 一些常见的图像分类任务中 额外支持的8种数据增广方法
一些常见的图像分类任务中 额外支持的8种数据增广方法
如果要把深度学习开发过程中几个环节按重要程度排个序的话,相信准备训练数据肯定能排在前几位。要知道一个模型网络被编写出来后,也只是一坨代码而已,和智能基本不沾边,它只有通过学习大量的数据,才能学会如何作推理。因此训练数据其实和一样东西非常像!——武侠小说中的神功秘笈,学之前菜鸟一只,学之后一统江湖!
但很可惜的是,训练数据和秘笈还有一个特点很相似,那就是可遇而不可求!也就是说很难获取,除了那些公共数据集之外,如果用户想基于自己的业务场景准备数据的话,不仅数据的生产和标注过程会比较复杂,而且一般需要的数量规模也会非常庞大,因为只有充足的数据,才能确保模型训练的效果,这导致数据集的制作成本往往非常高。这个情况在计算机视觉领域尤甚,因为图像要一张一张拍摄与标注,要是搞个几十万图片,想想都让人“不寒而栗”! 为了应对上述问题,在计算机视觉领域中,图像数据增广是一种常用的解决方法,常用于数据量不足或者模型参数较多的场景。如果用户手中数据有限的话,则可以使用数据增广的方法扩充数据集。一些常见的图像分类任务中,例如ImageNet一千种物体分类,在预处理阶段会使用一些标准的数据增广方法,包括随机裁剪和翻转。除了这些标准的数据增广方法之外,飞桨的图像分类套件PaddleClas还会额外支持8种数据增广方法,下面将为大家逐一讲解。
下文所有的代码都来自PaddleClas:
GitHub 链接:
https://github.com/PaddlePaddle/PaddleClas
Gitee 链接:
https://gitee.com/paddlepaddle/PaddleClas
8大数据增广方法
首先咱们先来看看以ImageNet图像分类任务为代表的标准数据增广方法,该方法的操作过程可以分为以下几个步骤:
图像解码,也就是将图像转为Numpy格式的数据,简写为 ImageDecode。
图像随机裁剪,随机将图像的长宽均裁剪为 224 大小,简写为 RandCrop。
水平方向随机翻转,简写为 RandFlip。
图像数据的归一化,简写为 Normalize。
图像数据的重排。图像的数据格式为[H, W, C](即高度、宽度和通道数),而神经网络使用的训练数据的格式为[C, H, W],因此需要对图像数据重新排列,例如[224, 224, 3]变为[3, 224, 224],简写为 Transpose。
多幅图像数据组成 batch 数据,如 BatchSize 个[3, 224, 224]的图像数据拼组成[batch-size, 3, 224, 224],简写为 Batch。
相比于上述标准的图像增广方法,研究者也提出了很多改进的图像增广策略,这些策略均是在标准增广方法的不同阶段插入一定的操作,基于这些策略操作所处的不同阶段,大概分为三类:
图像变换类:对 RandCrop 后的 224 的图像进行一些变换,包括AutoAugment和RandAugment。
图像裁剪类:对Transpose 后的 224 的图像进行一些裁剪,包括CutOut、RandErasing、HideAndSeek和GridMask。
图像混叠:对 Batch 后的数据进行混合或叠加,包括Mixup和Cutmix。
PaddleClas中集成了上述所有的数据增广策略,每种数据增广策略的参考论文与参考开源代码均在下面的介绍中列出。下文将介绍这些策略的原理与使用方法,并以下图为例,对变换后的效果进行可视化。
图像变换类
通过组合一些图像增广的子策略对图像进行修改和跳转,这些子策略包括亮度变换、对比度增强、锐化等。基于策略组合的规则不同,可以划分为AutoAugment和RandAugment两种方式。
01
AutoAugment
论文地址:
https://arxiv.org/abs/1805.09501v1
不同于常规的人工设计图像增广方式,AutoAugment是在一系列图像增广子策略的搜索空间中通过搜索算法找到并组合成适合特定数据集的图像增广方案。针对ImageNet数据集,最终搜索出来的数据增广方案包含 25 个子策略组合,每个子策略中都包含两种变换,针对每幅图像都随机的挑选一个子策略组合,然后以一定的概率来决定是否执行子策略中的每种变换。 PaddleClas中AutoAugment的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportImageNetPolicy
fromppcls.data.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#使用AutoAugment图像增广方法
autoaugment_op=ImageNetPolicy()
ops=[decode_op,resize_op,autoaugment_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 变换结果如下图所示。
02
RandAugment
论文地址: https://arxiv.org/pdf/1909.13719.pdf AutoAugment 的搜索方法比较暴力,直接在数据集上搜索针对该数据集的最优策略,计算量会很大。在 RandAugment对应的论文中作者发现,针对越大的模型,越大的数据集,使用 AutoAugment 方式搜索到的增广方式产生的收益也就越小;而且这种搜索出的最优策略是针对指定数据集的,迁移能力较差,并不太适合迁移到其他数据集上。 在 RandAugment 中,作者提出了一种随机增广的方式,不再像 AutoAugment 中那样使用特定的概率确定是否使用某种子策略,而是所有的子策略都会以同样的概率被选择到,论文中的实验也表明这种数据增广方式即使在大模型的训练中也具有很好的效果。 PaddleClas中RandAugment的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportRandAugment
fromppcls.data.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#使用RandAugment图像增广方法
randaugment_op=RandAugment()
ops=[decode_op,resize_op,randaugment_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 变换结果如下图所示。
图像裁剪类
图像裁剪类主要是对Transpose 后的 224 的图像进行一些裁剪,即裁剪掉部分图像,或者也可以理解为对部分图像做遮盖,共有CutOut、RandErasing、HideAndSeek和GridMask四种方法。
03
Cutout
论文地址:
https://arxiv.org/abs/1708.04552
Cutout 可以理解为 Dropout 的一种扩展操作,不同的是 Dropout 是对图像经过网络后生成的特征进行遮挡,而 Cutout 是直接对输入的图像进行遮挡,相对于Dropout对噪声的鲁棒性更好。作者在论文中也进行了说明,这样做法有以下两点优势:
通过 Cutout 可以模拟真实场景中主体被部分遮挡时的分类场景。
可以促进模型充分利用图像中更多的内容来进行分类,防止网络只关注显著性的图像区域,从而发生过拟合。
PaddleClas中Cutout的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportCutout
fromppcls.data.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#使用Cutout图像增广方法
cutout_op=Cutout(n_holes=1,length=112)
ops=[decode_op,resize_op,cutout_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops) 裁剪结果如下图所示:
04
RandomErasing
论文地址:
https://arxiv.org/pdf/1708.04896.pdf
RandomErasing 与 Cutout 方法类似,同样是为了解决训练出的模型在有遮挡数据上泛化能力较差的问题,作者在论文中也指出,随机裁剪的方式与随机水平翻转具有一定的互补性。作者也在行人再识别(REID)上验证了该方法的有效性。与Cutout不同的是,在RandomErasing中,图片以一定的概率接受该种预处理方法,生成掩码的尺寸大小与长宽比也是根据预设的超参数随机生成。 PaddleClas中RandomErasing的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimportRandomErasing
fromppcls.data.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#使用RandomErasing图像增广方法
randomerasing_op=RandomErasing()
ops=[decode_op,resize_op,tochw_op,randomerasing_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 裁剪结果如下图所示。
05
HideAndSeek
论文地址:
https://arxiv.org/pdf/1811.02545.pdf
HideAndSeek方法将图像分为若干大小相同的区域块(patch),对于每块区域,都以一定的概率生成掩码,如下图所示,可能是完全遮挡、完全不遮挡或者遮挡部分。
PaddleClas中HideAndSeek的使用方法如下所示: fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimportHideAndSeek
fromppcls.data.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#使用HideAndSeek图像增广方法
hide_and_seek_op=HideAndSeek()
ops=[decode_op,resize_op,tochw_op,hide_and_seek_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 裁剪结果如下图所示。
06
GridMask
论文地址:
https://arxiv.org/abs/2001.04086
作者在论文中指出,之前的图像裁剪方法存在两个问题,如下图所示:
过度删除区域可能造成目标主体大部分甚至全部被删除,或者导致上下文信息的丢失,导致增广后的数据成为噪声数据;
保留过多的区域,对目标主体及上下文基本产生不了什么影响,失去增广的意义。
因此如何避免过度删除或过度保留成为需要解决的核心问题。GridMask是通过生成一个与原图分辨率相同的掩码,并将掩码进行随机翻转,与原图相乘,从而得到增广后的图像,通过超参数控制生成的掩码网格的大小。 在训练过程中,有两种以下使用方法:
设置一个概率p,从训练开始就对图片以概率p使用GridMask进行增广。
一开始设置增广概率为0,随着迭代轮数增加,对训练图片进行GridMask增广的概率逐渐增大,最后变为p。
论文中表示,经过验证后,上述第二种方法的训练效果更好一些。 PaddleClas中GridMask的使用方法如下所示。 fromdata.imaugimportDecodeImage
fromdata.imaugimportResizeImage
fromdata.imaugimportToCHWImage
fromdata.imaugimportGridMask
fromdata.imaugimporttransform
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#图像数据的重排
tochw_op=ToCHWImage()
#使用GridMask图像增广方法
gridmask_op=GridMask(d1=96,d2=224,rotate=1,ratio=0.6,mode=1,prob=0.8)
ops=[decode_op,resize_op,tochw_op,gridmask_op]
#图像路径
imgs_dir=“/imgdir/xxx.jpg”
fnames=os.listdir(imgs_dir)
forfinfnames:
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
img=img.transpose((1,2,0)) 结果如下图所示:
图像混叠
前文所述的图像变换与图像裁剪都是针对单幅图像进行的操作,而图像混叠是对两幅图像进行融合,生成一幅图像,Mixup和Cutmix两种方法的主要区别为混叠的方式不太一样。
07
Mixup
论文地址: https://arxiv.org/pdf/1710.09412.pdf Mixup是最先提出的图像混叠增广方案,其原理就是直接对两幅图的像素以一个随机的比例进行相加,不仅简单,而且方便实现,在图像分类和目标检测领域上都取得了不错的效果。为了便于实现,通常只对一个 batch 内的数据进行混叠,在Cutmix中也是如此。 如下是imaug中的实现,需要指出的是,下述实现会出现对同一幅进行相加的情况,也就是最终得到的图和原图一样,随着 batch-size 的增加这种情况出现的概率也会逐渐减小。 PaddleClas中Mixup的使用方法如下所示。 fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimporttransform
fromppcls.data.imaugimportMixupOperator
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#图像数据的重排
tochw_op=ToCHWImage()
#使用HideAndSeek图像增广方法
hide_and_seek_op=HideAndSeek()
#使用Mixup图像增广方法
mixup_op=MixupOperator()
ops=[decode_op,resize_op,tochw_op]
imgs_dir=“/imgdir/xxx.jpg”#图像路径
batch=[]
fnames=os.listdir(imgs_dir)
foridx,finenumerate(fnames):
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
batch.append((img,idx))#fakelabel
new_batch=mixup_op(batch) 混叠结果如下图所示。
08
Cutmix
论文地址:
https://arxiv.org/pdf/1905.04899v2.pdf
与 Mixup 直接对两幅图进行相加不一样,Cutmix 是从另一幅图中随机裁剪出一个 ROI(region of interest, 感兴趣区域),然后覆盖当前图像中对应的区域,代码实现如下所示: fromppcls.data.imaugimportDecodeImage
fromppcls.data.imaugimportResizeImage
fromppcls.data.imaugimportToCHWImage
fromppcls.data.imaugimporttransform
fromppcls.data.imaugimportCutmixOperator
size=224
#图像解码
decode_op=DecodeImage()
#图像随机裁剪
resize_op=ResizeImage(size=(size,size))
#图像数据的重排
tochw_op=ToCHWImage()
#使用HideAndSeek图像增广方法
hide_and_seek_op=HideAndSeek()
#使用Cutmix图像增广方法
cutmix_op=CutmixOperator()
ops=[decode_op,resize_op,tochw_op]
imgs_dir=“/imgdir/xxx.jpg”#图像路径
batch=[]
fnames=os.listdir(imgs_dir)
foridx,finenumerate(fnames):
data=open(os.path.join(imgs_dir,f)).read()
img=transform(data,ops)
batch.append((img,idx))#fakelabel
new_batch=cutmix_op(batch) 混叠结果如下图所示:
实验
经过实验验证,在ImageNet1k数据集上基于PaddleClas使用不同数据增广方式的分类精度如下所示,可见通过数据增广方式可以有效提升模型的准确率。
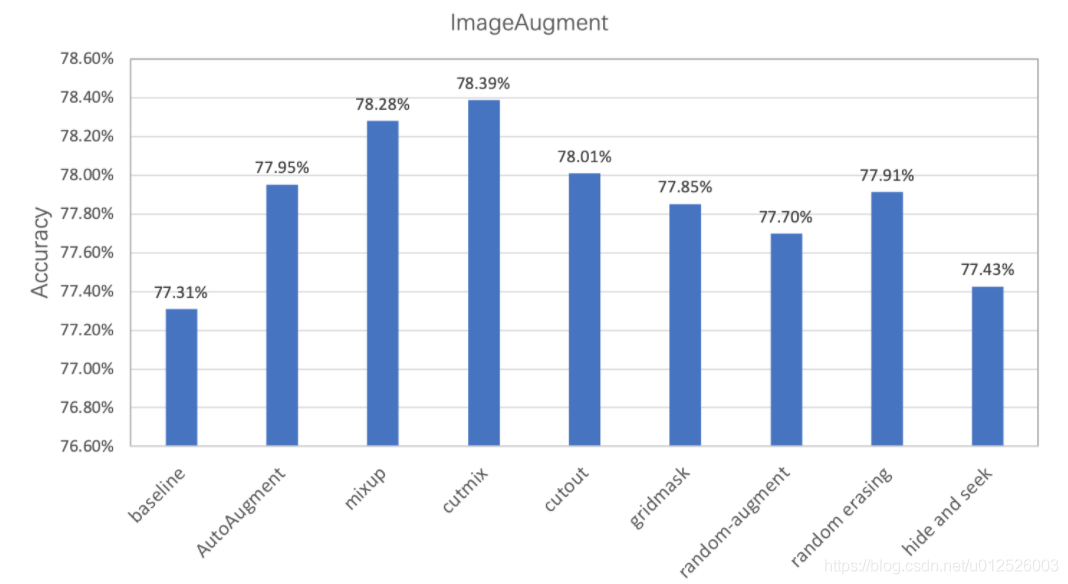
注意: 在这里的实验中,为了便于对比,将l2 decay固定设置为1e-4,在实际使用中,更小的l2 decay一般效果会更好。结合数据增广,将l2 decay由1e-4减小为7e-5均能带来至少0.3~0.5%的精度提升。
PaddleClas数据增广避坑
指南以及部分注意事项
最后再为大家介绍几个PaddleClas数据增广使用方面的小Trick。
在使用图像混叠类的数据处理时,需要将配置文件中的use_mix设置为True,另外由于图像混叠时需对label进行混叠,无法计算训练数据的准确率,所以在训练过程中没有打印训练准确率。
在使用数据增广后,由于训练数据更难,所以训练损失函数可能较大,训练集的准确率相对较低,但其拥有更好的泛化能力,所以验证集的准确率相对较高。
在使用数据增广后,模型可能会趋于欠拟合状态,建议可以适当的调小l2_decay的值来获得更高的验证集准确率。
几乎每一类图像增广均含有超参数,PaddleClas在这里只提供了基于ImageNet-1k的超参数,其他数据集需要用户自己调试超参数,当然如果对于超参数的含义不太清楚的话,可以阅读相关的论文,调试方法也可以参考训练技巧的章节
原文标题:干货 | 计算机视觉的数据增广技术大盘点!附涨点神器,已开源!
文章出处:【微信公众号:机器人创新生态】欢迎添加关注!文章转载请注明出处。
-
数据
+关注
关注
8文章
6511浏览量
87596 -
计算机视觉
+关注
关注
8文章
1600浏览量
45616
原文标题:干货 | 计算机视觉的数据增广技术大盘点!附涨点神器,已开源!
文章出处:【微信号:robotplaces,微信公众号:机器人创新生态】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
做FPGA向FX3写数据的过程中遇到了一些问题求解
M453VG6AE如何在ROM中存储一些自定义的数据?
往Aducm320 Flash中写入了一些数据,如何才能读出来?
redis的五种数据类型
机器视觉:图像配准方法分类
PostgreSQL中可用的各种数据类型
INT8量化常见问题的解决方案
M453VG6AE如何在ROM中存储一些自定义的数据?
cifar10数据集介绍 knn和svm的图像分类系统案例
荐读:FPGA设计经验之图像处理
8MIC-RPI-MX8是否需要在asound.conf中进行一些自定义配置?

PyTorch教程-4.2. 图像分类数据集






 工商网监
工商网监
评论