 比谷歌快46倍!GPU助力IBM Snap ML,40亿样本训练模型仅需91.5秒
比谷歌快46倍!GPU助力IBM Snap ML,40亿样本训练模型仅需91.5秒
近日,IBM 宣布他们使用一组由 Criteo Labs发布的广告数据集来训练逻辑回归分类器,在POWER9服务器和GPU上运行自身机器学习库Snap ML,结果比此前来自谷歌的最佳成绩快了46倍。
英伟达CEO黄仁勋和IBM 高级副总裁John Kelly在Think大会上
最近,在拉斯维加斯的IBM THINK大会上,IBM宣布,他们利用优化的硬件上的新软件和算法,取得了AI性能的大突破,包括采用 POWER9 和NVIDIA®V100™GPU 的组合。
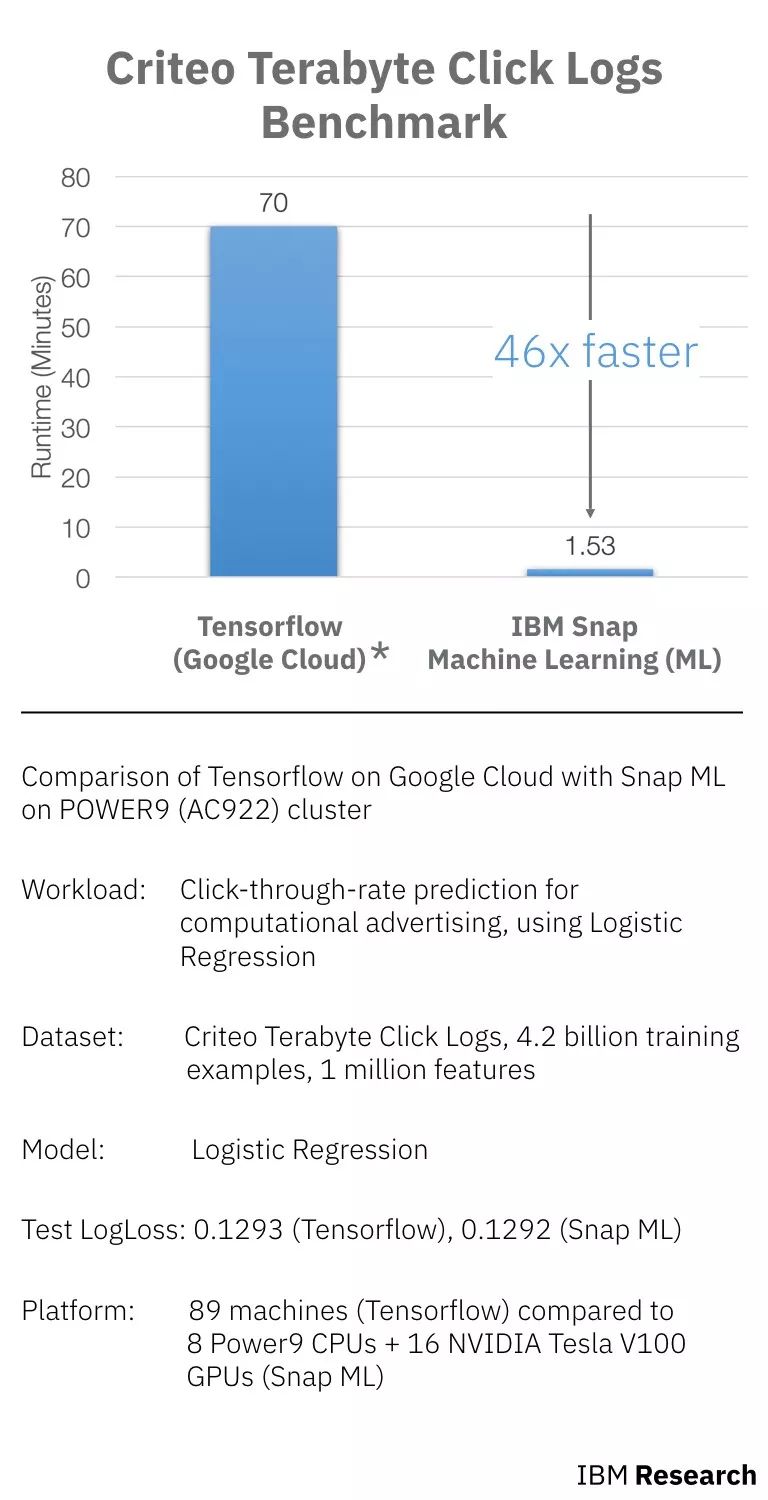
谷歌云上TensorFlow和POWER9 (AC922)cluster上IBM Snap的对比(runtime包含数据加载的时间和训练的时间)
如上图所示,workload、数据集和模型都是相同的,对比的是在Google Cloud上使用TensorFlow进行训练和在Power9上使用Snap ML训练的时间。其中,TensorFlow使用了89台机器(60台工作机和29台参数机),Snap ML使用了9个 Power9 CPU和16个NVIDIA Tesla V100 GPU。
相比 TensorFlow,Snap ML 获得相同的损失,但速度快了 46 倍。
怎么实现的?
Snap ML:居然比TensorFlow快46倍
早在去年二月份,谷歌软件工程师Andreas Sterbenz写了一篇关于使用谷歌Cloud ML和TensorFlow进行大规模预测广告和推荐场景的点击次数的博客。
Sterbenz训练了一个模型,以预测在Criteo Labs中显示的广告点击量,这些日志大小超过1TB,并包含来自数百万展示广告的特征值和点击反馈。
数据预处理(60分钟)之后是实际学习,使用60台工作机和29台参数机进行培训。该模型花了70分钟训练,评估损失为0.1293。
虽然Sterbenz随后使用不同的模型来获得更好的结果,减少了评估损失,但这些都花费更长的时间,最终使用具有三次epochs(度量所有训练矢量一次用来更新权重的次数)的深度神经网络,耗时78小时。
但是IBM在POWER9服务器和GPU上运行的自身训练库后,可以在基本的初始训练上胜过谷歌Cloud Platform上的89台机器。
他们展示了一张显示Snap ML、Google TensorFlow和其他三个对比结果的图表:
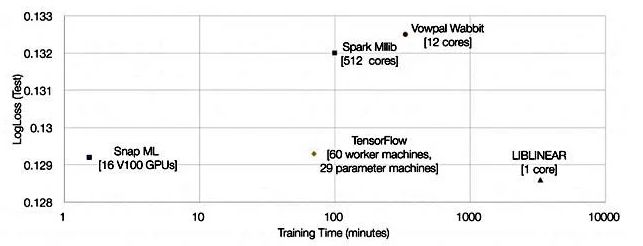
比TensorFlow快46倍,是怎么做到的?
研究人员表示,Snap ML具有多层次的并行性,可以在集群中的不同节点间分配工作负载,利用加速器单元,并利用各个计算单元的多核并行性。
1. 首先,数据分布在集群中的各个工作节点上。
2. 在节点上,数据在CPU和GPU并行运行的主CPU和加速GPU之间分离
3. 数据被发送到GPU中的多个核心,并且CPU工作负载是多线程的
Snap ML具有嵌套的分层算法(nested hierarchical algorithmic)功能,可以利用这三个级别的并行性。
简而言之,Snap ML的三个核心特点是:
分布式训练:Snap ML是一个数据并行的框架,能够在大型数据集上进行扩展和训练,这些数据集可以超出单台机器的内存容量,这对大型应用程序至关重要。
GPU加速:实现了专门的求解器,旨在利用GPU的大规模并行架构,同时保持GPU内存中的数据位置,以减少数据传输开销。为了使这种方法具有可扩展性,利用最近异构学习的一些进步,即使可以存储在加速器内存中的数据只有一小部分,也可以实现GPU加速。
稀疏数据结构:大部分机器学习数据集都是稀疏的,因此在应用于稀疏数据结构,对系统中使用的算法进行了一些新的优化。
技术过程:在91.5秒内实现了0.1292的测试损失
先对Tera-Scale Benchmark设置。
Terabyte Click Logs是由Criteo Labs发布的一个大型在线广告数据集,用于分布式机器学习领域的研究。它由40亿个训练样本组成。
其中,每个样本都有一个“标签”,即用户是否点击在线广告,以及相应的一组匿名特征。基于这些数据训练机器学习模型,其目标是预测新用户是否会点击广告。
这个数据集是目前最大的公开数据集之一,数据在24天内收集,平均每天收集1.6亿个训练样本。
为了训练完整的Terabyte Click Logs数据集,研究人员在4台IBM Power System AC922服务器上部署Snap ML。每台服务器都有4个NVIDIA Tesla V100 GPU和2个Power9 CPU,可通过NVIDIA NVLink接口与主机进行通信。服务器通过Infiniband网络相互通信。当在这样的基础设施上训练逻辑回归分类器时,研究人员在91.5秒内实现了0.1292的测试损失。
再来看一遍前文中的图:
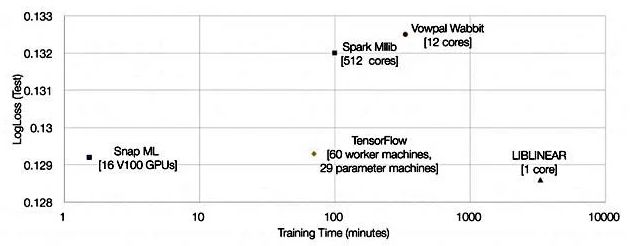
在为这样的大规模应用部署GPU加速时,出现了一个主要的技术挑战:训练数据太大而无法存储在GPU上可用的存储器中。因此,在训练期间,需要有选择地处理数据并反复移入和移出GPU内存。为了解释应用程序的运行时间,研究人员分析了在GPU内核中花费的时间与在GPU上复制数据所花费的时间。
在这项研究中,使用Terabyte Clicks Logs的一小部分数据,包括初始的2亿个训练样本,并比较了两种硬件配置:
基于Intel x86的机器(Xeon Gold 6150 CPU @ 2.70GHz),带有1个使用PCI Gen 3接口连接的NVIDIA Tesla V100 GPU。
使用NVLink接口连接4个Tesla V100 GPU的IBM POWER AC922服务器(在比较中,仅使用其中1个GPU)。
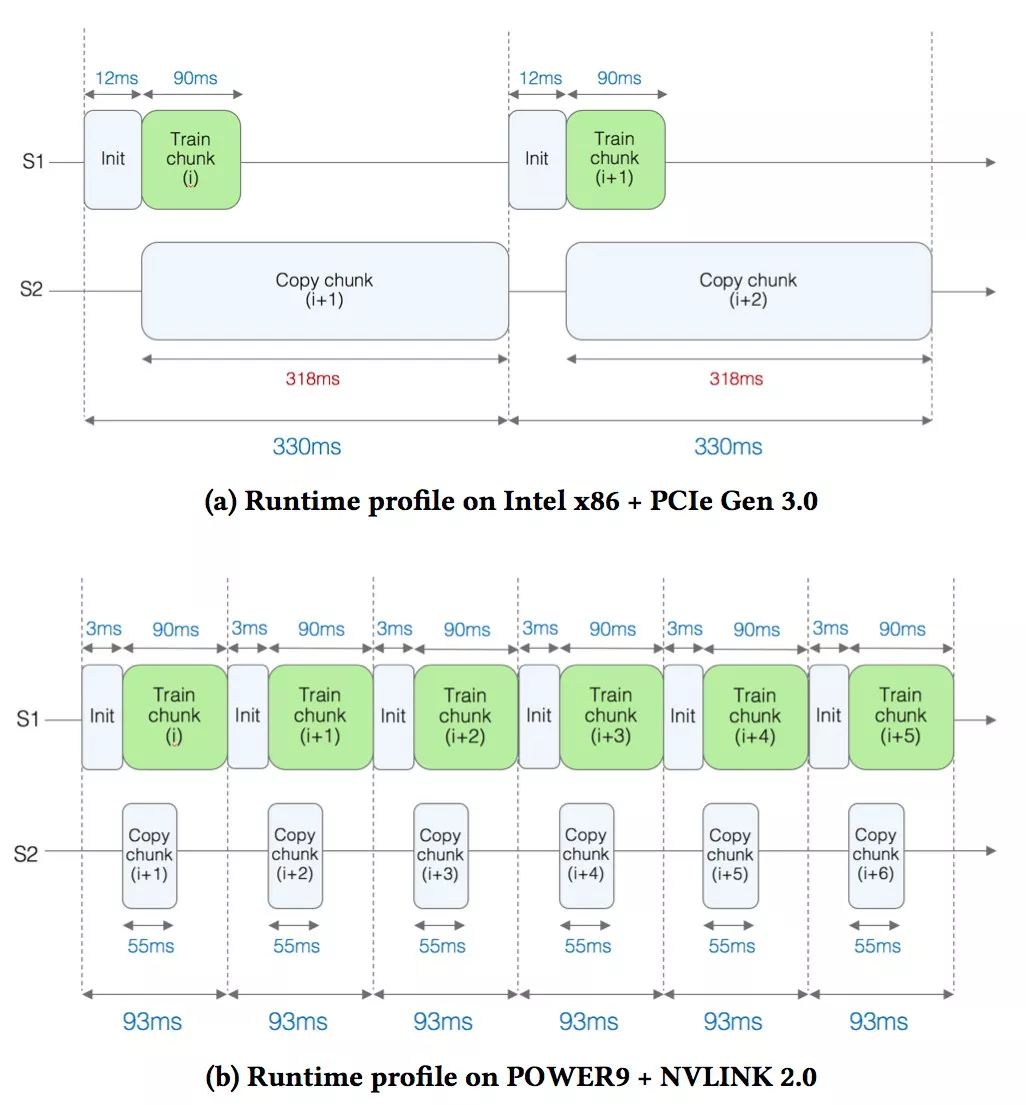
图a显示了基于x86的设置的性能分析结果。可以看到S1和S2这两条线。在S1线上,实际的训练即将完成时(即,调用逻辑回归内核)。训练每个数据块的时间大约为90毫秒(ms)。
当训练正在进行时,在S2线上,研究人员将下一个数据块复制到GPU上。观察到复制数据需要318毫秒,这意味着GPU闲置了相当长的一段时间,复制数据的时间显然是一个瓶颈。
在图b中,对于基于POWER的设置,由于NVIDIA NVLink提供了更快的带宽,因此下一个数据块复制到GPU的时间显著减少到55 ms(几乎减少了6倍)。这种加速是由于将数据复制时间隐藏在内核执行后面,有效地消除了关键路径上的复制时间,并实现了3.5倍的加速。
IBM的这个机器学习库提供非常快的训练速度,可以在现代CPU / GPU计算系统上训练流主流的机器学习模型,也可用于培训模型以发现新的有趣模式,或者在有新数据可用时重新训练现有模型,以保持速度在线速水平(即网络所能支持的最快速度)。这意味着更低的用户计算成本,更少的能源消耗,更敏捷的开发和更快的完成时间。
不过,IBM研究人员并没有声称TensorFlow没有利用并行性,并且也不提供Snap ML和TensorFlow之间的任何比较。
但他们的确说:“我们实施专门的解决方案,来利用GPU的大规模并行架构,同时尊重GPU内存中的数据区域,以避免大量数据传输开销。”
文章称,采用NVLink 2.0接口的AC922服务器,比采用其Tesla GPU的PCIe接口的Xeon服务器(Xeon Gold 6150 CPU @ 2.70GHz)要更快,PCIe接口是特斯拉GPU的接口。“对于基于PCIe的设置,我们测量的有效带宽为11.8GB /秒,对于基于NVLink的设置,我们测量的有效带宽为68.1GB /秒。”
训练数据被发送到GPU,并在那里被处理。NVLink系统以比PCIe系统快得多的速度向GPU发送数据块,时间为55ms,而不是318ms。
IBM团队还表示:“当应用于稀疏数据结构时,我们对系统中使用的算法进行了一些新的优化。”
总的来说,似乎Snap ML可以更多地利用Nvidia GPU,在NVLink上传输数据比在x86服务器的PCIe link上更快。但不知道POWER9 CPU与Xeons的速度相比如何,IBM尚未公开发布任何直接POWER9与Xeon SP的比较。
因此也不能说,在相同的硬件配置上运行两个suckers之前,Snap ML比TensorFlow好得多。
无论是什么原因,46倍的降幅都令人印象深刻,并且给了IBM很大的空间来推动其POWER9服务器作为插入Nvidia GPU,运行Snap ML库以及进行机器学习的场所。
-
谷歌
+关注
关注
27文章
5855浏览量
103250 -
神经网络
+关注
关注
42文章
4572浏览量
98737 -
gpu
+关注
关注
27文章
4416浏览量
126668
原文标题:比谷歌快46倍!GPU助力IBM Snap ML,40亿样本训练模型仅需91.5 秒
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大模型训练为什么不能用4090显卡,GPU训练性能和成本对比

matlab自学一本通(新版软件+基础教程+案例源码)
Pytorch模型训练实用PDF教程【中文】
在Ubuntu上使用Nvidia GPU训练模型
怎样使用PyTorch Hub去加载YOLOv5模型
Mali GPU支持tensorflow或者caffe等深度学习模型吗
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?
谷歌云端可抢占GPU,普遍降价40%

GPU如何训练大批量模型?方法在这里
一个GPU训练一个130亿参数的模型





 工商网监
工商网监
评论