 多模态机器学习的图像语言转换器
多模态机器学习的图像语言转换器
对于 AI 系统来说,将语言与视觉联系起来是它需要面对并学会解决的基本问题,例如在进行图像的检索时,AI 系统需要既能识别图像,也能识别语言,并将二者相关联起来。
对于这类需要 AI 系统识别不同种类或形式的信息来源的任务中,就需要多模态机器学习(MML/Multimodal Machine Learning)来发挥作用。所谓模态,指的是一种信息的来源或形式,例如文字、图像、视频、音频等都是模态。多模态机器学习是指利用机器学习来处理多种模态的信息。
近些年来,在多模态机器学习领域中,多模态图像语言转换器(Multimodal image–language transformers)已经取得了深刻进展,尤其在解决各种需要微调的任务,如视觉问答、图像检索中发挥了关键性作用。
但是,在既需要处理图像又需要处理语言文本的多模态机器学习任务中,有一类问题对于多模态图像语言转换器来说尤其棘手,那就是对文本中的动词的理解。例如要求 AI 系统来在图像中区分识别找出“踢球”和“抛球”这两种情景。在这一任务中,AI 系统不仅需要识别出图像中的“球”这一对象,还需要识别图像中不同对象之间的关系。
为了评估近年来多模态图像语言转换器的预训练水平,尤其是在“看图理解”中对于上文所说的动词的识别能力。近日,DeepMind 开发出一套方法,并引入了名为 SVO-Probes 的“图像-句子对” 数据集,来评估不同 AI 系统的多模态预训练模型对于动词的理解水平,尤其是了解这些 AI 系统多模态转换器的预训练模型在结合语言文本来识别图像时,到底是既能够识别中图片中的物体、也能区分中图像中的动作,还是只能够识别出图中的物体。
为了达到这一目的,DeepMind 建立的 SVO-Probes 数据集包含了 48000 个图像-句子对,可以测试 AI 系统对 447 个动词的理解,这些动词要么是视觉可以区分的,要么是在预训练数据中常见的,例如许多概念字幕数据集。这个数据集中的每个句子都可以分解成 一个 <主语、动词、宾语> 三元组,也就是 SVO 三元组,并分别配对有与句子描述的内容相符和不符的图像,它们在是实验中分别被称为“正实例图像” 和 “负实例图像”。

图|评估多模态语言图像转换器对于动词的识别能力的 SVO- Probes 数据集中的图像-句子对(来源:DeepMind)
上图显示了图像-句子对的几个例子,以左上角的图像-句子对为例,分别显示了与句子“孩子、过、马路”相符的正示例图像,以及与“女士、过、马路”不符的负示例图像,通过这一对可以测试 AI 系统识别图中的对象——也就是名词的能力;而上方中间的图像-句子对,则分别显示了”人、唱歌、演唱会上“ 的正示例图像和”“人、跳舞、演唱会上“ 的负示例图像。通过这一对就可以既测试 AI 系统识别图中的名词的能力,也能测试 AI 识别动词的能力。
在实验中使用这一 SVO-Probes 数据集以零样本的方式对 AI 预训练模型进行评估之后,DeepMind 的工程师发现,相比名词等其他词性,预训练模型在需要动词理解的情况下错误率要高很多。
下面的条形图详细说明了测试的结果。标准多模态转换器模型经过测试后总体准确率达到 64.3%,这也显示了 SVO- Probes 数据集确实具有挑战性。而这一 AI 模型在对于主语和宾语判断的准确率分别为 67.0% 和 73.4%,但是对于动词判断的准确率却下降到 60.8%。这一结果表明,动词识别确实对 AI 系统模型具有挑战性。
此外,该公司的工程师们还进一步总结调查了哪些类别的动词对于这些 AI 预训练模型尤其具有挑战性。结果发现,像“抓”这样的运动性动词以及“带领”这样在不同类型的语境中经常出现的动词对于 AI 来说更容易。而 AI 模型判断的正确率最高的动词有“打斗”“包围”“滑雪”“参加”等;而错误率最高的几个动词有“切”“争论”“断”等。
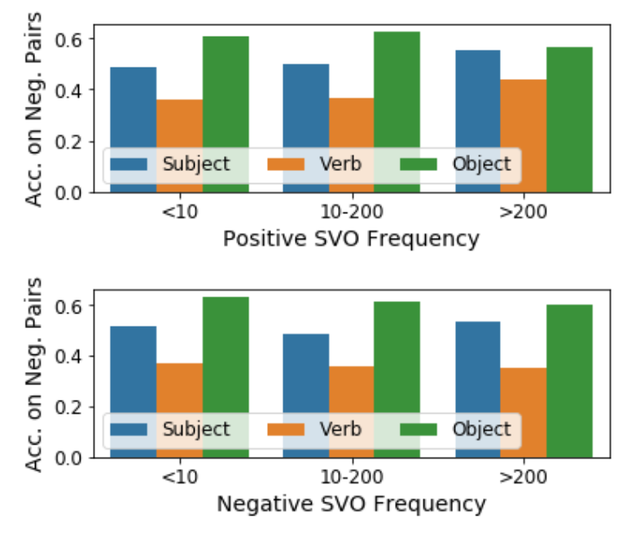
图|多模态机器学习的图像语言转换器对于 SVO-Probes 数据集进行判断测试之后的结果(来源:DeepMind)
值得一提的是,当工程师们对哪些模型架构在 SVO-Probes 数据集上的表现更好这一问题进行探索时,他们惊讶地发现,相比图像建模能力更强的标准图像语言转换器模型,那些图像建模较弱的模型反而表现更好。对这一与直觉相反的发现的解释的一个假设是,标准转换器模型在图像识别方面可能有些“过度训练”了。
审核编辑 :李倩
-
转换器
+关注
关注
27文章
8213浏览量
142017 -
AI
+关注
关注
87文章
26485浏览量
264130 -
数据集
+关注
关注
4文章
1179浏览量
24366
原文标题:AI多模态图像语言转换器在看图理解中对动词的识别力
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
韩国Kakao宣布开发多模态大语言模型“蜜蜂”
机器人基于开源的多模态语言视觉大模型

自动驾驶和多模态大语言模型的发展历程


用语言对齐多模态信息,北大腾讯等提出LanguageBind,刷新多个榜单


python机器学习概述
机器学习可以分为哪几类?机器学习技术有哪些?
更强更通用:智源「悟道3.0」Emu多模态大模型开源,在多模态序列中「补全一切」

用图像对齐所有模态,Meta开源多感官AI基础模型,实现大一统

邱锡鹏团队提出具有内生跨模态能力的SpeechGPT,为多模态LLM指明方向

多模态GPT:国内发布一款可以在线使用的多模态聊天机器人!

ImageBind:跨模态之王,将6种模态全部绑定!






 工商网监
工商网监
评论