 深度解读大数据的应用现状和开源未来
深度解读大数据的应用现状和开源未来
近年来,随着大数据系统的快速发展,各式各样的开源基准测试集被开发出来,以评测和分析大数据系统并促进其技术改进。然而,迄今为止,还没有就这些基准测试集进行系统调研。因此,本文对当前最前沿的开源大数据基准测试集进行全面总结,阐述其历史、现状并展望下一步研究方向。首先,我们从大数据系统的角度对大数据基准测试集进行了定义和分类。随后,我们回顾了基准测试技术的三个重要方面——工作负载生成技术、输入数据生成技术和系统评估指标。最后,论文从这三个方面对现有基准测试集进行归类,并重点描述其中具有代表性的测试集,进而讨论未来研究方向,以推动该领域工作的持续发展。
介 绍
近年来,大数据在应用领域获得了广泛和毋庸置疑的成功,这些领域包括互联网服务(如搜索引擎、社交网络和电子商务)、多媒体(如视频、照片和音乐流)以及科学研究(如生物信息学、天文学和高能物理)等。在大数据时代,不断增长的数据量、快速处理数据(数据速度)的需求以及数据类型、结构和来源的多样性给我们带来了全新的挑战,传统的数据管理系统已经捉襟见肘。高效数据存储和处理的需求促使多种新的大数据系统被开发出来,这些系统通常被分为三个阵营,如图1所示:(1)Hadoop相关系统 (涵盖高级语言和结构化查询语言(SQL))已成为多数大数据应用的实际解决方案;(2)数据库管理系统(DBMSs)和NoSQL数据库在线上事务及分析中被广泛使用;(3)在大数据领域,人们对于图数据、流数据和复杂科学数据的特殊处理需要产生了对专用系统的需求。
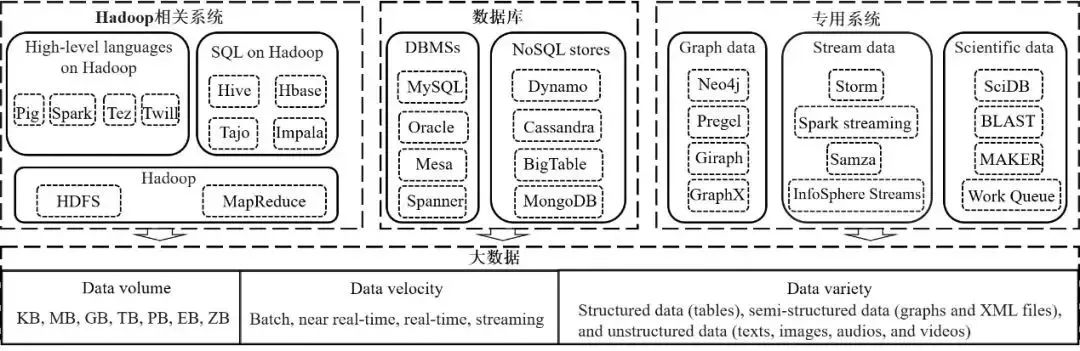
图1. 大数据系统分类与总述
在此背景下,对大数据系统进行基准测试已经成为许多领域研究开发工作的最重要驱动力之一,这些领域包括数据管理系统、硬件架构、操作系统和编程系统。首先,它有助于评估现有大数据系统的进展,从而推动其工程开发并且指导其性能提高。其次,它有助于评估新兴大数据应用的需求,从而促进大数据技术的进步。尽管大数据系统的基准评测已经吸引了学术界和产业界人士的广泛关注,但是到目前为止还没有对当今最先进的大数据基准测试集展开的全面评估。因此,基于作者自身积累的经验(创建BigDataBench项目以及召开多届大数据基准、性能优化和新兴硬件的国际研讨会(BPOE)),本文试图尽填补这一空白。该调查总结归纳了当前流行的开源基准测试集。图2显示了这些基准测试集的词云图,其中词的大小和流行度成比例。
图2. 开源大数据基准的标签云
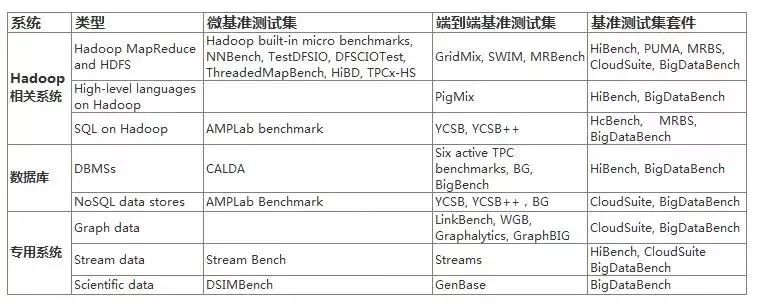
表1. 最新开源大数据基准测试集总览表
为了面向大数据社区中的广泛受众,本文首先提供了大数据基准测试集的概述和分类,如表1所示。第2章将详细介绍理解大数据系统和基准测试的必要概念。在接下来的章节中,我们将就三个重要方面(工作负载生成技术、输入数据生成技术和系统度量指标)对现有大数据基准测试集进行回顾。同时,我们将分别根据基准测试集在这三个方面的不同分为不同的类别,并描述每一类别中具有代表性的基准测试集。
首先,对于一个基准测试研究来说,工作负载中的操作实现了大多数应用的数据处理逻辑。因此相关的、可移植的和可伸缩的工作负载的生成,决定了基准测试集的代表性和可用性。鉴于此,第3章将从两个互补的方面来回顾现有基准测试集的工作负载生成技术:工作负载实现技术和运行时负载执行模式。
其次,数据量大、产生速度快和数据种类多是大数据最重要的特性,因而产生具有3V特性的工作负载输入数据的同时保证数据的真实性和可靠性是大数据基准测试集成功的先决条件。第4章通过把现有的输入数据生成技术分为四类:现有数据集、基于指定分布的数据集生成器、基于真实数据的数据集生成器以及混合数据集生成器。
最后,第5章总结了评估系统性能、价格和能耗的指标,并介绍了未来大数据基准测试中应该考虑的性能参数。
我们注意到,除了以上三个方面之外,关于大数据系统的基准测试还有其他重要的方面,包括大数据基准测试集的设计和实现方法;如何对基准测试集进行更新和扩展以及它们如何用于对大数据系统和应用的性能分析。所有这些方面都超出了本文的范围,我们推荐了一些最近的参考书目以便读者进一步阅读:面向Hadoop的基准测试集、数据库基准测试集和专用图处理系统的基准测试集;还有一些主流的基准测试集,如Yahoo! Cloud Serving Benchmark(YCSB)、BigBench、HiBench、CloudSuite 和BigDataBench 。
大数据基准测试集概述
在本节中,我们首先在2.1节中介绍大数据基准测试集的类别。然后,我们将在2.2节、2.3节和2.4节中分别介绍Hadoop 相关系统、数据库和专用系统的基准测试集的发展。
2.1大数据基准测试集分类
现有基准测试集通常可以根据基准测试范围分为三类:
微基准测试集。这类基准测试集被用于评估单个系统组件或特定系统行为(或代码的功能)。首先,系统组件既包括CPU或网络设备之类的硬件,又包括Hadoop分布式文件系统(HDFS)之类的软件,如NNBench和TestDFSIO用于测试HDFS中的NameNode和网络组件的性能。其次,Hadoop中特定系统行为的例子是grep和sort。
端到端基准测试集。这类基准测试集的目的是使用典型应用场景评估整个系统,每个场景都对应一个工作负载的集合。例如,TPC-E-58提供一组线上事务处理(OLTP)查询,以模拟交易和客户帐户管理等事务。
基准测试集套件是不同的微基准测试集或端到端基准测试集的组合,这些套件的目标是提供全面的基准测试解决方案。例如,HcBench和MRBS等基准测试套件提供了Hadoop相关系统的工作负载,HiBench、CloudSuite和BigDataBench则提供了多种大数据系统的工作负载。
在接下来的小节中,我们将分别介绍大数据系统的三大阵营以及为它们设计的基准测试集。图3展示了大数据基准测试集十年来的发展,并根据所评估的系统将它们分为四组:(1)从2006年Hadoop发布开始,Hadoop相关系统的各种基准测试集被开发出来;(2) 自2009年以来,继承自TPC的为数据库开发的基准测试集不断发展;(3)专用系统的基准测试是一个不成熟却快速发展的领域,因此相关基准测试集从2013年才开始出现;(4) 大数据系统的三大阵营均可用HiBench、CloudSuite和BigDataBench进行基准测试。表1总结了这些基准测试集,并根据它们的发布日期把相同类型的按升序排列。注意,大数据基准测试是一个活跃的研究领域,许多基准测试集在最初发布之后仍在发展(特别是HiBench、CloudSuite和BigDataBench),因此本文将重点讨论它们的最新版本。
图3. 大数据基准测试集发布时间轴
2.2 Hadoop相关系统
2.2.1 系统
Hadoop的HDFS和MapReduce。受Google文件系统(GFS)和Google MapReduce的启发,开源社区开发了Hadoop HDFS和MapReduce。随着以Hadoop为中心的系统在工业界取得了巨大的成功,各种各样在Hadoop上开发的系统出现了,我们将讨论其中两类主要的系统——高级语言和SQL。注意,尽管还有其他的大数据系统作为Hadoop的替代品,比如Apache Flink,但这一小节将重点讨论Hadoop相关系统。这是因为很多为Hadoop开发的基准测试集也可以用于测试那些替代品。
Hadoop的高级语言。此类系统开发有两个目标。第一个目标是简化Hadoop MapReduce作业的开发并自动优化它们的执行,从而使开发人员能够专注于编程逻辑。例如,来自yahoo!的Pig提供一种称为Pig Latin的文本语言,用于描述诸如连接、排序、过滤和用户自定义操作等数据操作符。通过使用Pig Latin,复杂的任务可以转换为一个或多个可在Apache Pig上执行的MapReduce任务。Apache Tez 和Twill的开发都有类似目的。
第二个目标是为了满足不断增长的实时数据提取的需求。传统上,Hadoop MapReduce提供的批处理通常需要几分钟或几个小时才能完成。因此,在Hadoop中添加高级语言的目的是支持实时数据处理。例如,加州大学伯克利分校的AMPLab建议Spark。
通过内存计算来加速Hadoop的数据处理。Spark为不同的应用提供了一个简单易用的编程接口,同时使用RDD来为内存中的计算范式提供高效的容错处理。
Hadoop的SQL。为了解决实时查询数据的问题,此类系统将SQL接口添加到Hadoop中。比如,受Google BigTable的启发,Apache HBase 5是在HDFS上建立的基于列的分布式数据库。在HBase中,表被用作Hadoop MapReduce作业的输入和输出。类似地,Hive是由Facebook开发的一个流行的数据仓库,它提供了一种名为HiveQL的类似SQL的语言,用于支持Hadoop上的交互式SQL查询。这一类别的其他系统包括Apache Tajo(一个关系数据仓库)、Apache Tajo(一个并行的数据库)和Spark SQL(支持关系处理的Spark的一个组件,Shark是它的之前的版本)。
2.2.2 基准测试集
在Hadoop的发布中,有几个内置的微基准测试集(即 WordCount、Grep 、Sort和TeraSort),它们是目前最常用的MapReduce基准测试集。通过引入性价比和能源消耗指标,TPCx-HS对TeraSort进行了扩展。Hadoop发行版的更高版本进一步提供了几个基准测试集来测试其组件,包括HDFS(基准测试集是TestDFSIO、DFSCIOTest和NNBench)和进程间通信(基准测试集是ThreadedMapBench)。HiBD (High-performance BigData)也测试了Hadoop网络组件的性能。此外,HiBench和PUMA是两组微基准测试集,它们应用在不同计算需求和不同数据传输量的领域。
GridMixMap和SWIM(Statistical Workload Injector for MapReduce)是两种流行的端到端基准测试集,它使用混合的合成工作负载来评估Hadoop集群。MRBench将TPC-H查询转换为MapReduce作业。PigMix是用来测试Pig的数据处理性能和可伸缩性的。
许多基准测试套件支持多个大数据系统。HcBench和MRBS是用来评估Hadoop的MapReduce和Hive的。CloudSuite提供了流行的、可扩展的工作负载,以评估在云架构中部署的Hadoop MapReduce和NoSQL数据库。BigDataBench全面覆盖了Hadoop相关系统(包括Spark、Hive、Spark和Impala在内)的工作负载。
2.3 数据库
2.3.1 系统
数据库管理系统。几十年来,并行的DBMSs被用作管理大规模数据的主要解决方案。除了传统的关系型DBMSs(如MySQL 36和Oracle 41),在遵循原子性、一致性、隔离性、持久性属性的基础上(ACID),最近人们还提出了处理大数据的新型数据库。这些数据库(如Megastore、Mesa和Spanner)旨在提供数据库的高可伸缩性,同时为用户提供方便的基于SQL的查询语言。此外,NewSQL数据库(例如HStore)是另一种为高吞吐量的在线OLTP而设计的关系型数据库,但它仍然保持ACID属性。
NoSQL数据库。然而,许多大数据应用并不需要严格的ACID约束,比起一致性和可靠性,它们更注重低延迟、高吞吐量这样的性能。在遵循了基本的可用性、软状态、最终基本的一致性后,种类繁多的NoSQL数据存储遵守如下要求:基本可用性、软状态(软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性)、最终一致性。对于大数据的处理,三种常用的NoSQL数据库分别为Key/Value数据库(如Amazon Dynamo、Cassandra和Linkedin Voldemort)、基于列的数据库(如BigTable 和Hypertable)和基于文档的存储(如CouchDB和MongoDB)。
2.3.2 基准测试集
在过去的几十年里,TPC基准测试集是评估DBMSs的实际标准。在13个TPC基准测试集中,6个活跃的基准测试集是:针对线上事务处理数据库(OLTP Database)的TPC-C和TPCE,针对决策支持系统(DSSs)的TPC-H、TPC-DS和TPC-DI,而TPCVMS则将来自上述基准测试集的工作负载混合在一起来评估虚拟化系统。这些基准测试集仍是DBMSs大数据基准测试解决方案的一般选择。此外,最近人们还开发了一些基准测试集来比较DBMSs和MapReduce系统。CALDA提供基于Hadoop的分析工作负载,将Hadoop与基于行的DBMS(DBMS-x)和基于列的DBMS(Vertica)进行比较。AMPLab基准测试集使用CALDA的工作负载比较了几个数据分析系统,包括Apache Tez、一个NoSQL数据库(Amazon Redshit)以及Hadoop上的三个SQL系统(Hive, Shark, and Impala)。由TPC-DS发展而来的BigBench提供了在线服务工作负载和离线分析工作负载,可以用来比较Hadoop和Teradata DBMS。
近年来,NoSQL数据库的涌现引发了对新基准测试集的需求。YCSB是一个流行的基准测试集,它提供了云在线服务工作负载(也就是在线事务处理操作的混合)。它可以用来比较两个非关系数据库(Cassandra和HBase)和一个异地分布式数据库(PNUTS)以及一个传统的关系数据库(MySQL)。YCSB+扩展了YCSB以评估NoSQL数据库的高级特性(如提取加速技术)。BG提供了用于仿真社交网络操作的工作负载,这个基准测试集可以用来比较DBMSs(如SQL-X和CASQL)和NoSQL(如MongoDB)。
2.4 专用系统
在学术界、工业界和管理界中越来越多地使用图数据、流数据和科学数据,这促使了许多专用系统的产生。与通用的大数据系统相比,这些专用系统的设计是为了在执行复杂查询或分析特定数据类型时提供更好的性能。根据系统所支持的数据类型,我们介绍三个主流的专用系统。
2.4.1图数据
系统。随着数据和网络科学的快速发展,越来越多的信息被连接起来形成了个大图。在一个互联的世界里,图自然地模拟出复杂的数据结构,如社交网络、蛋白质相互作用网络和自然网络。图数据被广泛应用于许多领域,如在线零售、社交应用和生物信息学。为了解决图数据日益增长的规模和复杂性所带来的挑战,两类图系统被人们开发出来:(1) 图数据库,如Neo4j;(2) 分布式图处理系统,如Google Pregel要求程序员根据顶点的操作和交互来编写函数,Giraph和Graphx分别是Pregel在Hadoop和Spark中开源的实现,HaLoop是Hadoop中MapReduce的改进版本,它用于迭代图的数据分析。
基准测试集。人们已经开发了许多图基准测试集来评估图数据库、高性能计算(HPC)系统和超算系统(如Graph 500)。在评估大数据应用时,数据量大和图计算的多样性带来了新的挑战——我们需要新的基准测试集。LinkBench和GraphBIG是针对此类问题面向Facebook社交网络和IBM System G的场景开发的。其他的基准测试集包括Waterloo Graph Benchmark (WGB)、Graphalytics、CloudSuite。此外,BigDataBench也提供了工作负载来比较图数据库、分布式图处理系统和Hadoop相关系统。
2.4.2流数据
系统。流式数据处理的巨大的潜在价值与大数据的流处理系统的出现息息相关。在这些系统中,数据不断地到达,并且在短时间内处理。传统的流数据主要来自传感器网络和金融交易。今天,大多数流数据是由Web 2.0应用程序和物联网(IoT)设备生成的文本和媒体数据。因此,在处理大量流数据时,需要更强大的流数据处理来提供高可用性和快速恢复能力。为了应对这一挑战,来自开源社区的流分析系统(如Apache Storm、Spark Streaming和Samza)和来自工业界的流分析系统(如IBM的InfoSphere Streams和TIBCO)已经被提出。
基准测试。开发流基准测试集需要解决几个挑战性问题,其中包括生成具有语义有效性的数据、为连续的查询结果生成正确的答案、设计一个查询语言标准。线性负载是一种用于评估流数据管理系统的过时的流基准测试集,它只能支持数值数据。Stream Bench和HiBench提供了7个微基准测试集来评估Storm、Spark Streaming 和Samza。Streams是最新的一个用来比较IBM InfoSphere Streams和Apache Storm的基准测试集,它的工作负载是模拟在线垃圾邮件检测和电子邮件分类。另外,CloudSuite通过一个媒体流基准测试集来测试Darwin Streaming Server。BigDataBench通过三个交互式工作负载来测试Storm。
2.4.3科学数据
系统。现代研究仪器可以产生大量的科学数据,它们的数据量和速度都呈指数级增长。例如,欧洲核子研究组织(CERN)的物理学家和工程师储存了200千万亿字节(PB)的数据,每年产生约15千万亿字节的数据。当前和未来的科学数据基础设施对高效捕获、存储、分析和整合这些海量数据集的需求不断增长,这将刺激许多科学大数据系统的发展,例如,SciDB是一个用于管理PB级科学数据的分析数据库。基于这样的想法,许多科学数据集(如卫星图像、海洋、望远镜和基因组数据集)在SciDB中都被表示为数组,SciDB采用多维数组数据模型来支持复杂的查询。国家生物技术信息中心(NCBI)还提供了一个系统列表(如Basic Local Alignment Search Tool (BLAST))来存储和处理基因组数据。MAKER和Work Queue是为促进基因组数据大规模并行处理而开发的系统。此外,R是一个普适的环境,为科学应用程序提供统计分析技术,也为一些最近的系统(如SparkR)提供了一个可以支持大数据的分布式的R的实现。
基准测试集。尽管有各种各样的科学大数据系统,但目前还没有可用的基准测试集。DSIMBench是为了比较R和Hadoop而开发的。GenBase提供工作负载来比较R、Hadoop、DBMSs(Postgres和System X)和SciDB。BigDataBench提供工作负载来测试Message Passing Interface (MPI)和Work Queue。
工作负载生成技术
这一节,我们在表2和表3总结了已经存在的大数据基准测试集,从两个技术维度——工作负载实现技术(3.1节)和运行时执行模式(3.2节)——来揭示工作负载生成技术的基本特征。然后我们接着在3.3节中讨论了开放性的挑战问题。
3.1 工作负载实现技术
在大数据系统的基准测试研究中,工作负载描述了它们的典型行为。也就是说,工作负载可通过从这些行为中提取操作(函数或算法)形成。因此,根据用于形成工作负载的操作类型,我们将大数据工作负载划分为三类:
1. I / O操作。这些操作在输入数据或文件上执行(例如,读、写、移动数据或新建、删除文件)。在现有的大数据基准测试集中(除了GridMix),一个工作负载是由一个I/O操作来实现。
2. 算法操作。当作为一种算法实现时,一个工作负载由一个或多个对输入数据的独立操作组成。
3. 基本操作(EO)。这些操作要么是标准的SQL操作符,要么是具有类似语法的操作符(如Pig Latin)。与以上两类分别实现为固定的I/O操作或算法操作的工作负载相比,第三类工作负载的实现支持工作负载中EOs的动态组合,以模拟不同的应用场景。
现在,我们将在3.1.1、3.1.2和3.1.3小节分别针对Hadoop相关系统、数据库和专用系统的基准测试集回顾其工作负载实现技术。
表2. 大数据基准测试集的负载生成技术:单个负载
3.1.1 Hadoop相关系统
在Hadoop内置的微基准测试集中,工作负载是用算法操作实现的。具体地说,WordCount、Grep和Sort工作负载的算法分别是计算单词频率、计算匹配的正则表达式的数量以及排序输入数据。这些工作负载代表了Hadoop应用中的CPU密集型行为(WordCount)和I/O密集型行为(Grep和Sort)。TeraSort是一种改进版的Sort。该算法首先对输入数据进行采样,并将其划分为若干个有序段。然后,它用map/reduce任务对片段中的数据进行局部排序,并将所有的reduce任务合并在一起,以对输入进行整体排序。因此,Terasort在map阶段是CPU密集型,而在reduce阶段则是I/O密集型。
大多数用于测试Hadoop组件的基准测试集都是通过I/O操作实现的。NNBench通过文件操作来评测HDFS的NameNode。TestDFSIO和DFSCIOTest都是用来测量HDFS的读取和写入数据的能力。ThreadedMapBench使用Sort作为MapReduce的例子来测试网络的移动性能,在这种情况下,map任务的输出可以有一个或多个溢出。类似地,HiBD的工作负载会将均匀地、伪随机的、或不均匀地中间数据打乱重排。
此外,PUMA集成了Hadoop内置的微基准测试集,并为统计分析和机器学习算法开发了10个新特性:(1) Term-vector可以找到文档中出现频率最高的单词;(2) Inverted-index创建了一个文字到文档的倒排索引;(3) Selfjoin把k-field的关联作为(k + 1)-field关联的输入和输出;(4) Adjacency-list生成图中节点的邻接表;(5)k - means聚类;(6) Classification将输入归为k个预定义类中的一个;(7) Histogram-movies生成输入数据的直方图;(8) Histogram-ratings在 MovieLens数据集中生成一份评级的直方图;(9) SequenceCount可以统计一个文档中3-gram的数量;(10) Ranked Inverted Index可以根据文档中单词出现的频率将其降序排列。
GridMix和SWIM是两种流行的端到端基准测试,它们使用了I/O操作来实现合成的MapReduce工作负载。具体来说,GridMix实现了两种工作负载:LOADJOB模拟读、写、打乱以及map和reduce任务;而SLEEPJOB则将这些任务挂起。SWIM使用数据打乱操作来模拟MapReduce作业中的shuffle/input和output/shuffle比率。此外,MRBench实现了MapReduce框架中的SQL操作符(如select、order和join),并将22个TPCH查询转换为MapReduce作业。PigMix是由Pig发展而来,因此它的工作负载由Pig操作符组成(如连接、分组和分割),其语法严格遵守SQL标准。Pigmix有12个查询工作负载,而PigMix2又增加了5个。
最后,有两个基准测试套件包含了各种各样的微基准测试集和端到端基准测试集。HcBench由具有交互工作负载的基准测试集组成,它能模拟实时数据分析场景。MRBS的主要是通过在工作负载执行期间生成和注入故障负载来评估Hadoop集群的可依赖性和可靠性,这个基准测试集套件提供了五个端到端基准测试集,分别用来代表数据密集型和计算密集型场景。
3.1.2数据库
在TPC系列的基准测试集中,工作负载是通过把标准SQL操作符和其他操作符结合在一起实现的,其中标准SQL操作符包括算术、字符、比较、逻辑、集合。这些操作符可以三种方式(即顺序的、并行的和迭代组合)组合起来形成代表不同业务场景的查询工作负载。TPC-C和TPC-E提供了5到10个事务类型的OLTP工作负载来模拟批发供应商和经纪公司的查询。TPC-H提供了22个特设的负载来表示在DSSs(decision support system)中插入和删除数据的操作。PC-DS进一步使用99个查询模板来支持DSSs中数千个查询的生成。这些查询工作负载可以分为四类业务场景:报告、点对点、迭代查询和数据挖掘。此外,TPC-ID能够表示DSSs中的两个数据集成场景的工作负载,这两个集成场景分别是:(1)在最初创建DSS时加载数据的操作;(2)将新数据集成到现有DSS中的操作。
使用SQL操作符,BigBench定义了30个查询工作负载来表示大数据分析中的典型行为。这些工作负载覆盖了5个业务模型(销售、推销、运营、供应链和新业务模型)、3个数据结构(结构化、半结构化和非结构化数据)以及3种分析技术(统计分析、数据挖掘和报告)。
另外,CALDA使用5个操作符来实现三个查询工作负载(扫描、聚合和连接),这几个工作负载代表了MapReduce和DMBSs中的数据分析任务。AMPLab基准测试集继承了这些工作负载,并添加了使用PageRank算法实现的工作负载。BG通过使用读取和更新数据库的操作来模拟社交网络操作。
通过对各种web应用程序进行测试,YCSB定义了云服务系统的4个基本操作。为了得到实际的操作组合,YCSB采用了四种分布(uniform、Zipfian、Latest和Multinomial)来决定执行的四个基本操作中的一个。该基准测试集提供5个核心的工作负载(即频繁更新、频繁读取、只读、读取最新的和读取短期的)表示5个典型的云服务应用。
3.1.3专用系统
图数据、流数据和科学数据是当前专用大数据系统的重点。我们将讨论这些系统的工作负载生成技术。
图数据。图由有限数量的顶点(节点)和边以及与之相关的属性组成。从对图的操作来看,图的工作负载通常有4种:图的查询、图的遍历、图的更新和图的分析。
LinkBench和WGB都使用SQL操作符来实现工作负载。LinkBench是为通用图数据库(如MySQL和HBase)设计的,它的工作负载应用场景是三种Facebook社交图操作:图查询(获取定点/边)、图更新(插入、更新和删除定点/边)和图分析(计数和测边距)。WGB在其工作负载中实现了三个分布式处理场景:图查询(查找匹配的顶点或边、查找k跳邻居、可到达性和最短路径查询、模式匹配)、图更新(添加/删除顶点或边、更新图结构)和图分析(PageRank和聚类)。
此外,Graphalytics在其社交网络工作负载中使用了各种算法来测试图分析系统的瓶颈。这些工作负载包括三种:图遍历(广度优先搜索(BFS))、图更新(图演变)和图分析(一般统计信息、连接组件(CC)和社区检测)。GraphBIG是为CPU和GPU平台开发的基准测试集,它的13个工作负载覆盖三个应用场景:图遍历(BFS,DFS)、图更新(图构建、更新和拓扑变形)和图分析(最短路径、k-core分解、CC、图着色、三角形数、吉布斯推论、度中心性、中介中心性)。
流数据。Stream Bench提供了几个微基准测试集来表示流应用场景中的典型行为。而Streams实现的工作负载可以用来表示电子邮件分类应用的七个阶段。BigDataBench提供了三种工作负载:协同过滤 (CF)、Nutch网页搜索以及热点头条(它对传入流的主题进行滚动计数,并识别最热门的k个话题)。
科学数据。当前的基准测试集提供了处理微阵列数据的工作负载。DSIMBench实现了一个聚类算法用来作一个微阵列计算的工作负载。GenBase的工作负载对应于DNA微阵列数据集的5种典型的基因组算法,这些工作负载代表了生物学和医疗领域的5种应用场景。BigDataBench基于Scalable Assembly at Notre Dame (SAND) 和BLAST实现了一系列基因组数据的工作负载。
3.1.4同时适用于三大阵营系统的基准测试套件
HiBench由Hadoop内置微基准测试集(WordCount、Sort、TeraSort)、Nutch网页搜索(PageRank和Nutch索引)以及Mahout(贝叶斯分类和k-means聚类)组成。这些工作负载既可以在Hadoop运行,也可以在Spark上运行。该套件还提升了TestDFSIO的性能来计算HDFS聚类的吞吐量。它的最新版本集成了CALDA和Stream Bench的微基准测试集。
CloudSuite是为扩展性云应用而设计的,因此它的工作负载偏向于在线服务。具体地说,它对数据库和专用系统的基准测试集提供了服务工作负载,同时它的基准测试集为Hadoop相关系统提供了分析工作负载。Hadoop分析工作负载是使用Mahout机器学习算法实现的。在其图基准测试集中,TunkRank算法通过计算Twitter用户的追随者的数量来估计该用户的影响力。在其流基准测试集中,工作负载处理QuickTime流和MPEG数据。
BigDataBench是一个基准测试套件,它提供的工作负载不仅涵盖不同领域的大数据应用场景(即因特网服务、多媒体分析和生物信息学),还包括当前最先进的大型数据软件栈。首先,BigDataBench为与Hadoop相关的系统提供了7个微基准测试集。每个基准测试集都包括不同的工作负载,它们基于四个软件栈(Hadoop、Spark、MPI和Flink)来实现相同的算法。此外,BigDataBench提取了9个用于数据库的有代表性的操作,每个操作都是基于三个软件栈(Hive、Shark和Impala)实现的工作负载。最后,BigDataBench在工作负载中实现了几个用于图、流和生物信息应用的算法。
3.2工作负载运行时执行模式
在本节中,我们首先介绍应用在现有基准测试集中的单个工作负载的提交策略(3.2.1节)。然后,为模拟实际的应用场景(3.2.2节),我们将讨论关于混合工作负载的基准测试技术。
3.2.1工作负载提交策略
在工作负载执行期间,提交策略决定了工作负载的输入数据和输入模式(即提交速率和顺序)。我们将本文回顾的基准测试集的提交策略分成三类。
预先指定。在许多基准测试集中,工作负载的输入数据、提交速率和顺序都是在执行前指定的。这里可分为两种情况。在第一种情况下,基准测试集一次执行一个工作负载。例如,在Hadoop内置的微基准测试集(如WordCount、Grep和Sort)中,工作负载执行遵循两步预定流程:上传输入数据到HDFS、运行工作负载。TeraSort还有第三步来检验已排序的输出数据。其他的微基准测试集(包括TPCx-HS、Stream Bench、DSIMBench、 HcBench和CloudSuite的微基准测试集)也属于这种情况。此外,尽管一些端到端基准测试集(如PigMix, WGB, Graphalytic, GraphBIG和Streams)使用了一组相关的工作负载来模拟应用场景,但这些基准测试集仍是一个个地执行这些工作负载。在第二种情况下,许多端到端基准测试集使用固定的输入数据、提交速率和顺序来执行多个工作负载。例如,TPC系列基准测试集使用了一个标准的工作负载执行过程,它有5个步骤:系统设置、数据库设置、数据库加载、工作负载生成和执行以及系统度量。其他的一些数据库基准测试集(如CALDA、AMPLab基准测试集和BigBench)也都应用了类似的工作负载执行模式。
参数控制。这类基准测试集允许用户使用参数控制工作负载的执行。首先,在用于测试Hadoop组件的微基准测试集中,NNBench和MRBench提供了用于控制创建文件数的参数,DFSCIOTest提供了用于控制文件数量和大小的参数,ThreadedMapBench提供参数来控制输入文件的大小、每个map的分支数量以及每个主机的map数量。此外,YCSB提供了一个客户端参数列表,它不仅可以决定输入数据和工作负载的大小和内容,还控制了工作负载提交率(即目标吞吐量和线程数量)。类似地,BG提供数据库、工作负载和评级参数来控制数据内容(如行数)、工作负载提交(例如,会话数和会话间的思考时间)以及在基准测试中使用的评估指标。LinkBench保持平均输入率不变,但允许用户根据指数分布来配置和决定请求到达间隔。
真实日志驱动。通过使用这种提交策略,基准测试集可以根据真实世界的日志来真实地复现工作负载。SWIM复现合成的MapReduce作业,它的输入速率、顺序和输入数据的大小都采用了Facebook记录的的真实作业。类似地,BigDataBench的多租户版本(名为BigDataBench-mt 115)根据Google集群日志中匿名作业的提交模式复现了实际的Hadoop和Spark作业 (WordCount、Grep和排序) ,复现的前提是实际作业和匿名作业的工作负载特征非常相似。
最后,一些基准测试集应用了混合提交策略。GridMix支持以上全部三类提交策略。在第一个策略中,作业提交过程是预先指定的,一旦完成了作业,就会提交作业。如果测试的集群负载不足或过量,则第二个策略会自动增加或降低提交率,GridMix使用了这个策略,它提供了5个参数来定义负载过量和不足的阈值。第三种策略提交的作业完全遵循真实日志中的工作时间的间隔,比如Rumen日志。MRBS提供了两种提交策略:使用预先指定策略时,它会在提交新工作之前等待当前工作负载完成;使用参数控制策略时,它会创建多个并发客户端,并提供参数来控制每个客户端工作负载提交的等待时间间隔。
3.2.2工作负载混合
真正的大数据系统通常执行由多个租户提交的并发运行的多个工作负载。在执行期间,不同类型的工作负载有不同的比例。然而,大多数现有的微基准测试集都使用单租户工作负载提交模式。也就是说,这些基准测试集仅根据单个队列执行工作负载,在表2中我们把这些基准测试叫做“not a mix”。另一方面,大多数端到端基准测试集和一些基准测试套件采用多租户提交模式,因此它们可以生成一种合成的或现实的工作负载混合。
合成工作负载的混合。许多基准测试集(如PigMix、HcBench和BigBench)都预先确定了不同工作负载的比例。TPC系列基准测试集还设计了一个具有不同比例的查询集。类似地,YCSB调用包来联结一套相关的工作负载以模拟应用场景(比如有“大量读”或“大量写”工作负载的场景)。LinkBench提供了合成的图操作工作负载混合来模拟Facebook的社交网络场景。此外,MRBS还使用随机分布等概率分布来决定不同工作负载的比例。
真实工作负载的混合。由于真实的日志是工作负载混合模式最可信的来源,所以GridMix和SWIM首先通过挖掘生产日志来描述MapReduce作业的真实组合,再根据日志运行I/O工作负载。根据Google的集群日志,BigDataBench也可以重现真实的Hadoop或Spark混合作业。
表3. 大数据基准测试集的负载生成技术:混合负载
3.3 开放性挑战问题
根据工业标准(例如TPC和公司评价表现标准(SPEC)),从工作负载角度看,成功的基准测试集有三个准则:(1)相关性:负载应能体现被测系统的典型行为;(2)可移植性:负载应能在不同的软件系统和架构上执行;(3)可伸缩性:负载数量应能增加或删除以来测试不同规模的系统。我们注意到已有的大数据基准并不能完全符合以上三个准则。
相关性。鉴别被测系统的典型行为是实现高度相关性负载的先决条件。大数据系统的快速发展要求基准测试集不仅要紧跟当前最先进的技术和系统,还要考虑未来的变化。例如,针对流数据和科学数据的专用系统的应用范围很广,但现有基准测试集仅涵盖这些应用场景的极少数情况。另一个例子是,尽管为Hadoop相关系统开发了大量基准测试集,但这些基准测试集主要是为批处理和对延迟不敏感的应用开发的,并且它们不适用新出现的Hadoop相关系统(如Cloudera Kudu,它是2015年九月发布的支持延迟敏感分析应用的系统)。
大数据系统的多样性和快速发展使得开发具有代表性的工作负载并使之覆盖不同的应用场景变得非常具有挑战性。解决此问题的一个可行方案是从各种工作负载独立于系统的行为中抽象出一般方法,从而将整个工作负载分解为许多EO(基本操作)及其组合模式。充分的抽象不仅允许使用现有的EO开发新的工作负载而很少或不改变EO本身,也为不同的系统实现留出空间。到目前为止,这种抽象方法已成功应用于两个领域:数据库和HPC,它们使用标准SQL运算符和13 dwarfs(即一种用来描述HPC工作负载的计算和通信模式的方法)分别作为EO。 BigDataBench还初步研究了这种方法,它使用11个SQL运算符来表示三个大数据应用场景:快速存储、日志监控和PageRank。
在数据应用中,应用抽象方法来深入了解EO和它们的组合模式需要解决三个挑战性问题。首先,在大多数大数据应用中(例如因特网服务和多媒体),工作负载是在半结构化和非结构化数据上执行的,它们的操作和模式是复杂多样的。其次,大数据领域(例如机器学习、数据库、自然语言处理和计算机视觉)多意味着研究它们所有的应用抽象是相当耗时的。 最后,不同的大数据软件栈(例如Hadoop,Spark,Flink,Kudu)和库(例如Mahout,MLlib,AstroML)中的算法种类加大了抽象的难度。
可移植性。我们首先从软件系统(即软件栈)的角度讨论这个准则。大数据系统通常允许程序员编写一些代码(例如Hadoop中的Map和Reduce函数)来实现他们的应用,同时将资源管理、作业调度、容错处理和其他任务留给软件栈。因此,与传统软件系统相比,大数据系统更加复杂。比如,典型的HPC系统仅有两层:分布式调度器和分布式运行环境(例如MPI)。而 Hadoop有五层:JVM层、HDFS层、分布式调度器(如Yet Another Resource Negotiator(YARN))、分布式运行环境(Jobtrack和Tasktrack)以及Hive数据仓库层。之前的研究表明,软件栈对工作负载性能有显着影响。例如,在Spark上运行的作业比在Hadoop上运行的作业快100倍。
因此,在不同的软件系统上实现相同逻辑(算法)的工作负载十分必要,这可以实现这些系统间的相互比较。目前的一些基准测试集支持在不同大数据系统上实现可移植的工作负载:HcBench和MRBS在Hadoop和Hive上实现工作负载;CALDA和AMPLab基准测试在Hadoop上实现了并行数据库和SQL引擎上的工作负载;HiBench在Hadoop,Spark,Storm和Samza上实现了工作负载;GenBase在R、Hadoop、DBMS和SciDB上实现了工作负载;BigDataBench在Spark、Hadoop、MPI和Flink上实现了八个工作负载;Hive,Shark和Impala实现了九个工作负载。 但是,大多数被调查的基准测试集并不支持在不同的大数据系统上运行可移植的工作负载。
考虑到现代数据中心的异构体系结构,在不同体系结构上执行工作负载是工作负载可移植性中同样重要的一个方面。但是,现有的基准测试集只做了初步工作。GraphBIG为基于CPU和GPU的平台提供工作负载。BigDataBench提供了另一种解决方案,它在三个微架构模拟器(Simics,MARSSx86和gem5)上实现Hadoop MapReduce工作负载,从而允许架构研究人员在不同的体系结构(如x86,ARM和SPARC)上对这些工作负载进行模拟评估。该领域需要更多的基准测试集。
伸缩性。为了评估不同规模的系统,基准测试集应该能够调整工作负载的规模,同时保证其提交和混合的真实性。但是,现有基准测试集要么支持使用参数调整负载规模的工作负载而不考虑其真实性,要么执行和提交真实工作负载但不能动态地调整规模。此问题的一种可能解决方案是分析真实日志以得到准确的租户信息(其中包括不同租户的分布以及他们提交的工作负载)。使用这些分析得到的信息,基准测试集可以构建一个多租户框架,并通过调整并发租户数量来控制工作负载的规模,同时仍然保持这些用户提交的工作负载分布与真实场景一致。
输入数据生成技术
在本节中,我们首先介绍大数据的特征(4.1节),然后回顾现有大数据基准测试集中的四类输入数据生成技术(4.2节)。最后,我们讨论一些公开的挑战(4.3节)。表4列出了这些技术的摘要。请注意,有两类基准测试集不在此处的讨论范围内。第一类(如GridMix、SWIM和HiBD)需要基准测试用户提供输入数据。第二类(如NNBench和DFSCIOTest)则不需要输入数据。
4.1 大数据特征
最常见的大数据特征是由美国国家标准与技术研究院(NIST)和Gartner提出的3个V,即数据量(volume),速度(velocity)和种类(variety)。
数据量。数据量是最能体现大数据规模的特征。大多数数据源的数据量通常由存储单元数(如GigaByte(GB),TeraByte(TB),PB,ExaByte(EB)和Zettabyte(ZB))测量。在诸如社交图的图数据中,数据量是根据峰值(例如,2的20次方)的数量来测量。 据IBM称,今天90%的数据是在过去几年中创建的,生成的数据将在未来几年呈指数级增长。例如,预计人类和设备每天将创建2.3万亿GB数据,预计到2020年将创建超过35个ZB数据。另一个例子是,单个人类基因组测序结果大小约为140GB,而世界人口约为70亿。
速度。速度不仅反映了数据生成有多快,更重要的是反映了大数据系统处理数据有多快。高速数据源有很多。例如网站和数据库中的日志文件、 移动设备(如手机)、 Facebook和Twitter等社交媒体、公共云中的在线游戏和大量服务应用软件(SaaS)。 以社交媒体为例,人们每月在YouTube上观看40亿小时的视频,分享10亿条内容,每天在Facebook上创建超过500 TB的数据,每小时发送1667万条推文。如今的大数据系统必须实时处理如此如此快速产生的数据。
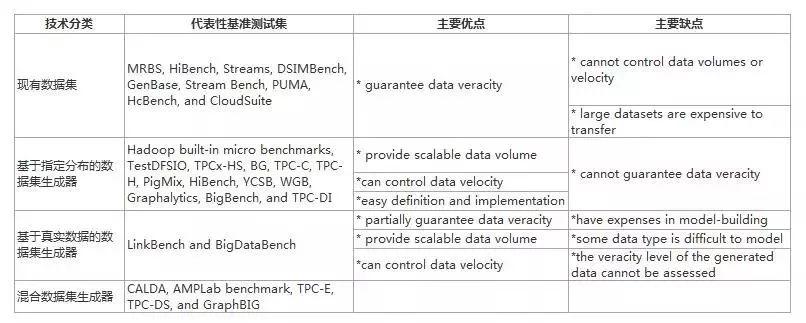
表4. 大数据基准的数据生成技术总览表
种类。种类表示数据类型、数据结构和数据源的差异和多样性。信息技术的快速发展意味着越来越多的数字化信息产生。数字化信息不仅包括结构化数据(例如表格),还包括各种各样的非结构化数据(例如文本,图像,音频和视频)和半结构化数据(例如图和XML数据)。 数字信息的巨大价值极大促进了各种大数据系统的发展,以存储不同类型的数据,并提供查询和分析服务。
此外,IBM提出真实性是大数据的第四个特征。数据的真实性体现数据的可靠性水平。真实世界的原始数据集通常是混乱的,并且有内在的错误、不一致性、不完整性、模糊和污染。为了避免由不正确和不确定的数据引起的问题,必须进行数据清理和预处理以保证数据的真实性。为产生价值(例如做出正确的决策),组织和客户都需要确保数据在处理和分析之前是可靠的。例如,IBM估计由于缺乏数据真实性,美国消费者每年损失3.1万亿美元。
为了在不同的基准测试场景下产生有意义且可信的评估结果,数据生成器需要支持不同的数据类型(数据真实性),并在可控生成速率(数据速度)下生成可伸缩的工作负载输入数据(数据量),同时保证所用数据的可靠性(数据真实性)。在此背景下,我们回顾了四类数据生成器。
4.2 大数据基准测试中的数据生成器
(1)现有数据集:许多大基准测试提供固定大小的数据集作为其工作负载的输入。MRBS提供了从不同数据源(如MovieLens、Genomic研究中心和Wikipedia Dump)获得的各种真实数据集。HiBench也使用维基百科转储和维基百科页面到页面的链接数据库作为工作负载的输入。除了这些数据集之外,HiBench还抓取了240万个维基百科网页,并将它们用作Nutch页面索引工作负载的输入数据。
为流数据和科学数据系统设计的基准测试通常提供真实数据集作为工作负载输入数据。Streams的电子邮件工作负载的输入数据是1.1 GB的Enron数据集。Stream Bench开发了一个基于Apache Kafka的消息系统来从两个真实数据集(AOL搜索数据和CAIDA匿名Internet日志数据)生成流。DSIMBench使用来自NCBI的两个微阵列数据集。GenBase也使用代表不同患者基因的微阵列数据。
此外,一些基准测试集提供了具有一系列可选数据规模的现有数据集。PUMA扩展了五个公开可用的数据集(Wikipedia, Self-Join, Adjacency-List, Movies, and Ranked-Inverted-Index),并为每个数据集提供了2到4个可用的数据规模,其范围从30 GB到300 GB。HcBench提供了9个合成数据集,其数据大小以2的n次幂为单位生成,范围从128MB到32GB。CloudSuite还提供了真实数据集列表,并支持扩展这些数据集。
总结。使用现有的数据集可以保证数据的准确性,因为它们通常是从现实世界的数据源获得并经过适当的清理。但是,如果没有数据生成器,则无法控制数据量和速度。此外,通过互联网传输大数据集(如下载TB或PB规模数据)非常消耗资源。
1. 基于合成分布的数据生成器:这类数据生成器根据它们采用的分布可以分为两类。第一类生成器根据默认的均匀分布创建随机的工作负载输入数据。 WordCount、Grep、Sort和TestDFSIO基准使用两个随机数据生成器(RandomWriter、RandomTextWriter)。ThreadedMapBench、TeraSort、TPCx-HS和BG构建自己的随机数据生成器。TPC-C和TPC-H中使用dbgen在生成的数据库表中产生均匀分布值。YCSB提供生成器来创建具有指定数量记录的数据集。MRBench开发了一个表解析器将TPC-H表转换为纯文本文件。
第二类生成器在数据生成中使用非均匀分布。PigMix和PigMix2使用zeta分布和均匀分布产生数据。HiBench使用统计分布来生成k均值聚类工作负载的输入数据。WGB基于递归现实图生成器实现其图生成器,它使用幂律分布模拟图的实际属性。类似地,Graphalytics通过添加两个多度分布(Zeta分布和几何分布模型)和图结构特征来扩展社交网络图生成器。此外,BigBench 和TPC-DI都采用并行数据生成框架(PDGF)来生成结构化表格数据。PDGF既提供使用种子策略创建随机数的随机生成器,也给出了提供基本分布函数列表(如正态分布,泊松分布和指数分布)的分布生成器。BigBench扩展了PDGF以生成半结构化数据(Web日志)和非结构化数据(文本)。
总结。合成数据生成器易于定义和实现。他们可以根据用户的基准测试要求提供可伸缩的数据量。例如,TPC-C和TPC-H中使用的dbgen提供了8个比例参数,它可以生成大小范围从1GB到10,000 GB的表。这些生成器还可以通过调整数据生成期间的并行程度来控制数据速度。例如,RandomWriter和RandomTextWriter是为map / reduce程序实现的。因此,它们可以通过调整map和reduce数量来控制数据速度。然而,尽管一些合成生成器(例如PigMix,HiBench和BigBench数据生成器)使用经过充分研究的分布来模拟真实世界分布,但生成的合成数据与实际数据的接近程度取决于这些分布中使用的参数。最佳参数通常无法获得,因此无法保证生成数据的真实性。
1. 基于真实数据的数据生成器:此类数据生成器捕获并保留实际数据的重要特征,进而生成具有类似特征的可伸缩的合成数据来维护数据的可靠性。例如,LinkBench首先从真实的Facebook社交图谱中学习图结构的属性,然后根据学到的属性通过随机生成图节点和边来创建真实的基准数据。
事实上,在许多实际情况下,由于机密和花费的问题,获取大规模真实数据集很困难。BigDataBench开发了Big Data Generation工具(BDGS)以便在真实的基础上生成可伸缩的工作负载输入数据集。BDGS有三个基本步骤:(1)选择不同类型和来源的具有代表性的真实世界数据集。BigDataBench现在提供15个真实数据集;(2)构建数据模型以捕获和保留真实数据集的重要特征。BDGS提供了三个数据生成器:文本生成器、图生成器和表生成器,它们使用隐式Dirichlet分配(LDA)模型、kronecker图模型和PDGF来确定真实文本的特征、图和表格数据。例如,文本生成器可以应用LDA来描述文本中的主题和单词分布。该生成器首先从真实文本数据集(如亚马逊电影评论)中学习以获得单词字典,然后它使用该数据集训练LDA模型的参数;(3)在合成数据的生成中可以使用参数控制数据量和速度。
总结。迄今为止,基于真实数据的生成器是有效生成具有可控数据量和速度的工作负载输入的最佳技术,同时确保生成的数据具有与实际数据类似的特征。然而,因为它无法定量评估生成的合成数据的真实性水平,这种数据生成技术仅能定性地保证数据的真实性。
1. 混合数据生成器:一些基准测试集采用上述工作负载生成技术的混合。CALDA生成HTML文档作为其工作负载输入。在每个文档中,visitDate,adRevenue和sourceIP的文件在特定范围内随机生成,其他文件从真实数据集中采样,并且使用Zipfian分布生成到其他页面的链接。AMPLab基准测试也使用CALDA数据生成器。此外,TPC-E和TPC-DS都使用传统的合成均匀分布或高斯分布生成其大部分输入数据。另一方面,它们基于真实世界的数据生成一小部分关键输入数据。例如,TPC-E根据2000年美国和加拿大人口普查数据生成名称、地址、性别数据。GraphBIG提供了四个真实的固定大小的数据集(Twitter Graph,IBM Knowledge Repo,IBM Watson Gene Graph和CA Road Network)和一个合成的图生成器(Linked Data Benchmark Council (LDBC) Graph)生成具有社交网络功能的可伸缩图。
4.3 开放性挑战问题
现有大数据基准测试面临的一个主要问题是使用现成的数据集作为工作负载输入可以保证数据的准确性,但数据量和速度有限。另一方面,当生成不同数据量和速度的合成数据时,很难保证生成数据的真实性水平。在考虑不同的数据类型和来源(数据种类)时,这个问题更加复杂,此处有两个具有挑战性的关键问题。
第一个问题是现有的基准测试集可以构建模型来提取某些数据类型(如表格,文本和图数据)的真实数据集的特征,但是,他们很少关注其他数据类型,如流、图、视频和科学数据。此外,某些数据类型具有各种数据源,因此需要区分建模技术。例如,图数据至少有四个来源:社交网络、信息网络、自然网络和人造技术网络。但是,现有基准测试集仅提供了社交网络模型。我们注意到流数据和科学数据也面临数据源多样化和模型缺少的问题。
第二个同时也是更具挑战性的问题是如何评估产生的合成数据的真实性水平。恰当的的评估方法不仅允许基准测试集用户评估其测试结果的可靠性水平,而且还能管理数据生成器中已建立模型的有效性。但是,据我们了解,几乎没有基准测试集考虑过如何测量数据的真实性。在信息质量评估(IQA)框架中,一些理论研究量化大数据中内容的客观性、真实性和可信度,从而提供了描述和评估数据真实性的一般方法。例如,本研究使用基于共有信息的搭配分析来评估文本数据的真正性和可信度,从而能够分析真实文本数据与生成的合成数据之间的关系。因此,IQA框架为大数据基准测试集提供了基础,它可以用来开发具有数据真实性定量评估机制的合成数据生成器。
评估中的指标和性能参数
在本节中,我们首先总结了现有大数据基准测试中使用的评估指标(5.1节),如表5所示。 然后,我们讨论了在对大数据系统进行基准测试时要考虑的重要性能参数(5.2节)。
5.1 评价指标
目前,性能,价格和能耗是评估计算机系统的最常用指标。我们首先在第5.1.1节中介绍几种流行的性能指标,然后讨论第5.1.1节中的价格和能耗指标。
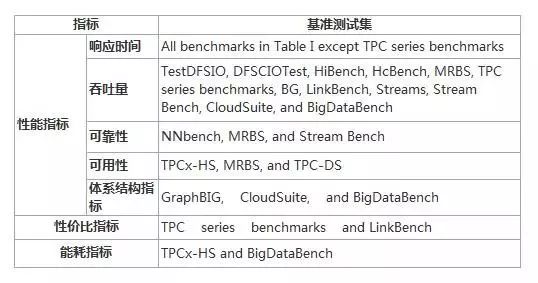
表5. 大数据基准评价标准总览表
5.1.1 性能指标
响应时间:该度量表示的是工作负载(如MapReduce作业或数据库查询)从提交到完成时刻之间的时间间隔。大多数大数据基准测试集都是计算响应时间的算术平均值。相比之下,LinkBench使用六个响应时间值:平均值,最大值,第50个,第75个,第95个和第99个百分点。其它一些基准测试则计算系统在某些约束下的响应时间。继承自Wisconsin Benchmark的YCSB使用两个指标测试云服务系统的扩展性能。第一个指标是机器数量增加时的查询响应时间。第二个指标是系统运行并增加时的响应时间。从社交网络的角度来看,BG提供了四个参数α,β,τ和δ,以将性能度量定义为响应时间等于或小于β的请求的百分比α,而这些不可预测的请求数据量小于δ分钟期间的τ百分比。
吞吐量:在大多数情况下,该指标表示处理的查询/作业数量的平均值或每单位时间的平均处理数据量(例如1秒或1小时)。TPC系列基准测试使用吞吐量作为OLTP系统(TPC-C和TPC-E)、DSS(TPC-H,TPC-DS和TPC-DI)和虚拟化系统(TPC-VMS)的性能指标。 在用于测试HDFS的TestDFSIO和DFSCIOTest中,吞吐量通过每个文件的I / O速率(MB /秒)的平均值和标准差计算。
可靠性:在NNbench和MRBS中,该标准分别表示成功的文件操作比率和MapReduce客户端请求的比率。此外,Stream Bench引入了两个惩罚度量来评估系统的可靠性:(1)吞吐量惩罚因子是故障吞吐量除以没有故障的吞吐量。该因子小于或等于1; (2)延迟惩罚因子:故障延迟除以没有故障的延迟。该因子大于或等于1。
可用性:在TPCx-HS,MRBS和TPC-DS中,该标准表示系统可用时间的比率。
上述四个指标是用户可感知的可观察到的指标。相比之下,体系结构指标是用于评估微架构级别系统的不可观察的性能指标。因此,这些指标独立于软件系统,用于测试硬件架构的性能。在当前的基准测试中(例如CloudSuite,BigDataBench和GraphBIG),有三种类型的体系结构指标:(1)执行周期划分。 CloudSuite将工作负载执行时间从两个维度划分为:应用程序时间和操作系统时间,指令提交时间和停滞时间。 BigDataBench将执行指令分为五种类型:整数、浮点、分支、存储和加载。 GraphBIG将CPU执行周期分为四个部分:前端停顿,后端停顿,休眠和不良推测(frontend stall, backend stall, retiring, and bad speculation)。(2)处理器计算强度。这些指标包括每个周期的指令数(IPC),每秒百万条指令数(MIPS),每秒百万次浮点运算数(MFLOPS)以及计算与访存的比率。(3)内存分级结构。这些指标包括cache未命中情况,指令转换检测缓冲区(ITLB)和数据转换检测缓冲区(DTLB)在不同级别的未命中情况。这些未命中情况通常当作miss-per-Kilo-instruction(MPKI)来计算。此外,GraphBIG使用两个发散指标来衡量GPU平台:分支发散率(每个warp中未激活线程的平均比率)和内存发散率(重放指令的比例)。
5.1.2 价格和能耗指标
性价比指标:该指标评估被测系统(SUT)价格对系统性能的影响。例如,在TPC-C和TPC-DS中,价格/性能的指标是用每分钟一个事务所用的美元数(tpm)(例如10美元/ 1000转/分)表示。在LinkBench中,该指标是每美元产生的峰值吞吐量。 在TPC-Pricing中提供了一种通用方法,通过综合考虑价格的不同来源(包括硬件(购买价格)、软件(许可证费用)、3年维护费用以及市场上合适的折扣)来计算SUT的定价配置。使用定价配置可以定义价格/性能指标。
能耗指标:TPC在2007年提出能耗规范来计算SUT的能耗,它考虑了系统组件的功率及其环境(包括温度,湿度和海拔高度)。TPC还提供被称为能耗测量系统的软件包以促进其能耗规范的实施和能耗/性能指标的定义。根据TPC基准测试标准,TPCx-HS使用TereSort作为示例工作负载来讨论如何为大数据系统设计能耗指标。TPC-E提出了一种能耗/性能指标,其测量每秒一个事务消耗功率的瓦特数(tps)(例如32瓦/ 10吨)。BigDataBench还提供能耗性能指标用于计算MapReduce作业的每焦耳处理的数据量。类似地,SPEC也通过开发服务器效率评级工具(SERT)来计算单节点或多节点服务器的能耗。基于此工具,SPEC开发了一个名为SPECpower-ssj2008的基准测试,它使用一个功率分析仪,一个温度传感器和一个控制器系统来测量系统能耗。
5.2 大数据系统性能参数的讨论
在大数据系统上运行工作负载时,有三个原因使各种参数影响大数据性能。首先,大数据系统通常具有比传统系统(如MPI)更复杂的软件栈和层,因此有很多配置参数。其次,许多大数据系统支持多种编程语言,如C、Java和Python。程序的属性在不同的语言中变化很大,因此引入了更多的配置参数。最后,在分布式和共享环境(例如Amazon Web Services等公共云)中执行工作负载时,资源分配参数的设置(例如CPU和内存资源的分配以及网络资源的预留)也会影响工作负载的性能。
到目前为止,尽管人们为改善科研和工业中大数据系统的性能做出了许多努力,但我们回顾的大多数大数据基准测试在测试时仅使用默认参数设置。然而这不能保证公平的基准测试,因为从程序代码、输入数据、资源属性等方面来看,在不同系统上,工作负载性能参数的最佳组合也不同。随着新的大数据基准测试的开发,基准测试设计师需要认识到性能参数及其影响,需要考虑如何使基准测试公平而且不会失去根据被测系统来自定参数的自由。我们简要总结了未来基准测试中要考虑的重要性能参数(至少在作者们看来),具体如下:
系统配置参数。大数据系统中大量软件栈和多种编程语言的使用会带来大量的配置参数。例如,在Hadoop中,有三类基本的配置参数用于控制MapReduce作业的执行:(1)作业中map和reduce任务的数量;(2)map和reduce任务中可用间隙的数量以及这些间隙的资源配置(即处理器的数量和存储量);(3)数据传输机制,例如map任务的输出是否在存储之前被压缩。上述参数的设置也可以称为执行计划配置。在Hadoop中,用户需要为其工作运行指定的执行计划参数(系统配置参数),而在一些其他系统(如Hive和Pig或某些数据库引擎)中则可以自动生成执行计划配置。
除了系统配置参数之外,人们还提出了调度技术来提高MapReduce工作在Hadoop相关系统上的性能。这些技术通过考虑三个性能参数来管理并发运行作业的执行,以减少其总体完成时间:作业资源共享的公平性; map和reduce任务之间的依赖关系;作业执行中的数据位置(在输入数据所在处运行任务)。此外,由于网络带宽比机器中的磁盘带宽小得多,人们引入了一些技术来减少MapReduce作业的网络负载和通信成本。这些技术通过耦合数据和虚拟机(VM)的位置来改善数据位置,或者关注于通过管理作业内和作业间的传输活动来减少shuffling流量。
资源分配参数。当数据中心中部署大数据系统时,计算和网络资源由不同系统的工作负载共享。因此CPU和内存资源的分配以及网络资源的保留机制都是要考虑的性能参数。
瓶颈缓解参数。如今,在许多大数据系统中(例如Hadoop和数据存储),作业的处理分为数百或数千个并行处理任务。因此瓶颈任务(即任务花费最长时间完成的任务)会极大地影响系统的性能。针对这样的问题,人们提出了许多方法来减轻瓶颈任务的影响,这些方法通常根据其考虑的性能参数分为三类:(1)解决瓶颈的特定硬件/软件来源,如动态电压和频率调节(DVFS)、OS内核和系统软件; (2)提高并行度; (3)为所有任务提交冗余副本或只为掉队任务重复提交冗余副本,然后使用其最快副本来减少其完成时间。
总结
在本文中,我们全面回顾了当前开源大数据系统基准测试集。首先,我们介绍了大数据系统和基准测试集的基本概念,之后回顾了基准测试核心技术(工作负载生成技术,输入数据生成技术以及评测指标和性能参数)。随后,我们分别根据三种技术对基准测试集进行了分类。最后,考虑到大数据基准测试集的不断发展,本文还讨论了亟待解决的开放性挑战问题,以期推动大数据基准测试集向着真正可信、可用和公平的方向发展。
-
开源
+关注
关注
3文章
2985浏览量
41716 -
大数据
+关注
关注
64文章
8649浏览量
136587
原文标题:从技术上解读大数据的应用现状和开源未来
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
未来,是大数据的时代
大数据主导着未来
Dubbo开源现状与未来规划
DKHadoop大数据平台架构详解
阿里巴巴高级技术专家章剑锋:大数据发展的 8 个要点
一文带你解读全球人工智能产业发展现状





 工商网监
工商网监
评论