 一个深度学习模型能完成几项NLP任务?
一个深度学习模型能完成几项NLP任务?
在很多人眼里,Salesforce也许是个陌生的名字,但它实际上是可以比肩微软和甲骨文的科技巨头。和众多专注个体消费者服务的公司不同,Salesforce的主营业务是CRM系统,这也是它当年迫于股东压力放弃收购Twitter的一大因素。近年来,眼看竞争对手依靠AI技术取得巨大成功,坐拥大量优质数据、成立了人工智能平台Einstein的Salesforce自然也不甘落后。今天,论智带来的是Einstein研究所的新成果:一个十项全能的NLP深度学习模型。
对于机器翻译、文本摘要、Q&A、文本分类等自然语言处理任务来说,深度学习的出现一遍遍刷新了state-of-the-art的模型性能记录,给研究带来诸多惊喜。但这些任务一般都有各自的度量基准,性能也只在一组标准数据集上测试,这就导致一个问题:即便这些模型在单个NLP任务中表现良好,但它们的基准设计和架构发展并不一定会对NLP全能模型的发展带去积极影响。
为了探索这些模型的更多可能性,以及优化它们的权重,我们引入decaNLP:自然语言十项全能多任务挑战(同样是个大型数据集)。这个挑战包含十项任务:Q&A、机器翻译、摘要、自然语言推断、情感分析、语义角色标注、关系抽取、任务驱动多轮对话、数据库查询生成器和代词消解。它的目标是找到可以高质量完成以上10种任务的模型,并探究这些模型与针对特定任务单独训练的模型之间的不同。
为了方便比较,decaNLP使用了一个名为decaScore的基准。
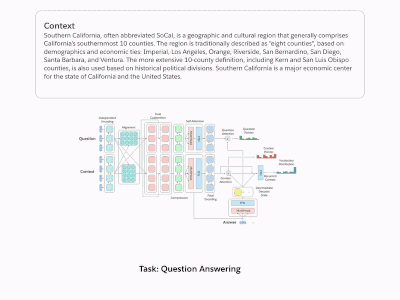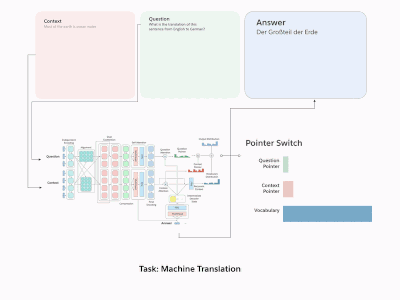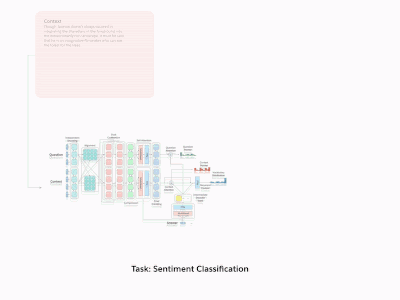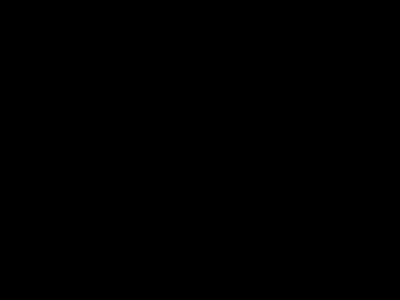
通过把这十项任务统一转化成问答模式,这就成了一个大型Q&A模型
针对这项挑战,我们的具体做法是把这十项任务都转换为问题和答案,并提出一个新的多任务问答网络(MQAN),它可以在无需任何特定任务模块、参数的情况下同时学习这十项任务。经过实验,MQAN得到了一些有趣发现:机器翻译和命名实体识别模型间可以进行迁移学习、情感分析和自然语言推断有相似的域……
通过比较基准,我们发现MQAN的多指针编码器-解码器结构是它成功的一大关键,而且相反的训练策略可以进一步提高网络性能。尽管MQAN的定位是NLP全能模型,但它在单一任务中的表现也可圈可点。总而言之,它在WikiSQL语义解析任务中取得了state-of-the-art的成果,在SQuAD上得分最高,在其他任务中也表现出众。
任务及数据集
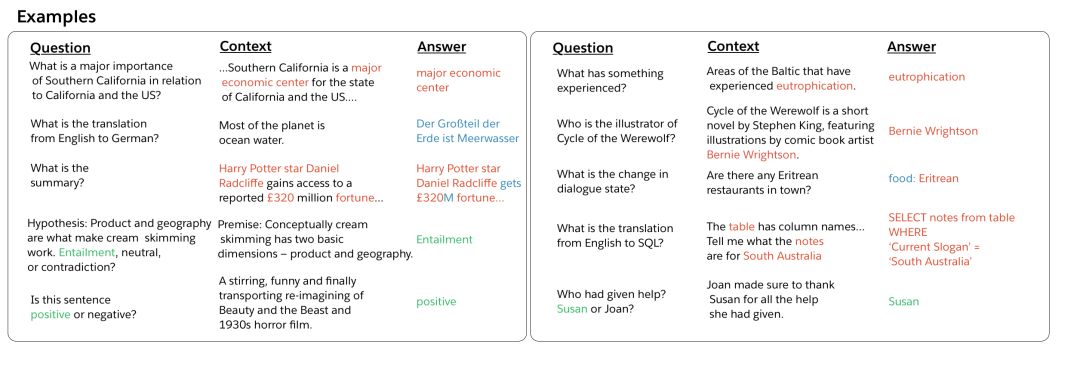
问题、文本、答案:十项NLP任务
首先我们来看看任务和相关数据集,这块内容在论文中有更详细的介绍,包括每个任务的历史背景和近期进展情况,这里我们不再赘述。上图是每个任务输入输出对的一些样本。
Q&A
问答模型的输入由问题和上下文两部分组成,其中包含输出答案所需的信息。对于这个任务,我们使用的是斯坦福问答数据集(SQUAD),上下文截取自英语维基百科的段落,而答案则是从上下文中复制的单词序列。
机器翻译
机器翻译的输入是源语言文本,输出是翻译好的目标语言。我们在这里把2016年国际口语机器翻译评测比赛(IWSLT)中的英译德数据作为训练集,并把2013年、2014年比赛的数据作为验证集和测试集。输入样本来自转录的TED演讲,因为它涵盖了大多数自然语言会话主题。虽然对机器学习来说这个数据集有点小,但它的大小上和其他任务的数据集基本一致。
decaNLP没有对额外数据的限制,所以如果你愿意,你还可以引入更多数据,比如WMT的会议翻译数据。
摘要
这类任务要求输入文本后,模型能输出该文本的摘要。近几年来不少研究人员把CNN(美国有线电视新闻网)和《每日邮报》语料库汇总成数据集,并在这个基础上取得了不少重大进展。我们也为decaNLP挑战引入了这个数据集的非匿名版本。
自然语言推断
自然语言推断(NLI)模型接收两个输入句子:一个前提和一个假设。模型需要推断前提和假设之间的关系,并把它归类为矛盾、中性、支持三者之一。我们用的是斯坦福大学的Multi-Genre NLI Corpus(MNLI)数据集,它是SNLI的升级版,提供多领域(语音转录、流行小说、政府报告)训练样本。
情感分析
情感分析的任务是输入文本后,输出文本所表达的情绪。斯坦福大学的情绪树库(SST)是一个包含电影评论及其相应情绪(正面、中性、负面)的数据集,非常适合这类任务。我们使用的是它的二进制版本,以便decaNLP模型可以解析其中的依赖关系。
语义角色标注
语义角色标注(SRL),即输入句子和谓语(通常是动词),输出语义角色间的关系:何时何地,“谁”对“谁”做了什么。我们把一个SRL数据集处理成问答形式,制作了一个新数据集:QA-SRL,它的内容涵盖新闻和维基百科。
关系抽取
关系抽取的目的是从输入文本中提取属于目标种类的实体关系。在这种情况下,模型需要先识别实体间的语义关系,再判断是不是属于目标种类。和SRL一样,我们也为这项任务制作了一个新数据集:QA-ZRE。它把实体关系映射到一系列问题,所以抽取过程就也成了问答形式。
任务驱动多轮对话
在人机对话系统中,任务驱动多轮对话的一个关键是对话状态跟踪,也就是根据用户发言和机器人的反应确定用户的明确目的,比如订餐、订票、购买商品等,它也可以追踪交流过程中用户提出的请求类型。对于这项任务,我们用的是英文版的WoZ订餐任务,它包含订餐食物实体、日期、时间、地址以及其他信息。
语义分析
从本质上说,把自然语言翻译成SQL再到数据库查询语句这个过程和语义分析密切相关。去年,我们曾在论文Seq2SQL中介绍过一种可以跳过SQL的方法,允许自然语言与数据库直接进行交互。所以这里用的还是当时的数据集WikiSQL。
代词消解
这个任务面向的是不图灵测试,而是威诺格拉德模式挑战,其中最典型的一个例题是:市议会拒绝给示威者颁发许可,因为他们[担心/宣扬]暴力。这里“担心”的主语是“市议会”,那么“宣扬”的主语是谁?我们从这个例子开始训练,确保最终答案来自上下文,但它的得分又不会被上下文的措辞所影响。
模型得分:decaScore
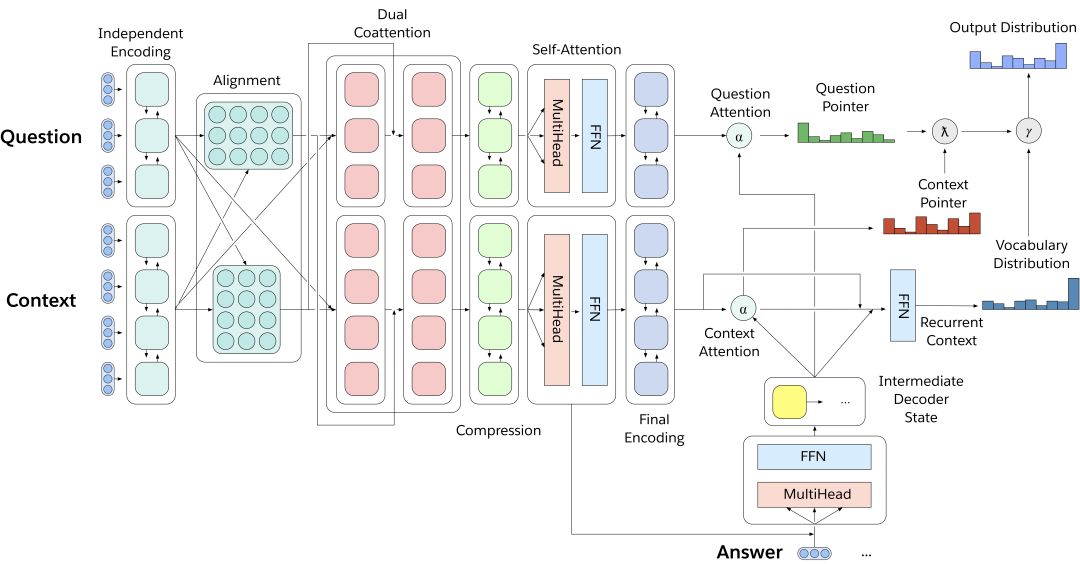
多任务问答网络(MQAN)
MQAN是一个多任务问答模型,只用一个深度学习神经网络就能解决decaNLP挑战的十项任务。它没有任何针对特定任务的参数和模块,如上图所示,输入问题和上下文文本后,模型用BiLSTM对输入进行编码,又用dual coattention分别调整两个序列的表征,之后用另外两个BiLSTM压缩所有信息,以便它们能被用于高层计算。后面添加的自我注意力模块能有效收集长期记忆,这些信息再被馈送进最后两个BiLSTM,得到问题和上下文的最终表征。
因为decaNLP是一个十项全能挑战,所以如果每项任务的评分基准是百分制,那它就应该是千分制——加法可以有效避免对不同任务的评分偏见。对于Q&A、自然语言推断、情感分析和语义角色标注,它们的评分基准是归一化的F1(nF1);摘要任务计算的是ROUGE-1、ROUGE-2和ROUGE-L得分的平均值;机器翻译用的是BLEU评分;任务驱动多轮对话用的是任务跟踪得分和请求跟踪得分的平均值……
除了MQAN,我们还尝试了其他结构的模型并计算了它们的decaScores,下面是具体评分情况:
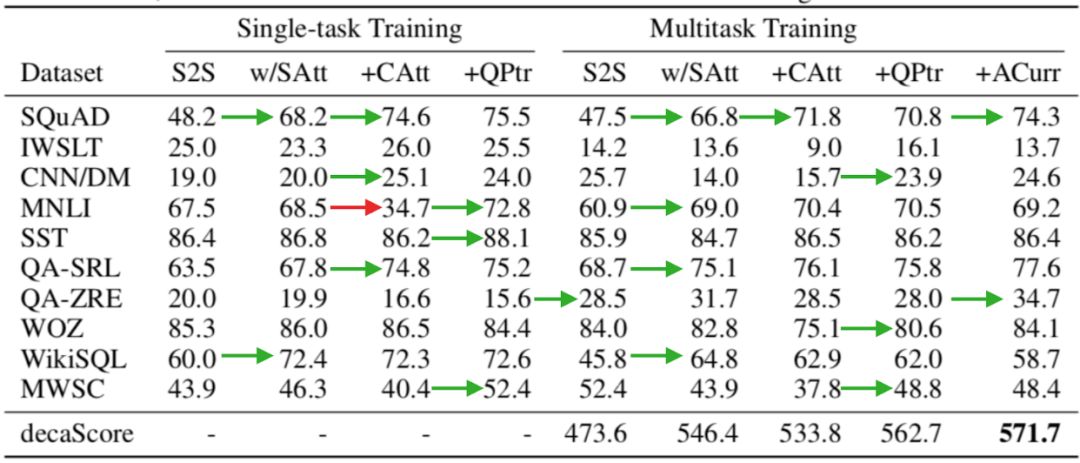
各模型评分结果
第一个S2S是一个包含注意力机制和指针生成器的序列到序列网络;第二个w/SAtt是S2S的衍生,它在编码器的BiLSTM和解码器的LSTM层之间加入了一层自我注意力模块(Transformer);+CAtt把上下文和问题分解成两个序列,并在编码器上添加了额外的层;MQAN事实上就是带额外问题指针的+CAtt,它在表格中被表示为+QPtr。
上表数据显示了模型在多任务和单任务之间的权衡:通过在S2S中加入额外的注意力模块,模型能更有效地从问题+上下文的单一序列中提取有效信息,从而极大地提高了它在SQUAD和WikiSQL上的性能;通过在前者基础上把上下文和问题作为单独的输入序列,模型在大多数任务上的表现更好了,但它在MNLI和MWSC两个数据集上却性能暴跌,这不难理解,自然语言推断和代词消解需要结合上下文和问题,它们一旦分离,模型就失效了;针对这个问题,+QPtr引入了一个额外指针,可以发现,这时模型在MNLI和MWSC上的性能比S2S更优。
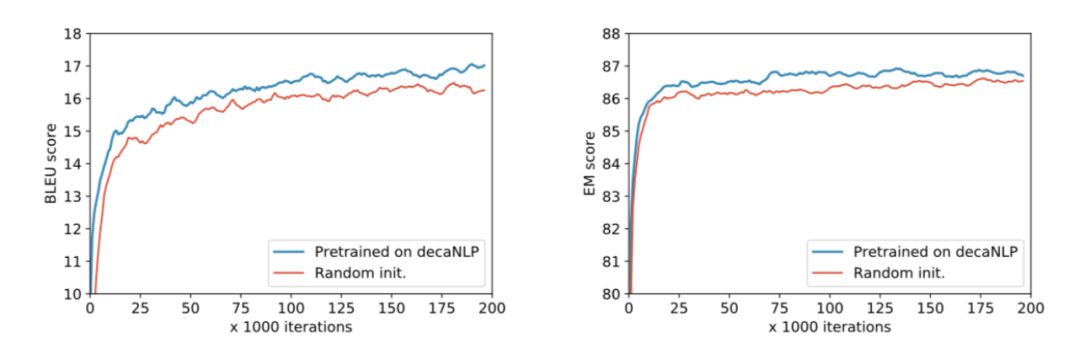
学习新任务时,MQAN预训练/直接训练的差距
-
深度学习
+关注
关注
73文章
5237浏览量
119908 -
nlp
+关注
关注
1文章
463浏览量
21820
原文标题:decaNLP:一个深度学习模型能完成几项NLP任务?
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
labview测试tensorflow深度学习SSD模型识别物体
专栏 | 深度学习在NLP中的运用?从分词、词性到机器翻译、对话系统
对2017年NLP领域中深度学习技术应用的总结
回顾2018年深度学习NLP十大创新思路
详解谷歌最强NLP模型BERT







 工商网监
工商网监
评论