 TFRT为ML模型提供更快、更便宜的执行
TFRT为ML模型提供更快、更便宜的执行
大约两年前,我们发布了一项全新机器学习 (ML) 运行时工作:TFRT(TensorFlow 运行时的简称)。同时,我们提供了初始技术设计的深度教程,并将其代码库开源。
在 ML 生态系统趋势的推动下——模型越来越大,ML 被部署到更多样化的执行环境,以及跟上持续研究和模型创新的需求——我们启动了 TFRT,希望可以实现以下目标:
为 ML 模型提供更快、更便宜的执行
实现更灵活的部署
提供更多模块化的可扩展基础架构,以促进 ML 基础架构和建模方面的创新
本文,我们将分享截至目前所取得的进展、在过去两年的开发过程中收获的经验和教训,以及未来的规划。
目前所取得的进展
过去两年的开发主要集中于通过为用户启用 Google 最重要的内部工作负载(比如 Ads 和搜索),来实施和验证我们的想法。迄今为止,我们已经在 Google 内部广泛部署了 TFRT,用于各种训练和推断工作负载,并取得了很好的结果。
技术经验
我们是如何实现上述目标的?除了原始设计中的经验,我们还收获了一些有趣的技术经验:
首先,异步支持对于一些关键的工作负载(例如重叠计算和 I/O,以及驱动异构设备)十分重要,而快速同步执行对许多其他工作负载至关重要,包括小型“嵌入式”ML 模型。
我们花费了大量精力设计和改进 AsyncValue,这是 TFRT 中的一个关键低级抽象,它允许主机运行时异步驱动设备以及调用内核。由于它能够在主机和设备间重叠更多的计算和通信,从而可以使设备利用率提高。例如,通过将模型拆分为多个阶段并使用 TFRT 来将下一阶段的变量传输与当前阶段的 TPU 计算重叠,我们能够以高性能在一个 TPU 芯片上成功运行 80B 参数模型的批量推理。
另一方面,在应用进程中(而不是通过 RPC/REST 调用)调用嵌入在应用服务器里的小型 CPU 模型,对 Google 的一些来自用户的商业工作负载(例如 Ads)仍然十分重要。对于这些模型,TFRT 的异步优先内部设计一开始导致了性能和资源衰退。我们与 Ads 团队合作,通过使用同步解释器扩展 TFRT 设计以及实验性内存规划优化,成功解决了该问题,避免了内核执行期间的堆分配。我们正在努力将此扩展产品化。
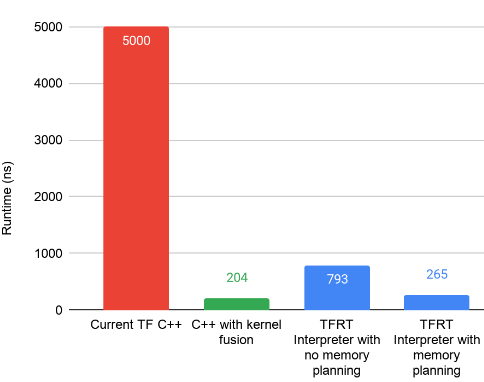
下图展示了由此产生的 TFRT 设计对基准测试的影响,通过与在部署 TFRT 之前运行旧运行时的“当前 TF”对比。这个基准测试专注于执行微型 CPU 模型,其中大量的小型 matmul 按顺序执行。值得注意的是,TFRT 中的优化执行 (265 ns) 正接近我们设置的最佳基线 (204 ns),它通过手写 C++ 代码执行,从而没有任何 ML 运行时开销。
其次,虽然更快的运行时执行很重要,但是优化输入程序以降低执行复杂度也很重要。
请注意,虽然应尽可能在将 TF SavedModel 保存到磁盘时执行基于编译器的图优化,但也有一些重要的推理时编译器优化只能在推理上下文中执行(例如,在训练变量保持不变时)。
当我们将 ML 模型加入 TFRT 时,我们可以在执行之前深入检查一些模型,并确定重写和简化程序的新方法。简化的程序,以及计算图程序中每个内核的更快速执行,在缩短执行延迟时间和减少资源成本方面产生了很好的复合效果。
例如,在下面左侧的计算图程序中,我们能够提升标量算子归一化计算(例如,将浮点值除以其域的最大值),这 18 个用于形成“concat”算子的输入标量均相同,因而我们对串联 1D 浮点张量启用归一化矢量执行。
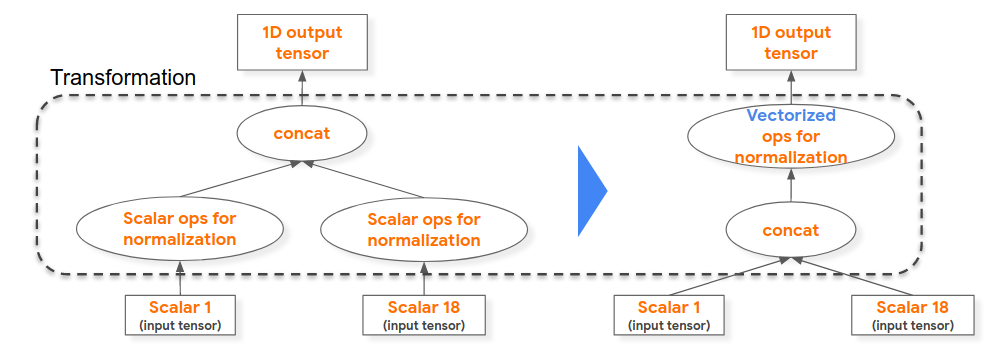
虽然也可以在模型训练时执行此优化,但用于生成训练模型的编译器+运行时不包括此优化。
此外,我们还发现,尽可能将计算从模型执行时间提升到加载时间至关重要(例如,const 折叠)。
再者,基于成本的执行不仅仅适用于 SQL 查询。
我们为 TF 算子内核开发了一个简单的编译时成本模型(类似于 SQL 查询优化器的成本模型),并为 ML 模型执行应用了基于成本的优化(参见流分析),同时在一组线程池线程间实现了更好的内核执行负载平衡。相比之下,TF1 有一个基于运行时的成本模型,其中每个操作的运行时成本都被分析并用于指导该操作的调度。在 TFRT 中,我们将成本分析移至编译时,从而消除了运行时成本。此外,我们的编译器方法可以分析整个计算图,从而产生在更全局范围内最佳的调度决策。
有关数据和 ML 基础架构之间的更多相似之处,请观看此技术讲座。
展望未来
虽然我们确实取得了一些不错的进展,尤其是在我们的第一个目标,即追求更快更经济的执行上,但我们承认,在实现更模块化的设计和通过硬件集成实现更灵活的部署方面,仍道阻且长。
在模块化方面,随着 JAX 采用 TFRT 设备运行时(例如 CPU)等初始集成成功,我们将继续探索 TFRT 可以如何支持 TensorFlow 之外的工作负载。我们希望部分 TFRT 组件未来也将有利于 PyTorch/XLA 工作负载的发展。
此外,我们成功集成了 CPU 和 TPU(下一步是集成到 Cloud TPU 中),即 Google 用于 ML 计算的两种最重要的设备类型,NVIDIA GPU 集成也正在进行中。
在训练工作负载方面,TFRT 已被用作 Google 大规模分布式训练框架的基本模块,目前正在积极开发中。
展望未来,我们的组织一直在探索与 Pixel 的硬件 SOC 设备(例如 Google Tensor)的集成。此外,由于 TFRT 已被成功证明可用于 Google 的内部工作负载,它也被集成到 GCP 的 Vertex AI 和 Waymo 等新场景。
特别致谢
TFRT 团队非常享受致力于在这个新基础架构项目上的工作。它让人感觉像是在引导一家新的初创公司。在此,我们想向在这非凡的 2 年旅程中为 TFRT 提供建议、作出贡献和给予支持的每个人高声致谢:
(按字母顺序)Adi Agrawal、Andrew Bernard、Andrew Leaver、Andy Selle、Ayush Dubey、Bangda Zhou、Bramandia Ramadhana、Catherine Payne、Ce Zheng、Chiachen Chou、Chao Xie、Christina Sorokin、Chuanhao Zhuge、Dan Hurt、Dong Lin、Eugene Zhulenev、Ewa Matejska、Hadi Hashemi、Haoliang Zhang、HanBin Yoon、Haoyu Zhang、Hongmin Fan、Jacques Pienaar、Jeff Dean、Jeremy Lau、Jordan Soyke、Jing Dong、Juanli Shen、Kemal El Moujahid、Kuangyuan Chen、Mehdi Amini、Ning Niu、Peter Gavin、Phil Sun、Pulkit Bhuwalka、Qiao Zhang、Raziel Alvarez、Russell Power、Sanjoy Das、Shengqi Zhu、Smit Hinsu、Tatiana Shpeisman、Tianrun Li、Tim Davis、Tom Black、Victor Akabutu、Vilobh Meshram、Xiao Yu、Xiaodan Song、Yiming Zhang、YC Ling、Youlong Chen 和 Zhuoran Liu。
我们还要特别感谢 Chris Lattner 在引导这个项目上提供的初始技术领导、Martin Wicke 在第一年对 TFRT 的支持、Alex Zaks 在第二年对 TFRT 的支持以及见证其有效地登陆 Google 的 ML 服务工作负载。
原文标题:TFRT 进展与更新
文章出处:【微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
审核编辑:汤梓红
-
嵌入式
+关注
关注
4982文章
18286浏览量
288479 -
Google
+关注
关注
5文章
1714浏览量
56792 -
cpu
+关注
关注
68文章
10444浏览量
206566
原文标题:TFRT 进展与更新
文章出处:【微信号:Google_Developers,微信公众号:谷歌开发者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
更快更便宜,5G更适合物联网应用
如何让包含嵌入式软件的复杂电子设备更便宜更可靠?
eIQ软件对ML模型有何作用
介绍一种Arm ML嵌入式评估套件
如何将ML模型部署到微控制器?
CHERRY全新Viola轴体成本更低,打造更便宜的机械键盘
雷蛇发布更便宜的灵刃15,称价格无法拒绝
松下拟最早2021年试生产特斯拉更便宜的新型电池
TFRT的开源代码分析

NVIDIA创建physics-ML模型





 工商网监
工商网监
评论