 超大Transformer语言模型的分布式训练框架
超大Transformer语言模型的分布式训练框架
NVIDIA Megatron 是一个基于 PyTorch 的框架,用于训练基于 Transformer 架构的巨型语言模型。本系列文章将详细介绍Megatron的设计和实践,探索这一框架如何助力大模型的预训练计算。
大模型是大势所趋
近年来,NLP 模型的发展十分迅速,模型的大小每年以1-2个数量级的速度在提升,背后的推动力当然是大模型可以带来更强大更精准的语言语义理解和推理能力。
截止到去年,OpenAI发布的GPT-3模型达到了175B的大小,相比2018年94M的ELMo模型,三年的时间整整增大了1800倍之多。按此趋势,预计两年后,会有100 Trillion参数的模型推出。
另外一个特点是,自从18年 Google 推出 Attention is All You Need论文后,这几年的模型架构,不管是双向的BERT,还是生成式的GPT,都是基于Transformer 架构来构建的,通常说的模型有多少层,指的便是有多少个Transformer块来堆叠起来的。
而且,这类模型的计算量也主要来自于对Transformer块的处理,其本质上可以转化成大量的矩阵操作,天然地适合NVIDIA GPU的并行架构。
分布式是大模型训练的必须
大模型的预训练对计算、通信带来的挑战是不言而喻的。我们以GPT-3 175B 模型为例,分析预训练对计算量、显存、通信带来的挑战。
GPT-3 175B模型的参数如下:网络层(Number of layers): 96
句子长度(Sequence length): 2048
隐藏层大小(Hidden layer size): 12288
词汇表(Vocabulary size):51200
总参数量:约175B
1. 对显存的挑战
175B的模型,一个原生没有经过优化的框架执行,各部分大概需要的显存空间:
模型参数:700 GB (175B * 4bytes)
参数对应的梯度:700 GB
优化器状态:1400 GB
所以,一个175B模型共需要大概2.8 TB的显存空间,这对 GPU 显存是巨大的挑战:
1)模型在单卡、单机上存放不下。以 NVIDIA A100 80GB为例,存放此模型需要超过35块。
2) 必须使用模型并行,并且需要跨机器。主流的A100 服务器是单机八卡,需要在多台机器之间做模型切分。
2. 对计算的挑战
基于Transformer 架构的模型计算量主要来自于Transformer层和 logit 层里的矩阵乘,可以得出每个迭代步大致需要的计算量:
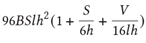
B: 批大小,S:句子长度,l:Transformer 层数,h:隐藏层大小,V:词汇表大小
这是真实计算量的一个下限,但已是非常接近真实的计算量。关于此公式的详细说明,请参考 NVIDIA Paper(https://arxiv.org/abs/2104.04473)里的附录章节。
其中S=2048, l=96, h=12288, V=51200,在我们的实践中,B = 1536,一共需要迭代大约95000次。代入这次参数到上述公式,可以得到:
一次迭代的计算量:4.5 ExaFLOPS.
完整训练的计算量:430 ZettaFLOPS (~95K 次迭代)
这是一个巨大的计算量,以最新的 NVIDIA A100 的FP16计算能力 312 TFLOPS来计算,即使不考虑计算效率和扩展性的情况,需要大概16K A100*days的计算量。直观可以理解为16000块A100一天的计算量,或者一块A100 跑43.8年的计算量。
3. 对通信的挑战
训练过程中GPU之间需要频繁的通信,这些通信源于模型并行和数据并行的应用,而不同的并行划分策略产生的通信模式和通信量不尽相同。
对于数据并行来说,通信发生在后向传播,用于梯度通信,通信类型为AllReduce,每次后向传播中的通信量为每个GPU上的模型大小。
对于模型并行来说,稍微复杂些。模型并行通常有横切和竖切两种,比如把一个模型按网络层从左到右横着摆放,横切即把每个网络层切成多份(Intra-layer),每个GPU上计算网络层的不同切块,也称为Tensor(张量)模型并行。竖切即把不同的网络层切开(Inter-layer),每个GPU上计算不同的网络层,也称为Pipeline (流水线)模型并行。
对于Tensor模型并行,通信发生在每层的前向和后向传播,通信类型为AllReduce,通信频繁且通信量比较大。
对于Pipeline 模型并行,通信发生在相邻的切分点,通信类型主要为P2P,每次通信数据量比较少但比较频繁,而且会引入额外的GPU 空闲等待时间。
稍后会详细阐述在Transformer 架构上如何应用这两种模型划分方式。
更为复杂的是,对于超大的语言模型,通常会采用数据并行 + Tensor 模型并行 + Pipeline 模型并行混合的方式,这使得通信方式错综复杂在一起,对系统连接拓扑提出更大的挑战:能灵活满足不同划分策略、不同通信模式下,不同通信组里高效的通信。
总而言之,超大语言模型的预训练,采用多节点的分布式训练是必须,而且是基于模型并行的。这就对集群架构和训练框架提出了严苛的设计要求,集群架构要有优化的互联设计,训练框架更为重要:不仅仅是结合算法特点对模型做合理切割,更是需要做出结合系统架构特点、软硬一体的co-design。
为此,NVIDIA 分别提出了优化的分布式框架NVIDIA Megatron 和优化的分布式集群架构 NVIDIA DGX SuperPOD。
优化的分布式框架:NVIDIA Megatron
Megatron设计就是为了支持超大的Transformer模型的训练的,因此它不仅支持传统分布式训练的数据并行,也支持模型并行,包括Tensor并行和Pipeline并行两种模型并行方式。
1. Tensor 模型并行
上面我们看到,对于一个Transformer块,主要包括Masked Multi Self Attention和Feed Forward两个部分,对于Tensor并行,需要把这两部分都并行化。
对于Feed Forward部分,是由多个全连接层组成的MLP网络,每个全连接层由矩阵乘和GeLU激活或Dropout组成,在Megatron中,Feed Forward采用两层全连接层。对于一个全连接层,可以表示为:
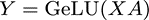
其中X输入,A为参数矩阵,Y为输出,则可以有两种并行方式。
一种是按行的方向把权重矩阵A切分开并按列的方向把输入X切分开,即: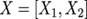
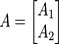 则输出:
则输出:
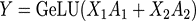
其中括号中的每一项,可以在一个单独的GPU上独立的完成,再通过一次AllReduce完成求和操作。
另一种则是按列的方向把权重矩阵A切分开,而不切分输入,即:
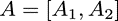
则可以得到同样按列方向切分开的输出:
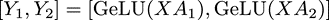
方括号中每一项可以在一个单独的GPU上独立的完成,这样每个GPU上得到部分的最终输出,大家拼接在一起就是完整输出,不需要再做AllReduce。
Megatron在计算MLP时采用了这两种并行方式,具体如下图所示:
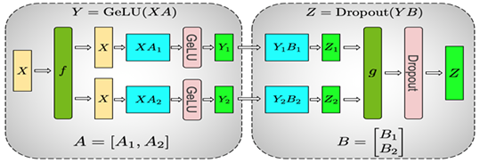
整个MLP的输入X先通过f放到每一块GPU上,然后先使用上面提到的按列切分权重矩阵A的方式,在每块GPU上得到第一层全连接的部分输出Y1和Y2,然后采用按行切分权重矩阵B,按列切分Y的方式,其中前一层的输出Y1和Y2刚好满足Y的切分需求,因此可以直接和B的相应部分做相应的计算而不需要额外操作或通信。这样得到了最终Z的部分、Z1和Z2,通过g做AllReduce得到最终的Z,再通过相应的激活层或Dropout。
这样就完成了MLP层的Tensor并行,对于Masked Multi Self Attention层,如下图所示:
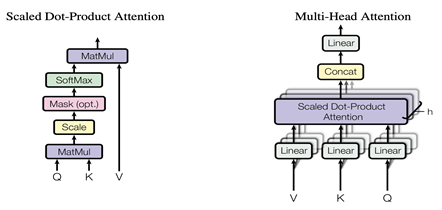
正如它的名字中提到的,它是由多个Self Attention组成的,因此很自然的并行方式就是可以把每个Self Attention分到不同的GPU上去进行计算,这样每块GPU上就能够得到输出的一部分,最后的Linear全连接层,由于每个GPU上已经有部分输出,因此可以采用上面全连接层的按行的方向切权重矩阵B并按列的方向切输入Y的方式直接进行计算,再通过AllReduce操作g得到最终结果。
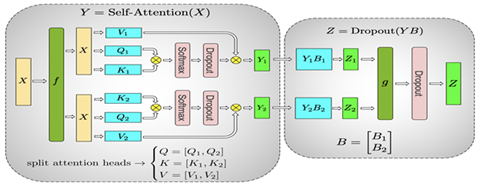
这样我们就可以完成Transformer块的Tensor并行。有了Tensor并行,我们可以把模型的每一层进行切分,分散到不同的GPU上,从而训练比较大的模型。由于Tensor并行会对每一层进行切分,并且需要通信,因此Tensor并行在同一台机器上,并且有NVLink的加速情况下性能最好。如果模型进一步增大,大到一台机器可能都放不下整个模型,这时就需要引入另一种并行方式,Pipeline并行。
2. Pipeline 模型并行
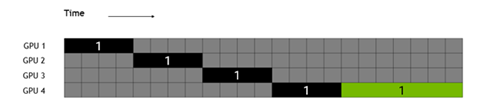
相对于Tensor并行的把模型的每一层内部进行切分,Pipeline并行是会在模型的层之间进行切分,不同的层在不同的GPU或机器节点上进行计算。由于不同的层间有依赖关系,所以如果直接并行会像下图所示,黑色部分是前向,绿色部分是反向计算,灰色部分是空闲,可以看出GPU的绝大部分时间是在等待。
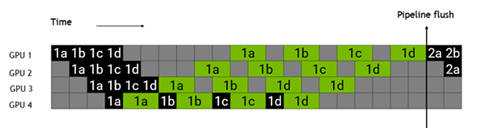
为了解决这个问题,Megatron把每一个batch分成了更小的microbatch,如下图所示,把batch 1分成了1a,1b,1c,1d四个microbatch,由于不同的microbatch间没有数据依赖,因此互相可以掩盖各自的等待时间,提高GPU利用率,提升整体的性能。
这就是Megatron 核心的两种模型并行的设计,可以支撑超大的Transformer-based 语言模型,再结合经典的数据并行方式,可以让大模型的训练更快。
编辑:jq
-
数据
+关注
关注
8文章
6511浏览量
87592 -
NVIDIA
+关注
关注
14文章
4592浏览量
101703 -
gpu
+关注
关注
27文章
4417浏览量
126669 -
分布式
+关注
关注
1文章
754浏览量
74084 -
MLP
+关注
关注
0文章
56浏览量
4073
原文标题:NVIDIA Megatron:超大Transformer语言模型的分布式训练框架 (一)
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【书籍评测活动NO.30】大规模语言模型:从理论到实践
大语言模型背后的Transformer,与CNN和RNN有何不同

鸿蒙原生应用开发——分布式数据对象
分布式系统硬件资源池原理和接入实践
spring分布式框架有哪些
基于PyTorch的模型并行分布式训练Megatron解析


OpenHarmony 分布式硬件关键技术
如何计算transformer模型的参数量

2D Transformer 可以帮助3D表示学习吗?
基于Transformer做大模型预训练基本的并行范式
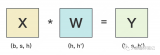






 工商网监
工商网监
评论