 大数据和AI以及存储芯片的未来
大数据和AI以及存储芯片的未来
作为ICT的从业人员,大家都知道有两个公司是有点臭名昭著,因为他们和SUN Micro公司不一样,好IT公司养工程师,“坏”公司养律师。Qualcomm和Oracle都是以律师而著名。最近特别是Oracle,更加不养中国的工程师了。
在memory界,也有一个公司有类似的名气,那就是Rambus。在2019年的Memory+的会议上,他们居然吃了豹子胆,给自己挖了一个深深的坑,《Big Data, AI and the future of Memory》。对于AI来讲,目前从应用,到框架,再到底层语言和硬件,这是一个百家争鸣的时代。Nvidia在巩固了自己在训练上的地位之后,向推理进攻,各家初创公司在利用开源框架,占领推理市场,并伺机向训练进攻。[1]
因此,对于任何一种神经网络来讲,实现对于资源的需求的影响还是比较大的,一个神经网络在不同的框架(Caffe/Pytroch/TensorFlow)上,在不同的硬件平台上(CPU/GPU/FPGA/ASIC)的需求都多多少少不同。更不要讲有成千上万的AI炼丹师在各种调参,生成各种定制的网络,因此Rambus这种行为和我今天一样都是一种“无知者无畏”的行动。
从2015年的Resnet之后,大家都认为在神经网络的深度学习方面,特别是标杆性的ImageNet的上,大家没有太明显的进展了。[2]
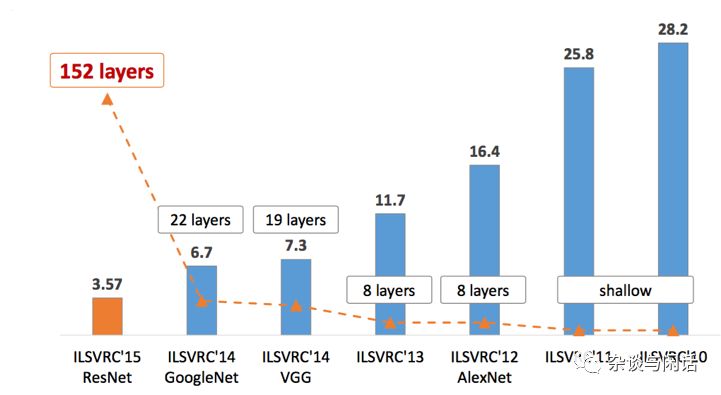
因此从2012年以来的ImageNet优胜网络模型来看,大家的趋势很明显,Top-5的错误率逐年下降,网络的层数也越来越厚。当然还有就是网络的parameter,也就是weight和bias 也越来越多。
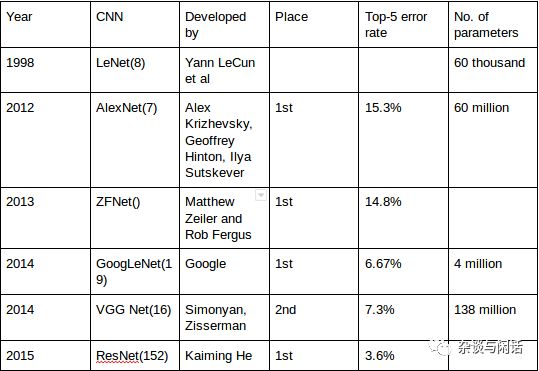
计算和I/O是目前占主导地位的冯氏体系的核心,和之前在2018年流行的争论一样,“深度学习的进步是(看上图,YannLeCun的10位数识别是1998)因为算法的进步,还是算力的进步”,计算和I/O的那个作用大也是一个“鸡蛋问题”。
很有意思的是,很多东西抛开现象看本质会有一个别样的视角。举个上周学习到观点,对于数据库领域来讲,目前workload就是OLTP和OLAP。OLTP的交易的本质就是数据的I/O,对!就是把你的软妹币从你口袋中搬运到淘宝卖家的口袋中去。OLAP的本质就是计算,在知道你买了尿布,奶粉之后算出来应该给你推送婴儿车的广告。
那对于目前比较流行的深度学习来讲,也可以从同样的话来总结。基于卷积计算的CNN,他的本质就是计算,也算出你到底有多少个预先训练好的元素,这些元素包含形状,颜色等等。比如,如果你有一个嘴巴,两个眼睛,和一个鼻子,那就是一个人脸。
还有一种是RNN,RNN的本质也是计算和I/O,和CNN的计算上线文无关,RNN的具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中。当初,Google不顾版权协会的反对,数字化人类的书籍,本质上就是理解大家的语言。比如在天朝,如果有一个名词,开始是“历害”,大家肯定知道下一个就是“国”了。
因此,不过CNN和RNN,大家都是需要参数了,也就是“Weights” 和“Bias” 。两者对于这些参数的share的方式也很大不同。
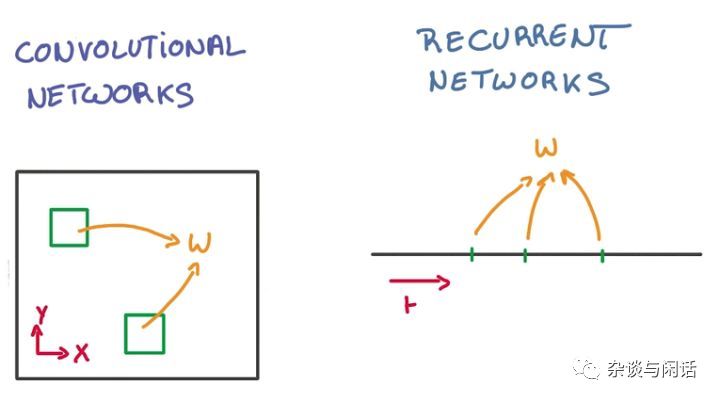
CNN是在空间上共享,RNN在时间上共享。因此,问题就来了,这些参数是怎么出来的呢?他们的大小和性能的要求是多少呢?
先来讲对于大小的要求。这里就要从最基本的CNN网络 Alexnet说起。
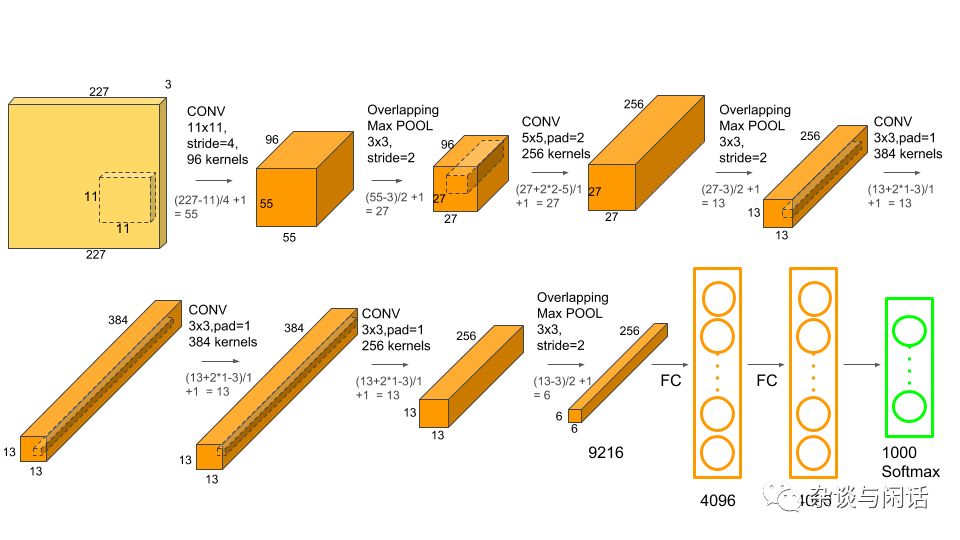
仔细介绍每一层的东西:(对于stride 和padding不熟的,请看CS231n,不知道CS231n的,请打赏,并到此为止)
input:彩色的图片 227X227X3
Conv-1:第一层的卷积有96个kernel。kernel的大小是11X11,卷积的stride是4,padding是0
MaxPool-1 :第一层卷积的最大值。Pooling的size是3X3,stride是2
Conv-2:256个kernel,kernel的size是5X5,stride是1,padding是2.
MaxPool-2:第二层卷积的最大值,Pooling是3X3, stride是2
Conv-3: 384个kernel。kernel大小是3X3, stride是1 ,padding是1.
Conv-4:和第三层类似。384 个kernel。3X3,strdie和padding是1.
Conv-5:256个kernel。kernel size 3X3,stride和padding是1.
MaxPool-3:第五层卷积的最大值,Pooling是3X3, stride是2
FC-1:第一个全连接层,有4096个神经元
FC-2:第二个全连接,有4096个神经元
FC-3: 第三个全连接层,有1000个神经元
对于CNN来讲,上一层的输出是这一层的输入。因此需要把每一层的输出算清楚。从上面看,每一层的网络类型有Input,Conv,Maxpool和FC四类,因此下面的计算也是按四类开始的。
O=(I-K+2P)/S+1
其中:O是输出的宽度,I是输入的宽度,K是Kernel的宽度,N是Kernel的数量,S是stride, P是Padding。N是kernel的数量。
因此,输出的image的size就是OXOXN
Output的规模的计算:
Conv 层的计算:定义如下:
作死用中文解释一下,就是一个227X277的图上,我用11X11的小方案从左到右,从上到小描红一边。这个描红,这个11X11小框子每次跳4格,如果跳到边上没对齐的话,我用多一行的0来补齐。因此227X227X3的第一层卷积的输出就是:(227-11+2X0)/4+1=55. image size=55X55X96
MaxPool 的计算:定义如下:
O=(I-ps)/S+1
其中:O是输出的宽度,I是输入的宽度, S是stride,ps是Pool size
因此,对于第一层卷积的Maxpooling就是(55-3)/2+1=27 , image就是27X27X96
FC的计算:一个全连接层的输出就是一个向量,这个向量的单元数是它神经元的数量。比如FC-1就是一个4096的向量。
因此,对于一个包含227X227X3的图片,它的历程如下:
一开始是227X227X3,过了第一层卷积,就是55X55X96, 之后的MaxPool就是27X27X96. 第二次卷积之后是27X27X256,之后的MaxPooling就是 13X13X256,第三层卷积是13X13X384,之后的第4和5 卷积变成:27X27X256,第3个Maxpooling 变成 6X6X256,之后的FC-1就是4096X1,FC-2不变,最后就是一个1000X1 的向量了。
-
神经网络
+关注
关注
42文章
4572浏览量
98743 -
大数据
+关注
关注
64文章
8649浏览量
136587
原文标题:大数据、AI和存储芯片的未来
文章出处:【微信号:SSDFans,微信公众号:SSDFans】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
半导体芯片研究:中国存储芯片行业概览
什么是SD NAND存储芯片?
什么是SD NAND存储芯片?

存储芯片市场价格止跌 AI芯片需求推动先进工艺发展
三星:存储芯片需求回暖!
存储芯片减产,AI芯片暴增!
芯存远见!康芯威诚邀您参加探索存储芯片新机遇交流沙龙

存储芯片是什么 存储芯片的分类及发展历史
存储芯片的转机,藏在汽车应用里





 工商网监
工商网监
评论