SoC上使用。
新思科技公布的完整HBM3 IP方案为2.5D多晶片封装系统提供了控制器、PHY和验证IP,称设计者可在SoC中用到低功耗更大带宽的内存。新思的DesignWare HBM3控制器与PHY IP基于经芯片验证过的HBM2E IP打造,而HBM3 PHY IP基于5nm制程打造,每个引脚的速率可达7200 Mbps,内存带宽最高可提升至921GB/s。
封装加成
以上还只是单层HBM的数据,通过2.5D封装堆叠2层或者4层后,内存带宽也将成倍突破。以英伟达的A100加速器为例,英伟达首发的80GB版本采用了4层HBM2达到了1.6TB/s的带宽,之后推出了5层HBM2E的版本,进一步将带宽提高至2TB/s。而这样的带宽表现,只需2层HBM3即可实现,四五层的配置更是远超市面上已有的内存规格。
此外,逻辑+HBM的方法已经不新鲜了,已经有不少GPU和服务器芯片都采用了类似的设计。然而随着晶圆厂不断在2.5D封装技术上发力,单个芯片上HBM的数量也在增加。比如上文中提到的台积电CoWoS技术,可在SoC芯片中集成4个以上的HBM,英伟达的P100就集成了4个HBM2,而NEC的Sx-Aurora向量处理器则集成了6个HBM2。
三星也在开发下一代的I-Cube 2.5D封装技术,除了支持集成4到6个HBM以外,也在开发两个逻辑晶片+8个HBM的I-Cube 8方案。类似的2.5D封装技术还有英特尔的EMIB,但不过HBM主要用于其Agilex FPGA。
结语
目前美光、三星、SK海力士等内存厂商都已经在纷纷跟进这一新的DRAM标准,SoC设计厂商Socionext与新思合作,在其多晶片的设计中引入HBM3,除了必定支持的x86架构外,Arm的Neoverse N2平台也已计划了对HBM3的支持,SiFive的RISC-V SoC也加入了HBM3 IP。但即便JEDEC没有“卡壳”,在年末的关头发布了HBM3正式标准,我们也可能要等到2022年下半年才能见到HBM3相关产品的面世。
大家都已经在不少高性能芯片上见到了HBM2/2E的身影,尤其是数据中心应用,比如英伟达的Tesla P100/V100、AMD的Radeon Instinct MI25、英特尔的Nervana神经网络处理器以及谷歌的TPU v2等等。
消费级应用却似乎正在与HBM渐行渐远,过去还有AMD的Radeon RxVega64/Vega 56以及英特尔的KabyLake-G这样利用了HBM的图形产品,再高一级也有英伟达的Quaddro GP100/GV100和AMD的Radeon Pro WX这样的专业绘图GPU。
如今这些产品都用回了GDDR DRAM,毕竟消费级应用目前尚未出现带宽瓶颈,速率和成本反倒才是芯片制造商最看重的,而HBM3在优点上提及了更大带宽更高的功效,却并没有降低成本。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
内存
+关注
关注
8文章
2767浏览量
72756 -
HBM
+关注
关注
0文章
231浏览量
14382 -
HBM3
+关注
关注
0文章
69浏览量
62
发布评论请先 登录
相关推荐
英伟达、微软、亚马逊等排队求购SK海力士HBM芯片,这些国产设备厂迎机遇
AMD、微软和亚马逊等。 HBM(高带宽存储器),是由AMD和SK海力士发起的基于3D堆栈工艺的高性能DRAM,适用于高存储器带宽需求的应用场合。如今HBM已经发展出HBM2、HBM

HBM3E起飞,冲锋战鼓已然擂响
HBM3自2022年1月诞生,便凭借其独特的2.5D/3D内存架构,迅速成为高性能计算领域的翘楚。HBM3不仅继承了前代产品的优秀特性,更在技术上取得了显著的突破。它采用了高达1024位的数据路径,并以惊人的6.4 Gb/s的速率运行,实现了高达819 Gb/s的带宽,为

HBM、HBM2、HBM3和HBM3e技术对比
AI服务器出货量增长催化HBM需求爆发,且伴随服务器平均HBM容量增加,经测算,预期25年市场规模约150亿美元,增速超过50%。
发表于 03-01 11:02
•336次阅读

SK海力士第四季转亏为盈 HBM3营收增长5倍
韩国存储芯片巨头SK海力士在2023年12月31日公布的第四季度财报中,展现出强大的增长势头。数据显示,公司的主力产品DDR5 DRAM和HBM3的营收较2022年分别增长了4倍和5倍以上,成为推动公司营收增长的主要力量。
Rambus通过9.6 Gbps HBM3内存控制器IP大幅提升AI性能
Gbps 的性能,可支持 HBM3 标准的持续演进。相比 HBM3 Gen1 6.4 Gbps 的数据速率,Rambus HBM3 内存控制器的数据速率提高了 50%,总内存吞吐量超
Rambus通过9.6 Gbps HBM3内存控制器IP大幅提升AI性能
为增强AI/ML及其他高级数据中心工作负载打造的 Rambus 高性能内存 IP产品组合 高达9.6 Gbps的数据速率,支持HBM3内存标准的未来演进 实现业界领先的1.2 TB/s以上内存吞吐量
发表于 12-07 11:01
•129次阅读
HBM市场将爆发“三国之战”
英伟达的图形处理器(gpu)是高附加值产品,特别是high end h100车型的售价为每个6000万韩元(约4.65万美元)。英伟达将在存储半导体领域发挥潜在的游戏链条作用。hbm3营销的领先者sk海力士自去年以后独家向英伟达供应hbm3,领先于三星电子。
HBM3E明年商业出货,兼具高速和低成本优点
)、HBM3(第四代)、HBM3E(第五代)的顺序开发。而HBM3E 是 HBM3 的扩展(Extended)版本。 美光科技日前宣称新款HBM
创意电子宣布5nm HBM3 PHY和控制器经过硅验证,速度为8.4Gbps
来源:EE Times 先进ASIC领导厂商创意电子(GUC)宣布,公司HBM3解决方案已通过8.4 Gbps硅验证,该方案采用台积电5纳米工艺技术。该平台在台积电2023北美技术研讨会合作伙伴展示
SK海力士开发出全球最高规格HBM3E,向英伟达提供样品
该公司表示,HBM3E(HBM3的扩展版本)的成功开发得益于其作为业界唯一的HBM3大规模供应商的经验。凭借作为业界最大HBM产品供应商的经验和量产准备水平,SK海力士计划在明年上半年
业界最快、容量最高的HBM?
来源:半导体芯科技编译 业内率先推出8层垂直堆叠的24GB容量HBM3 Gen2,带宽超过1.2TB/s,并通过先进的1β工艺节点实现“卓越功效”。 美光科技已开始提供业界首款8层垂直堆叠的24GB
美光推出业界首款8层堆叠的24GB容量第二代HBM3内存
Micron Technology Inc.(美光科技股份有限公司,纳斯达克股票代码:MU)今日宣布,公司已开始出样业界首款 8 层堆叠的 24GB 容量第二代 HBM3 内存,其带宽超过
三星计划为英伟达AI GPU提供HBM3和2.5D封装服务;传苹果悄悄开发“Apple GPT” 或将挑战OpenAI
热点新闻 1、三星计划为英伟达AI GPU提供HBM3和2.5D封装服务 据报道,英伟达正在努力实现数据中心AI GPU中使用的HBM3和2.5D封装的采购多元化。消息人士称,这家美国芯片巨头正在






 工商网监
工商网监
评论