 自然语言处理——人工智能连接主义复兴浪潮中的下一个突破口
自然语言处理——人工智能连接主义复兴浪潮中的下一个突破口
AI 行业应用是一片新的大陆,深度学习作为新大陆的基石,经历了一轮又一轮突破。过去十年,在计算机视觉、语音识别、棋类 AI 等计算和感知智能技术上,深度学习率先取得成功。而最近深度学习在认知智能/自然语言处理上的进展,特别是 Transformer 衍生模型加上两阶段预训练语言模型范式的成功,正在将自然语言处理变成人工智能下一个最有可能的突破口。
计算机视觉与语音的成功是破茧成蝶,而非横空出世
2010 年到 2017 年,从 LeNet 到 AlexNet、Inception、VGGNet、ResNet 及其衍生结构,深度神经网络加上集成学习技术在计算机视觉研究中大放异彩,在 ImageNet 大规模深度视觉挑战(ILSVRC)图像分类任务上的错误率从 28.2% 一路降低到了 2% 左右。尽管这仍然是“实验室环境”下的结果,但当 AI 在某一个单点任务上的表现接近或者超越人类的时候,就会给行业带来巨大的商机。在视觉分类、检索、匹配、目标检测等各项任务上,随着相关算法越来越准确,业界也开始在大量商业场景中尝试这些技术。
人脸识别,作为计算机视觉技术取得突破的一个代表性应用,就是在这个大背景下从技术研究期进入成熟商业期,爆发成为一个千亿甚至万亿级别的市场。
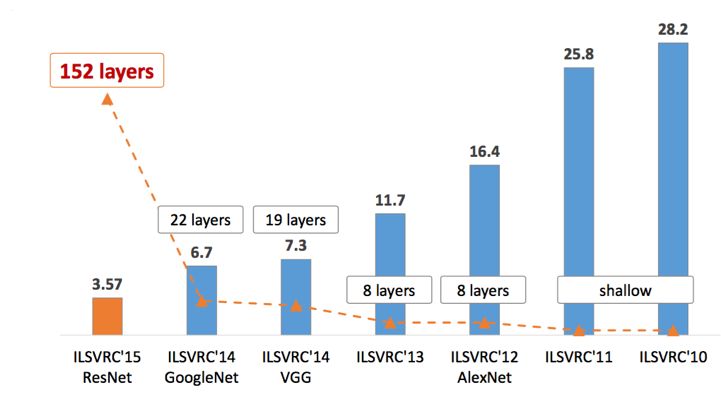
但在计算机视觉技术商业化的历程中,其实也有一段不短的蛰伏期。在深度卷积神经网络兴起之前,微软亚洲研究院研究人脸识别的团队曾在内部长期遭受质疑:做了十多年,准确率总是只有 70% 到 80%,看上去挺好玩,但这个准确率能有什么实际的应用价值呢?然而 2010 年深度学习浪潮迅速扫清了质疑,长期研究这个方向的被质疑者们,成了这个新商业领域的领导者,从火种涅槃成为满天繁星。而连接主义学派的忠实信徒、蛰伏近三十年的深度学习三剑客 Geoff Hinton、Yann LeCun 和 Yoshua Bengio,也是因为在统计机器学习盛行的数十年间受尽冷眼的厚积,才有了 2010 年后因 GPU 算力和神经网络模型不断加深而产生的薄发,从而一举获得图灵奖。
为什么自然语言处理领域的发展要相对滞后?
深度学习在计算机视觉、语音识别等感知智能技术上率先取得成功并不是偶然。深度学习秉承连接主义学派的范式,相较传统统计机器学习技术的最大进化在于其利用了高于统计方法数个数量级的参数和极其复杂的函数组合,通过引入各种非线性和多层级感知能力,构成了远强于统计机器学习模型的拟合能力。ResNet-152 的参数量已经达到六千万的级别,GPT-2.0 的参数量达到了惊人的 15 亿。而其他上亿甚至数亿级别的网络更是数不胜数。如此复杂的模型对数据的拟合能力达到了前所未有的水平,但是同时也极大提高了过拟合的风险。这对数据提出了极高的要求。训练数据的数量、维度、采样均衡度、单条数据本身的稠密度(非0、不稀疏的程度),都需要达到极高的水平,才能将过拟合现象降低到可控范围。
视觉信息(图像、视频)恰好是这样一类自然连续信号:一张图片通常就有数百万甚至上千万像素,而且每个像素上通常都有颜色,数据量大、数据的表示稠密、冗余度也高。往往在丢失大量直接视觉信号的情况下,人还能迅速理解图片的语义信息,就是因为自然连续信号,如图像中的场景和物体往往具有视觉、结构和语义上的共性。一个 30MB 的位图图片能被压缩到 2MB 而让人眼基本无法感知区别;一个 30MB 的 wave 音频文件被压缩到 3MB 的 MP3 还能基本保持主要旋律和听感,都是因为这类自然连续信号中存在大量不易被人的感官所感知的冗余。
视觉信息这种的丰富和冗余度,让深度神经网络得以从监督信号中一层层提炼、一层层感知,最终学会部分判断逻辑。深度神经网络在感知智能阶段中在视觉任务和语音任务上的成功,离不开视觉、语音信号自身的这种数据特点。
今天,属于感知智能的视觉和语音应用已经全面开花,但属于认知智能的自然语言处理却发展滞后。这种发展状态与自然语言处理技术中的数据特征也有密不可分的关系。
相对于图片、语音给出的直接信号,文字是一种高阶抽象离散信号。较之图片中的一个像素,文本中一个单元信息密度更大、冗余度更低,往往组成句子的每一个单词、加上单词出现的顺序,才能正确表达出完整的意思。如何利用单个文本元素(字/词)的意思,以及如何利用语句中的顺序信息,是近年来自然语言处理和文本分析技术的主要探索脉络。
2013 年,词的分布式向量表示(Distributed Representation)出现之前,如何在计算机中高效表示单个字/词是难以逾越的第一个坎。在只能用One-hot向量来表示字/词的年代,两个近义词的表示之间的关系却完全独立,语义相似度无法计算;上表示一个字/词所需的上万维向量中只有一个维度为1,其他维度都为0,稀疏度极高。面对这类信号,深度神经网络这类复杂的模型所擅长的化繁为简的抽象、提炼、总结能力便束手无策,因为输入信号已经极简到了连最基础的自我表示都难以做到。
NLP 中的两大重要挑战:特征表示、结构/语义理解正取得关键进展
而分布式词向量将语言的特征表示向前推进了一大步。分布式词向量提出了一个合理的假设:两个词的相似度,可以由他们在多个句子中各自的上下文的相似度去度量,而上下文相似的两个词会在向量空间中由两个接近的向量来表示。这种做法部分赋予了词向量“语义”,因此我们不必再让机器去查百科全书告诉我们“苹果”的近义词是“梨子”,而是直接从大量的互联网语料中去学习,原来“苹果”的近义词也可以是“三星”、“华为”。因为人们常常会说“我购买了一个苹果手机”,也常说“我购买了一个三星手机”,模型会敏锐的学习到“苹果”和“三星”在大量语料中出现时其上下文高度相似,因而认为两个词相似。分布式词向量让无语义、极稀疏的 One-hot 向量寿终正寝,而为大家提供了嵌入语义信息、稠密的特征表示,这才使得深度神经网络在自然语言处理和文本分析上的应用真正变得可能。
捕捉语句中在独立的词集合基础之上、词序列构成的句子结构信息也是自然语言处理和文本分析中的一个主要方向。传统条件随机场(CRF)考虑了前后相邻元素和当前元素之间的依赖;长短时记忆网络模型(LSTM)以一种衰减形式考虑了当前元素之前的元素序列;seq2seq 通过注意力和编解码的机制使得解码时的当前元素不光能用上已经解码完毕的元素序列,还能用上编码前的序列的完整信息;近期各类基于 Transformer 结构,如 ELMo 、BERT、GPT-2.0、XLNet,则利用两阶段(基于自编码的预训练加基于任务的调优)模式,能够以自监督的方式更好地利用大规模的无标注语料训练不同句子结构中词语之间的关系,并且突破传统线性序列结构中存在的难以建立长距离、双向依赖关系的问题,学习到质量更高的中间语言模型,再通过调优就能在文本生成、阅读理解、文本分类、信息检索、序列标注等多个任务上取得当前最为领先的准确率。
以机器阅读理解任务为例,在 SQuAD1.0 数据集上,BERT 和 XLNet 都已大幅超越人类的 91.22(F1分),分别达到了 93.16 和 95.08;在更加复杂的 SQuAD2.0 数据集上,XLNet 也已经达到了 89.13。
又如在 2019 年 3 月举行的第十四届 NTCIR 上,短文本情感对话任务(STC3)提出的要求是:中文回答不仅需要内容合理,语句流畅,而且需要情感合宜。例如,如果用户说“我的猫昨天去世了”,如果机器人想表达悲伤的情感,那么最合适的回答可能是“这太悲伤了,很抱歉听到”,但如果想表达安慰的情感,则应该说 “坏事永远发生,我希望你会快乐”。对情感表达要求的增加,无疑增加了难度。
而在这个比赛中,一览群智和人民大学信息学院联合组成的团队获得了冠军,其使用的方法便是基于 Transformer 改进的网络模型,以情感识别、情感领域对话子模型、集成学习等方法相结合,击败了十几支强劲对手。类似的探索,让 AI 在特定任务下的认知能力,朝着人类水平一步步发展。
认知智能进入快车道
自然语言处理领域的发展虽然比计算机视觉和语音领域滞后几年,但是我们看到自然语言处理已经进入快车道。近两年来语言模型上的飞速进步,让我们感受到之前制约自然语言处理和文本分析发展的主要难点,正在被更好的模型结构、训练和使用方法、更大的算力逐渐克服。为自然语言任务加入“常识”,也是另一个新兴重要探索方向,这个方向则与知识图谱技术紧密结合。
我们正处于认知智能的黄金发展期,新技术的出现与逐步成熟,使得更多行业的应用场景变得可能。一览群智一直在探索认知智能的基础技术发展与前沿行业应用,围绕自然语言处理技术的变与不变,在这个过程中有着自己的思考和总结,并且通过智语这个核心技术产品,给出自己的答案。就像 BERT、GPT-2.0、XLNet 在两阶段范式上的殊途同归,我们也认为基础语言模型在不同任务上可以存在一些不变性,但在不同场景中一定要做特殊语料与任务下的调优与适配。出于对文本信号特性的理解和自然语言处理技术发展阶段的认识,我们构建认知智能核心产品智语平台的思路,也是围绕这种变与不变在展开。
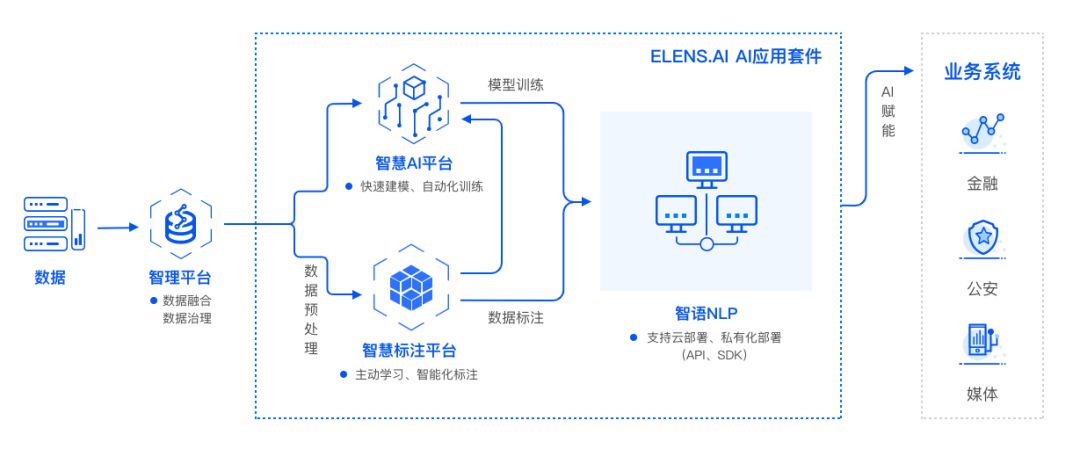
“智语” 自然语言处理平台的智能流程
但认知智能在金融、公安、媒体等场景中的变化部分给 AI 厂商带来的挑战非常明显。一个算法往往在不同场景下要利用不同的标注语料去形成不同的模型,一个媒体场景的 10 类新闻分类模型,无法给另一个媒体的 12 类分类体系使用。
为了解决数据标注难、封闭环境下模型训练难、部署难等问题,一览群智的智语平台提供了标注管理、智能标注加速、自然语言处理、文本模型训练、一键部署等端到端功能,提升了团队在应对不同场景时的效率与效果。例如智能标注加速功能,利用主动学习的先进技术,将训练一个分类或者序列标注模型的标注量有效降低至原有的 30%-50%,同时保证模型性能基本不变;加上平台高效能的标注管理,总体效率提升可达数倍。而傻瓜式的训练和部署,使得初级团队成员通过短期培训也能有效形成 AI 的生产力。
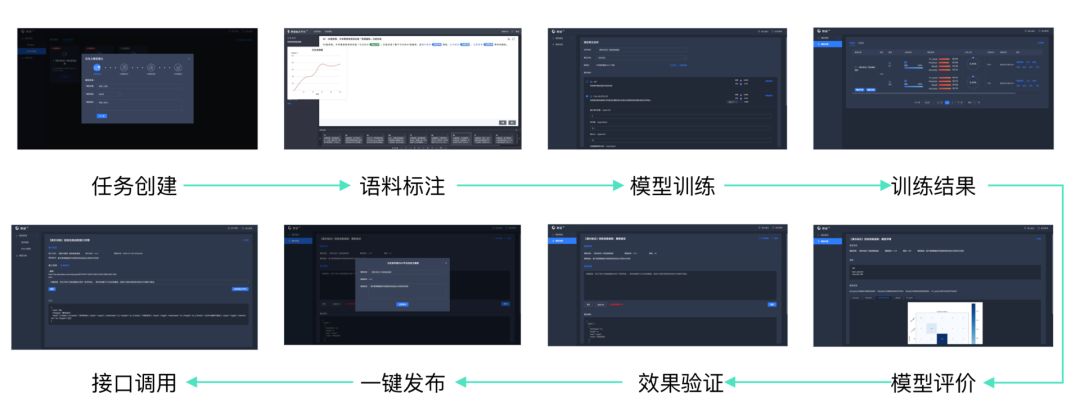
“智语” 自然语言处理平台端到端流程方案
结语
回顾 AI 连接主义学派复兴的十年,就像一个螺旋梯,算法与算力应用相互促进、不断攀升。在见证 ImageNet 图像分类错误率从 30% 一路降低到 2%左右;见证 AlphaGo 击败樊辉、李世石、柯洁之后,我们开始见证基于 BERT/GPT-2.0/XLNet 在阅读理解任务超越人类。十年后再回顾,会发现今天之于自然语言处理,也许恰如 2014 年之于人脸识别。
-
人工智能
+关注
关注
1776文章
43837浏览量
230589 -
计算机视觉
+关注
关注
8文章
1599浏览量
45613
原文标题:从发展滞后到不断突破,NLP已成为AI又一燃爆点?
文章出处:【微信号:iawbs2016,微信公众号:宽禁带半导体技术创新联盟】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
自然语言处理的研究内容
2023年科技圈热词“大语言模型”,与自然语言处理有何关系
国内MES的突破口
自然语言处理和人工智能的区别
自然语言处理和人工智能的概念及发展史 自然语言处理和人工智能的区别
自然语言处理的概念和应用 自然语言处理属于人工智能吗
自然语言处理的优缺点有哪些 自然语言处理包括哪些内容
人工智能及其应用总结
人工智能有哪些领域
自然语言处理包括哪些内容 自然语言处理技术包括哪些






 工商网监
工商网监
评论