 一个能通过空间条件坐标和隐变量生成图像片、并合成完整图片的网络模型
一个能通过空间条件坐标和隐变量生成图像片、并合成完整图片的网络模型
我们人类有着丰富的生活经验和生物直觉,可以在只看到物体的一部分时就能在大脑中补全整个对象的全貌,也可以通过几次对于目标的部分观测“拼接”出物体的全貌。人类的这种能力源于我们对于空间坐标的深入理解和把握,可以将不同区域的观测放置到相应的位置上以识别整体环境。但目前大部分的计算机视觉系统都是以整张图片作为输入,随后利用下采样和特征抽取来实现一系列视觉任务。但这种方式限制了算法对于大场景高像素图像的处理。我们不禁要问:“计算机是不是也可以像人类一样由局部到整体的理解图像呢?我们能不能训练出一个生成模型,可以利用坐标信息生成局域图像并组合成连续的全局图像呢?”
带着这个问题,研究人员们对生成对抗网络进行了深入地探索。典型的GAN通常是将隐空间的分布映射到真实数据空间中去。为了从部分图片生成高质量的图像,研究人员在图像中引入了坐标系统的概念,并将图像生成分解为一系列并行的子过程。最后得到一个能通过空间条件坐标和隐变量生成图像片、并合成完整图片的网络模型。
这一名为条件坐标生成对抗网络(COnditional COordinate GAN ,COCO-GAN)的模型目标是学习出一个与隐空间分布流型正交的坐标流型。对隐空间采样后,生成器以每个空间坐标为条件在每个对应位置生成图像片。与此同时判别器则学会判断相邻图像片的结构是否合理,在视觉上是否匀称、在边缘处是否连续。
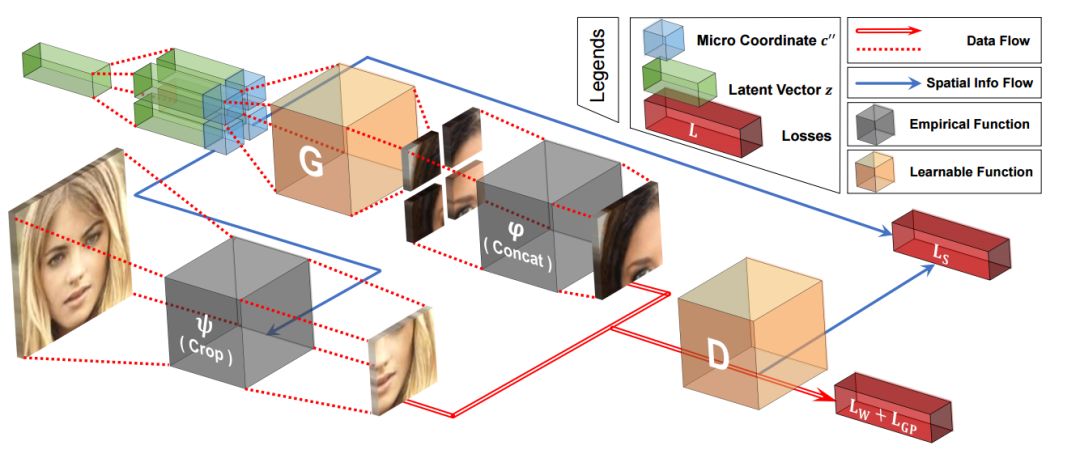
上图中我们可以看到COCO-GAN的训练架构,最坐标绿色的隐变量复制后分别与不同的坐标表达衔接,随后送入生成器中生成微图像片。而后将多个不同的像素片进行拼接得到宏图像片。而判别器测复杂分辨真实的和生成的宏图像片,并在右上角的分支中辅助预测宏图像片的空间坐标。而完整的图像则会在测试阶段生成。
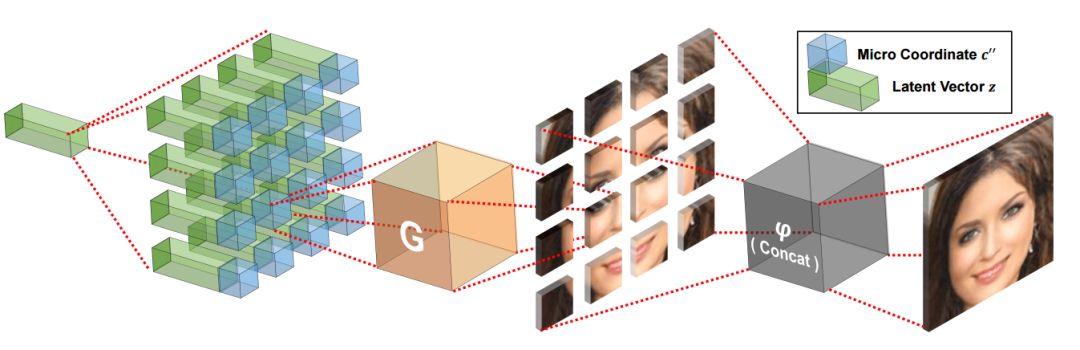
在测试时,生成的微图像片直接拼接成最后的图像输出。
具体实现
在前文的架构图中我们已经看到它由生成器和判别器两个网络和两套坐标系统组成,其中包括了细粒度的局域图像片坐标系统和粗粒度的宏图像片坐标系统。整个过程中包含了三种图像,整幅图、宏图像片层、微图像片层构成。其中生成器主要基于空间条件,从隐变量中生成出维图像片,并将多个图像片拼接生成高质量的输出。并通过判别器对于宏图像片的判断来指导生成器对于图像片的生成。最终生成器的损失包含了空间连续性损失和Wasserstein损失,而判别器还增加了一项梯度惩罚损失。
生成器和判别器其都是基于残差块和卷积实现的。
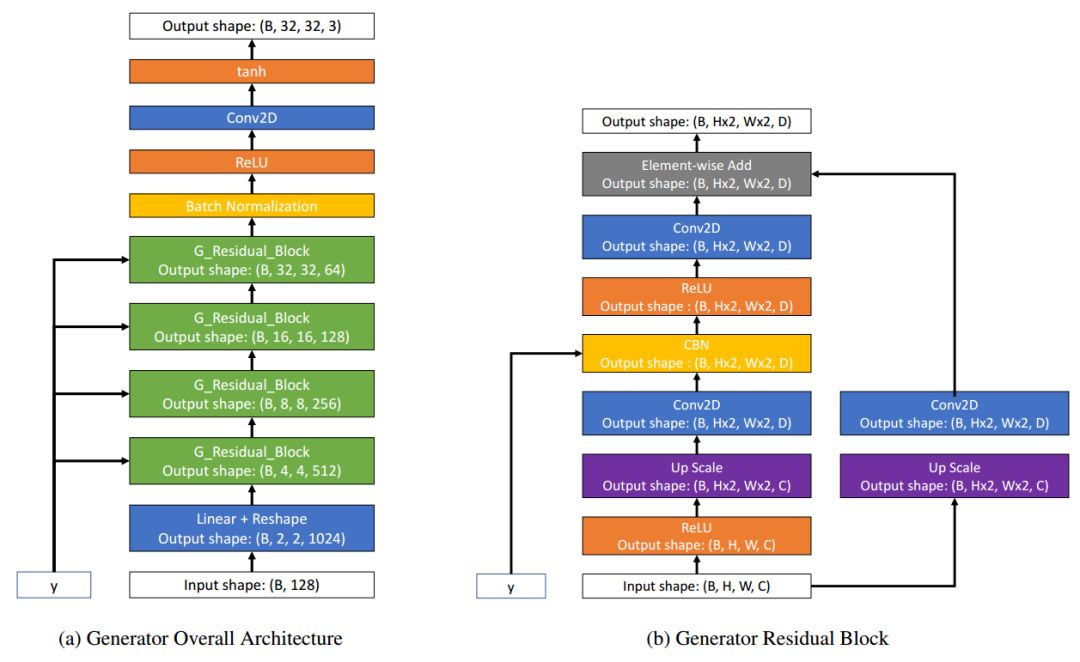
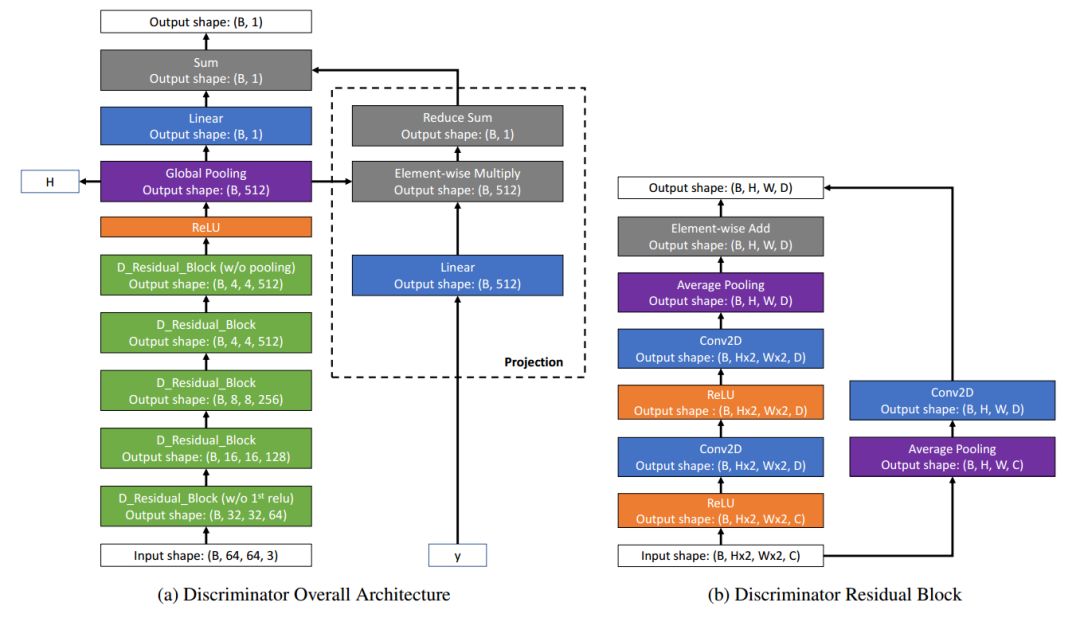
生成器和判别器的架构
基于这样的损失,生成器生成的每个图像片边缘会变得更加平滑,基于空间坐标生成更为连续的结果。下图是一些网络得到的结果。这些全局连续平滑的图像直接由网络输出,其中最顶一行是完整的图像,中间一行是宏图像片,而最下一行是生成器得到的为图像片。每一列(同一个图像)都是利用同一个隐变量得到的结果。由于大小不均,所以排列有些错位。我们用不同颜色的箭头分别标出。
研究人员基于这一网络模型还进行了一系列实验,都达到了十分优秀的结果。研究人员在CelebA和LSUN上分别将原始图像分成2*2个宏图像片,将每个宏图像片分成了2*2个微图像片,每个微图像片由32*32个像素组成,这样的配置记为:(N2,M2,S32)。下图展示了不同配置的效果,宏图像片可以由不同大小的微图像片构成。
我们可以看到在不同像素配置下的微图像片都可以生成较为完整的图像。
甚至达到4*4时(N16,M16,S4)生成的图像还比较合理。将1024个独立图像片进行拼接同样可以保持输出人脸的连续性。
空间连续性
为了更好地研究空间连续性,研究人员还进行了两项插值实验,分别是全图插值和坐标插值。
在全图插值中,研究人员随即的从隐空间中选取两个隐变量,在两个隐变量之间的差值隐变量可以生成连续的全图。在这一过程中所有的微图像片都在同时改变以适应隐变量的变化。
在坐标插值的实验中,利用固定的隐变量在空间坐标从[-1,1]区间变化的过程中生成微图像片,在下图中可以看到空间连续性在微图像片中依然表现良好。一个有趣的现象是模型没有真正的学习到眉间的结构,而是通过对左右眼直接变形来实现左眼到右眼的变化,这说明模型没有真正的理解场景背后的内在联系。
由于这一网络学习到了图像片的坐标流型,在坐标条件下进行外插生成器可以生成超过原始图像大小的结果。基于256*256训练的模型可以得到384*384的生成图像,实现超越原始图像边界的生成,并且生成的都是新的样本。下图中红色框外的是外插的结果,提高了原有图像的分辨率。
随后,研究人员还探索了如何利用这种方法生成全景图像、如何利用局部信息并行化地生成整体图像、实现图像片引导的生成。
COCO-GAN从新的角度揭示了GAN在条件坐标下的强大生成能力,不仅拓展了GAN的生成能力同时并行化的处理和分治设计十分适用于计算受限设备的使用。相信COCO-GAN将为为GAN的研究带来更宽广的视野!
-
图像
+关注
关注
2文章
1063浏览量
40041 -
生成器
+关注
关注
7文章
302浏览量
20211 -
计算机视觉
+关注
关注
8文章
1600浏览量
45615
原文标题:国立清华与谷歌AI联合提出新型生成模型COCO-GAN,让计算机像人类一样由局部到整体理解图像
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
xilinx系统生成器错误:无法打开文件进行读取:vsionsources.mdl
基于改进空间约束贝叶斯网络模型的图像分割
探讨条件GAN在图像生成中的应用
条件生成对抗模型生成数字图片的教程


基于生成式对抗网络的端到端图像去雾模型

基于自注意力机制的条件生成对抗网络模型





 工商网监
工商网监
评论