 神经网络发展的重要性
神经网络发展的重要性
摘要:任何人工智能的难题都可以被解决。唯一能证明这一论断成立的是这样一个事实:自然界通过进化已经解决了这些难题。但在20世纪50年代就已经存在各种暗示,如果AI研究者能够选择完全不同于符号处理的方式,计算机会如何表现出智能行为。
第一条暗示是,我们的大脑是强大的模式识别器。我们的视觉系统可以在1/10秒内识别混乱场景中的对象,即使我们可能从未见过那个特定的对象,也不论该对象在什么位置,多大尺寸,以什么角度面对我们。简而言之,我们的视觉系统就像一台以“识别对象”作为单一指令的计算机。
第二条暗示是,我们的大脑可以通过练习来学会如何执行若干艰巨的任务,比如弹钢琴、掌握物理学知识。大自然使用通用的学习方法来解决特殊的问题,而人类则是顶尖的学习者。这是我们的特殊能力。我们大脑皮层的结构整体上是相似的,并且我们所有的感受系统和运动系统都有深度学习网络。
第三条暗示是,我们的大脑并没有充斥着逻辑或规则。当然,我们可以学习逻辑思维或遵守规则,但必须要经过大量的训练,而我们当中的大多数人对此并不在行。这一点可以通过人们在一个叫作“华生选择任务”(Wason selection task)的逻辑谜题上的典型表现来进行说明(见图3–1)。
图3–1
图3-1这四张卡片,每张都是一面有数字,另一面涂满了颜色。要测试以下命题为真:一张卡片在一面显示为偶数,那它的另一面就是红色的。你需要翻哪(几)张牌呢?图片来源:“华生选择任务”,维基百科。
正确的选择是正面为数字“8”,背面为棕色的卡片。在最初的研究中,只有10%的受试者给出了正确的答案。但是,当给这项逻辑测试加上了熟悉的背景信息时,大多数受试者都能很快找出正确答案(见图3–2)。
图3–2
推理似乎是基于特定领域的,我们对该领域越熟悉,就越容易解决其中的问题。经验使得在一个领域内进行推理变得更容易,因为我们可以用已有的例子来下意识地得到解决方案。例如,在物理学中,我们通过解决各种问题,而不是通过背诵公式,来学习电磁学领域的知识。如果人类的智能是完全基于逻辑的,那么它应该是跨领域的通用智能,但事实并非如此。
图3-2每张卡片都是一面有一个年龄数字,另一面印着一种饮料。需要翻哪(几)张牌才能检验这条法律:如果你正在喝酒,那说明你一定超过18岁了?图片来源:“华生选择任务”,维基百科。
第四条暗示是,我们的大脑充满了数百亿个小小的神经元,每时每刻都在互相传递信息。这表明,要解决人工智能中的难题,我们应该研究具有大规模并行体系结构的计算机,而不是那些具有冯·诺依曼数字体系结构,每次只能获取和执行一个数据或指令的计算机。是的,图灵机在被给予足够内存和时间的条件下,的确可以计算任何可计算的函数,但自然界必须实时解决问题。要做到这一点,它利用了大脑的神经网络,就像地球上最强大的计算机一样,它们具有大量的并行处理器。只有能有效运行的算法,最终才能在自然选择中胜出。
深度学习的起点
20世纪五六十年代,在诺伯特·维纳(Norbert Wiener)提出基于机器和生物中的通信和控制系统的控制论之后不久,学界对自组织系统开始产生了浓厚的兴趣。而其中一个独创性产物便是由奥利弗·塞弗里奇(Oliver Selfridge) 创造的Pandemonium(鬼域)。这是一个图案识别设备,其中进行特征检测的“恶魔”通过互相竞争,来争取代表图像中对象的权利(深度学习的隐喻,见图3–3)。斯坦福大学的伯纳德·威德罗(Bernard Widrow)和他的学生泰德·霍夫(Ted Hoff)发明了LMS(最小均方)学习算法,它与其后继算法一起被广泛用于自适应信号处理,例如噪声消除、财务预测等应用。在这里, 我将重点关注一位先驱弗兰克·罗森布拉特(Frank Rosenblatt)(图3–4),他发明的感知器是深度学习的前身。
图3-3 Pandemonium。奥利弗·塞弗里奇认为,大脑中有恶魔负责从感官输入中先后提取更复杂的特征和抽象概念,从而做出决定。如果每个级别的恶魔与前一个级别的输入相匹配,则会激动不已。做决定的恶魔需要衡量所有信息传递者的兴奋程度和重要性。这种形式的证据评估是对当前多层次深度学习网络的隐喻。图片来源:Peter H. Lindsay and Donald A. Norman, Human Information Processing: An Introduction to Psychology, 2nded. (New York: Academic Press, 1977),图3-1。维基共享资源:https://commons.wikimedia.org/wiki/File:Pande.jpg。
图3-4深思中的康奈尔大学教授弗兰克·罗森布拉特,他发明了感知器。作为深度学习网络的早期雏形,感知器是能够将图像进行分类的简易学习算法。图中文章是1958年7月8日在《纽约时报》上发表的一篇来自合众国际社(UPI)的报道。感知器在1959年完成时预计花费了10万美元,相当于今天的100万美元。IBM 704计算机在1958年价值200万美元,相当于现在的2000万美元,可以实现每秒12000次的乘法运算,这在当时已经是极快的速度了。不过相比之下,现在价格要低得多的三星Galaxy S 6手机每秒可以执行340亿次操作,速度要快100万倍以上。图片来源:George Nagy。
从样本中学习
尽管我们对大脑功能缺乏足够的了解,但神经网络的AI先驱们依然依靠着神经元的绘图以及它们相互连接的方式,进行着艰难的摸索。康奈尔大学的弗兰克·罗森布拉特是最早模仿人体自动图案识别视觉系统架构的人之一。他发明了一种看似简单的网络感知器(perceptron),这种学习算法可以学习如何将图案进行分类,例如识别字母表中的不同字母。算法是为了实现特定目标而按步骤执行的过程,就像烘焙蛋糕的食谱一样。
如果你了解了感知器如何学习图案识别的基本原则,那么你在理解深度学习工作原理的路上已经成功了一半。感知器的目标是确定输入的图案是否属于图像中的某一类别(比如猫)。方框3.1解释了感知器的输入如何通过一组权重,来实现输入单元到输出单元的转换。权重是对每一次输入对输出单元做出的最终决定所产生影响的度量,但是我们如何找到一组可以将输入进行正确分类的权重呢?
工程师解决这个问题的传统方法,是根据分析或特定程序来手动设定权重。这需要耗费大量人力,而且往往依赖于直觉和工程方法。另一种方法则是使用一种从样本中学习的自动过程,和我们认识世界上的对象的方法一样。需要很多样本来训练感知器,包括不属于该类别的反面样本,特别是和目标特征相似的,例如,如果识别目标是猫,那么狗就是一个相似的反面样本。这些样本被逐个传递给感知器,如果出现分类错误,算法就会自动对权重进行校正。
这种感知器学习算法的美妙之处在于,如果已经存在这样一组权重,并且有足够数量的样本,那么它肯定能自动地找到一组合适的权重。在提供了训练集中的每个样本,并且将输出与正确答案进行比较后,感知器会进行递进式的学习。如果答案是正确的,那么权重就不会发生变化。但如果答案不正确(0被误判成了1,或1被误判成了0),权重就会被略微调整,以便下一次收到相同的输入时,它会更接近正确答案(见方框3.1)。这种渐进的变化很重要,这样一来,权重就能接收来自所有训练样本的影响,而不仅仅是最后一个。
如果对感知器学习的这种解释还不够清楚,我们还可以通过另一种更简洁的几何方法,来理解感知器如何学习对输入进行分类。对于只有两个输入单元的特殊情况,可以在二维图上用点来表示输入样本。每个输入都是图中的一个点,而网络中的两个权重则确定了一条直线。感知器学习的目标是移动这条线,以便清楚地区分正负样本(见图3–5)。对于有三个输入单元的情况,输入空间是三维的,感知器会指定一个平面来分隔正负训练样本。在一般的情况下,即使输入空间的维度可能相当高且无法可视化,同样的原则依然成立。
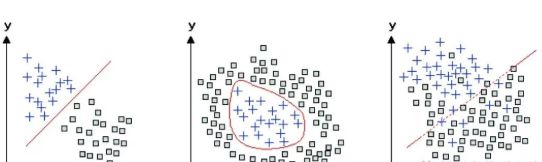
图3-5关于感知器如何区分两个对象类别的几何解释。这些对象有两个特征,例如尺寸和亮度,它们依据各自的坐标值(x,y)被绘制在每张图上。左边图中的两种对象(加号和正方形)可以通过它们之间的直线分隔开;感知器能够学习如何进行这种区分。其他两个图中的两种对象不能用直线隔开,但在中间的图中,两种对象可以用曲线分开。而右侧图中的对象必须舍弃一些样本才能分隔成两种类型。如果有足够的训练数据,深度学习网络就能够学习如何对这三个图中的类型进行区分。
最终,如果解决方案是可行的,权重将不再变化,这意味着感知器已经正确地将训练集中的所有样本进行了分类。但是,在所谓的“过度拟合”(overfitting)中,也可能没有足够的样本,网络仅仅记住了特定的样本,而不能将结论推广到新的样本。为了避免过度拟合,关键是要有另一套样本,称为“测试集”(test set),它没有被用于训练网络。训练结束时,在测试集上的分类表现,就是对感知器是否能够推广到类别未知的新样本的真实度量。泛化(generalization)是这里的关键概念。在现实生活中,我们几乎不会在同样的视角看到同一个对象,或者反复遇到同样的场景,但如果我们能够将以前的经验泛化到新的视角或场景中, 我们就可以处理更多现实世界的问题。
利用感知机区分性别
举一个用感知器解决现实世界问题的例子。想想如果去掉头发、首饰和第二性征,比如男性比女性更为突起的喉结,该如何区分男性和女性的面部。比阿特丽斯·哥伦布(Beatrice Golomb)是1990年我实验室里的一名博士后研究员,她利用一个数据库中的大学生面部照片作为感知器的输入,经过训练的感知器能以81%的准确度对面部的性别进行分类(见图3–6)。而对于感知器难以分类的面部,人类也同样很难做出区分。我实验室的成员在同一组人的面部识别上达到了88%的平均准确度。比阿特丽斯还训练了多层感知器,其准确度达到了92%,9比我实验室的成员还要准确。她在1991年的NIPS大会上发表的演讲中总结道:“经验可以提高性能,这表明实验室的研究人员需要花更多时间来进行性别鉴定的工作。”她把她的多层感知器叫作“SEXNET”(性别网络)。在问答环节,有人问是否可以使用SEXNET来检测异装癖者的面孔。“可以。”比阿特丽斯这样回答。而NIPS大会的创始人爱德华·波斯纳(Edward Posner)辩驳道:“那就应该叫DRAGNET(法网)。”
图3-6这张脸属于男性还是女性?人们通过训练感知器来辨别男性和女性的面孔。来自面部图像(上图)的像素乘以相应的权重(下图),并将该乘积的总和与阈值进行比较。每个权重的大小被描绘为不同颜色像素的面积。正值的权重(白色)表现为男性,负值的权重(黑色)倾向于女性。鼻子宽度,鼻子和嘴之间区域的大小,以及眼睛区域周围的图像强度对于区分男性很重要,而嘴和颧骨周围的图像强度对于区分女性更重要。图片来源:M. S. Gray,D. T. Lawrence,B. A. Golomband T.J.Sejnowski,“A Perceptron Reveals the Face of Sex,” Neural Computation 7 ( 1995 ):1160 - 1164,图1。
区分男性与女性面部的工作有趣的一点是,虽然我们很擅长做这种区分,却无法确切地表述男女面部之间的差异。由于没有单一特征是决定性的,因此这种模式识别问题要依赖于将大量低级特征的证据结合起来。感知器的优点在于,权重提供了对性别区分最有帮助的面部的线索。令人惊讶的是,人中(即鼻子和嘴唇之间的部分)是最显著的特征,大多数男性人中的面积更大。眼睛周围的区域(男性较大)和上颊(女性较大)对于性别分类也有着很高的信息价值。感知器会权衡来自所有这些位置的证据来做出决定,我们也是这样来做判定的, 尽管我们可能无法描述出到底是怎么做到的。
1957年罗森布拉特对“感知器收敛定理”的证明是一个突破,他的演示令人印象深刻。在美国海军研究办公室(Office of Naval Research)的支持下,他搭建了一个以400个光电单元作为输入的定制硬件模拟计算机,其权重是由电机调整的可变电阻电位器。模拟信号随着时间连续变化,就像黑胶唱片中的信号一样。用一组图片集(其中部分图片中有坦克,另外一部分则没有)进行训练,罗森布拉特的感知器即使在新图像中也能准确识别坦克。这一成果经《纽约时报》报道后引起了轰动(见图3–4)。
感知器激发了对高维空间中模式分离的美妙的数学分析。当那些点存在于有数千个维度的空间中时,我们就无法依赖在生活的三维空间里对点和点之间距离的直觉。俄罗斯数学家弗拉基米尔·瓦普尼克(Vladimir Vapnik)在这种分析的基础上引入了一个分类器, 称为“支持向量机”(Support Vector Machine),它将感知器泛化,并被大量用于机器学习。他找到了一种自动寻找平面的方法,能够最大限度地将两个类别的点分开(见图3–5,线性)。这让泛化对空间中数据点的测量误差容忍度更大,再结合作为非线性扩充的“内核技巧”(kernel trick),支持向量机算法就成了机器学习中的重要支柱。
一个被低估的神经网路
但是有一个限制,使得感知器的研究存在问题。上面的假设“如果存在这样的权重集合”提出了一个这样的困惑,即什么样的问题可能或不可能被感知器解决。令人尴尬的是,在二维平面中,简单分布的点不能被感知器分开(见图3–5,非线性)。事实证明,坦克感知器不是坦克分类器,而是天气分类器。a对图像中的坦克进行分类要困难得多,而事实上,它不能用感知器来完成。这也表明,即使感知器学到了一些东西,也可能不是你认为它应该学到的那些东西。压倒感知器的最后一根稻草是马文·明斯基和西摩尔·帕普特在1969年发表的数学专著《感知器》(Perceptrons)。 他们明确的几何分析表明,感知器的能力是有限的:它们只能区分线性可分的类别(见图3–5)。
这本书的封面展示了明斯基和帕普特证明的感知器无法解决的几何问题(见图3–7)。尽管在书的末尾,明斯基和帕普特考虑了将单层感知器进行泛化成为多层感知器的前景, 但他们怀疑可能没有办法训练这些更强大的感知器。不幸的是,许多人对他们的论断坚信不疑,于是这个研究领域渐渐被人们遗忘,直到20世纪80年代,新一代神经网络研究人员开始重新审视这个问题。
在感知器中,每个输入都独立地向输出单元提供证据。但是,如果需要依靠多个输入的组合来做决定,那会怎样呢?这就是感知器无法区分螺旋结构是否相连的原因:单个像素并不能提供它是在内部还是外部的位置信息。尽管在多层前馈神经网络中,可以在输入和输出单元之间的中间层中形成多个输入的组合,但是在20世纪60年代,还没有人知道如何训练简单到中间只有一层“隐藏单元”(hiddenunits)的神经网络。
弗兰克·罗森布拉特和马文·明斯基曾是纽约市布朗克斯科技高中的同班同学。他们在科学会议上为各自迥异的人工智能研究方法展开了辩论,而与会者更倾向于明斯基的方法。尽管存在差异,但他们二人对我们理解感知器都有着重要贡献,而这正是深度学习的起点。
罗森布拉特在1971年死于一次驾船事故,年仅43岁,当时正值人们几乎一边倒地反对感知器的时期。有传言说他可能是自杀,但也可能只是一次不幸的出游。15不可否认的是,一个发现了利用神经网络进行计算的新方式的英雄时代已经谢幕;又过了整整一代人的时间,罗森布拉特开创性努力的承诺才得以实现。
未来智能实验室是人工智能学家与科学院相关机构联合成立的人工智能,互联网和脑科学交叉研究机构。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)云脑研究计划,构建互联网(城市)云脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。
-
神经网络
+关注
关注
42文章
4572浏览量
98746 -
人工智能
+关注
关注
1776文章
43845浏览量
230596
原文标题:神经网络的黎明
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
卷积神经网络的优点
《 AI加速器架构设计与实现》+第一章卷积神经网络观后感
人工神经网络和bp神经网络的区别
卷积神经网络的定义、结构和发展历史
卷积神经网络一共有几层 卷积神经网络模型三层
卷积神经网络和深度神经网络的优缺点 卷积神经网络和深度神经网络的区别
卷积神经网络的介绍 什么是卷积神经网络算法
卷积神经网络的基本原理 卷积神经网络发展 卷积神经网络三大特点
卷积神经网络三大特点
卷积神经网络概述 卷积神经网络的特点 cnn卷积神经网络的优点
卷积神经网络的应用 卷积神经网络通常用来处理什么
卷积神经网络原理:卷积神经网络模型和卷积神经网络算法
卷积神经网络通俗理解
什么是神经网络?为什么说神经网络很重要?神经网络如何工作?
三个最流行神经网络






 工商网监
工商网监
评论