有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 python 中安装和使用顶级聚类算法。
2023-05-22 09:13:55 171
171 
分享一篇关于聚类的文章:10种聚类算法和Python代码。
2023-01-07 09:33:38566 在聚类技术领域中,K-means可能是最常见和经常使用的技术之一。K-means使用迭代细化方法,基于用户定义的集群数量(由变量K表示)和数据集来产生其最终聚类。例如,如果将K设置为3,则数据集将分组为3个群集,如果将K设置为4,则将数据分组为4个群集,依此类推。
2022-10-28 14:25:21499 K-means 算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是由距离靠近的对象组成的,因此算法目的是得到紧凑并且独立的簇。
2022-07-18 09:19:131438 
K-means 是一种聚类算法,且对于数据科学家而言,是简单且热门的无监督式机器学习(ML)算法之一。
2022-06-06 11:53:552540 FCM聚类算法以及改进模糊聚类算法用于医学图像分割的matlab源程序
2018-05-11 23:30:42
基于模糊C均值聚类的软件多缺陷定位方法
2021-06-02 14:38:41 6
6 为构建行驶工况,消除K均值算法对初始聚类中心的敏感性及噪声点的干扰,提岀一种改进主成分分析和基于密度的改进k-均值聚类组合方法。结合距离优化法和密度法,构建一种数据集密度度量方法。选取距离较大、密度
2021-05-31 11:16:083 簇控制在最优传输距离内,实现簇内节点的能耗均衡。通过目标函数对K- means聚类簇进行优化,保证簇内节点数目的均匀分布,并在考虑剩余能量和地理位置的基础上完成节点数据传输。实验结果表明,该算法在均衡网络能耗的同时,可有效延长网络生命
2021-05-26 14:50:172 针对含有噪声的高维数据的聚类问题,提岀一种使用新的距离度量方式的増量式聚类算法 ANFCM(cp)。由于传统的模糊C均值聚类算法对初始化聚类中心比较敏感,所提岀的聚类算法将单程FCM的増量机制(称为
2021-05-12 15:20:511 为了降低K- mediods聚类算法的误差并提高并行优化的性能,将混合蛙跳算法运用于聚类和并行优化过程。在Kmediods聚类过程中,将K- mediods与聚类簇思想相结合,对各个聚类簇进行混合
2021-05-08 16:17:184 为构建行驶工况,消除K-均值算法对初始聚类中心的敏感性及噪声点的干扰,提岀一种改进主成分分析和基于密度的改进K-均值聚类组合方法。结合距离优化法和密度法,构建一种数据集密度度量方法。选取距离较大
2021-04-16 15:36:0016 除边界点和噪声点对聚类结果的影响。引入关联度矩阵,通过计算类簇间的关联程度和融合度量,选取最优关联簇进行融合得到最终聚类结果。实验结果表明,该算法无需人工设置聚类参数,并且与基于密度的空间聚类算法和K均值聚类算法
2021-04-01 16:16:4913 子空间并定义合理的约東函数指导聚类过程,从而实现类簇的可重叠性与离群点的控制。在此基础上定义合理的目标函数对传统K- Means算法进行修正,利用熵权约東分别计算每个类簇中各维度的权重,使用权重值标识不同类簇中维度的相对重要性,
2021-03-25 14:07:1013 度推荐算法。采用改进的蜂群算法来优化K- means++聚类的中心点,使聚类中心在整个数据内达到最优,并对聚类结果进行集成,使得聚类得到进一步优化。根据聚类结果,在同一类中采用改进的用户相似度算法来优化传统相似度算法,
2021-03-18 11:17:1110 聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法
2021-03-12 18:23:431828 几张GIF理解K-均值聚类原理k均值聚类数学推导与python实现前文说了k均值聚类,他是基于中心的聚类方法,通过迭代将样本分到k个类中,使...
2020-12-10 21:56:09216 这一最著名的聚类算法主要基于数据点之间的均值和与聚类中心的聚类迭代而成。它主要的优点是十分的高效,由于只需要计算数据点与剧类中心的距离,其计算复杂度只有O(n)。
2020-04-15 15:23:2914904 聚类算法十分容易上手,但是选择恰当的聚类算法并不是一件容易的事。
2020-03-15 17:10:001663 聚类分析是将研究对象分为相对同质的群组的统计分析技术,聚类分析的核心就是发现有用的对象簇。K-means聚类算法由于具有出色的速度和良好的可扩展性,一直备受广大学者的关注。然而,传统的K
2018-12-20 10:28:2910 中,干扰样本个体之间的权重值,实现样本个体间的信息隐藏以达到隐私保护的目的。通过UCI数据集上的仿真实验,表明该算法能够在一定的信息损失度范围内实现有效的数据聚类,也可以对聚类数据进行保护。
2018-12-14 10:54:2610 K-means算法是被广泛使用的一种聚类算法,传统的-means算法中初始聚类中心的选择具有随机性,易使算法陷入局部最优,聚类结果不稳定。针对此问题,引入多维网格空间的思想,首先将样本集映射到一个
2018-12-13 17:56:551 针对传统K-means型算法的“均匀效应”问题,提出一种基于概率模型的聚类算法。首先,提出一个描述非均匀数据簇的高斯混合分布模型,该模型允许数据集中同时包含密度和大小存在差异的簇;其次,推导了非均匀
2018-12-13 10:57:5910 )2个步骤,以提高平衡聚类算法的聚类效果与时间性能。首先基于模拟退火在数据集中快速定位出K个合适的数据点作为平衡聚类初始点,然后每个中心点分阶段贪婪地将距离其最近的数据点加入簇中直至达到簇规模上限。在6个UCI真实数据集与2个公开图
2018-11-28 09:53:067 无监督学习是机器学习技术中的一类,用于发现数据中的模式。本文介绍用Python进行无监督学习的几种聚类算法,包括K-Means聚类、分层聚类、t-SNE聚类、DBSCAN聚类等。
2018-05-27 09:59:1329359 
Matlab 提供系列函数用于聚类分析,归纳起来具体方法有如下: 方法一:直接聚类,利用 clusterdata 函数对样本数据进行一次聚类,其缺点为可供用户选择的面较窄,不能更改距离的计算方法,该方法的使用者无需了解聚类的原理和过程,但是聚类效果受限制。
2018-05-18 15:04:006775 本文开始介绍了聚类算法概念,其次阐述了聚类算法的分类,最后详细介绍了聚类算法中密度DBSCAN的相关概况。
2018-04-26 10:56:4121028 
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。
2018-02-12 16:42:3514535 
的规范化互信息(NMI);然后基于NMI的值来选择用于聚类集成的K均值基聚类器的K值序列;最后采用二次互信息( QMI)的一致函数生成一致聚类结果,并使用一种半监督方法对聚类簇进行标注。通过实验比较了聚类集成方法与单个聚类算法
2018-02-09 10:35:560 针对谱聚类算法在解决高维、大数据量的聚类问题时出现的效率不高和准确率明显下降的问题进行了研究,并在此研究基础上结合最优投影理论和Nystrom抽样提出了基于最优投影的半监督谱聚类算法
2018-01-14 11:54:580 通过对基于K-means聚类的缺失值填充算法的改进,文中提出了基于距离最大化和缺失数据聚类的填充算法。首先,针对原填充算法需要提前输入聚类个数这一缺点,设计了改进的K-means聚类算法:使用数据间
2018-01-09 10:56:560 提出基于可能性二均值聚类(Possibilistic Two Means, P2M)的二分类支持向量机(Support Vector Machine,SVM)。该算法先用P2M对未知类别的二分类数据
2018-01-09 10:45:010 基于SVM和模糊K均值算法的部位外观模型。部位外观模型由两个分类器构成,线性SVM分类器用于判断部位定位状态是否属于人体部位,相似度分类器由部位定位状态与利用模糊K均值算法确定的部位聚类中心的归一化欧氏距离来构造,用于计算
2018-01-08 15:13:400 在目标域可利用数据匮乏的场景下,传统聚类算法的性能往往会下降,在该场景下,通过抽取源域中的有用知识用于指导目标域学习以得到更为合适的类别信息和聚类性能,是一种有效的学习策略.借此提出一种基于近邻传播
2018-01-07 09:34:440 基于相似度的聚类算法,该算法结合区间值模糊软集的特性,着重对给出评价对象的具有相似知识水平的专家进行聚类,同时讨论了算法的计算复杂度。最后通过实例说明该算法能有效地处理专家聚类问题。
2018-01-05 16:15:270 针对传统模糊C一均值( FCM)聚类算法初始聚类中心不确定,且需要人为预先设定聚类类别数,从而导致结果不准确的问题,提出了一种基于中点密度函数的模糊聚类算法。首先,结合逐步回归思想作为初始聚类中心
2017-12-26 15:54:200 针对大数据环境下K-means聚类算法聚类精度不足和收敛速度慢的问题,提出一种基于优化抽样聚类的K-means算法(OSCK)。首先,该算法从海量数据中概率抽样多个样本;其次,基于最佳聚类中心的欧氏
2017-12-22 15:47:180 研究加速K-medoids聚类算法,首先以PAM(partitiomng around medoids)、TPAM(triangular inequality elimination
2017-12-22 15:35:470 聚类作为无监督学习技术,已在实际中得到了广泛的应用,但是对于带有噪声的数据集,一些主流算法仍然存在着噪声去除不彻底和聚类结果不准确等问题.本文提出了一种基于密度差分的自动聚类算法(CDD
2017-12-18 11:16:570 传统的核聚类仅考虑了类内元素的关系而忽略了类间的关系,对边界模糊或边界存在噪声点的数据集进行聚类分析时,会造成边界点的误分问题。为解决上述问题,在核模糊C均值( KFCM)聚类算法的基础上提出了一种
2017-12-15 10:52:531 针对原始K-means聚类算法受初始聚类中心影响过大以及容易陷入局部最优的不足,提出一种基于改进布谷鸟搜索(cs)的K-means聚类算法(ACS-K-means)。其中,自适应CS( ACS)算法
2017-12-13 17:24:063 方法进行改进,将传统谱聚类算法(NJW-SC)中的基于欧氏距离的相似性测度换为基于流行距离的相似性测度,在此基础上对样本对象集进行聚类。之后将新提出来的算法同K-Means算法、传统谱聚类算法、模糊C均值聚类算法在人工数据集
2017-12-07 14:53:033 的算法。首先,通过各向异性扩散处理图像;然后,使用一维K-均值对像素进行聚类;最后,根据聚类结果和先验知识将像素值修改为最佳类中心像素值。理论分析表明该算法可以使图像的峰值信噪比( PSNR)达到最大值。实验结果表明:所
2017-12-06 16:44:110 针对轨迹聚类算法在相似性度量中多以空间特征为度量标准,缺少对时间特征的度量,提出了一种基于时空模式的轨迹数据聚类算法。该算法以划分再聚类框架为基础,首先利用曲线边缘检测方法提取轨迹特征点;然后根据
2017-12-05 14:07:580 D-Stream作出并行化改进,用通用的大数据处理框架Spark设计了一个基于分布式架构运行的动态数据聚类算法PDStream。实验结果表明,该算法具有更高的效率和良好的扩展性,能够实现分布式架构下的流数据动态聚类。
2017-12-04 09:22:510 运用社会力模型( SFM)模拟人群疏散之前,需要先对人群进行聚类分组;然而,五中心聚类(k-medoids)和统计信息网格聚类( STING)这两大传统聚类算法,在聚类效率和准确率上都不能满足要求
2017-12-03 10:53:040 尽可能归于一类,而把不相似的样本划分到不同的类中。硬聚类把每个待识别的对象严格的划分某类中,具有非此即彼的性质,而模糊聚类建立了样本对类别的不确定描述,更能客观的反应客观世界,从而成为聚类分析的主流。
2017-12-01 14:26:0248589 
模糊C均值聚类算法在数据挖掘领域有着广泛的使用背景,而对初始点的敏感和较差的搜索能力,限制了算法的进一步推广应用。人工蜂群算法具有对初始点不敏感、适应能力强和搜索能力强等优点,并且针对人工蜂群算法
2017-11-29 17:22:210 针对传统图转导( GT)算法计算量大并且准确率不高的问题,提出一个基于C均值聚类和图转导的半监督分类算法。首先,采用模糊C均值(FCM)聚类算法先对未标记样本预选取,缩小图转导算法构图数据集的范围
2017-11-28 16:36:120 针对核模糊C均值( KFCM)算法对初始聚类中心敏感、易陷入局部最优的问题,利用人工蜂群(ABC)算法的构架简单、全局收敛速度快的优势,提出了一种改进的人工蜂群算法( IABC)与KFCM迭代相结合
2017-11-28 16:14:040 针对传统的K-means算法无法预先明确聚类数目,对初始聚类中心选取敏感且易受离群孤点影响导致聚类结果稳定性和准确性欠佳的问题,提出一种改进的基于密度的K-means算法。该算法首先基于轨迹数据分布
2017-11-25 11:35:380 针对套用传统的聚类方法对数据流的聚类是行不通的这一问题,提出一种以遗传模拟退火算法为基础的模糊C均值聚类算法(SACA_FCM)对数据流进行聚类。SACAFCM算法有效地避免了传统的模糊C均值聚类
2017-11-22 11:51:139 CFSFDP是基于密度的新型聚类算法,可聚类非球形数据集,具有聚类速度快、实现简单等优点。然而该算法在指定全局密度阈值d时未考虑数据空间分布特性,导致聚类质量下降,且无法对多密度峰值的数据集准确聚类
2017-11-21 15:08:5715 传统kmeans算法由于初始聚类中心的选择是随机的,因此会使聚类结果不稳定。针对这个问题,提出一种基于离散量改进k-means初始聚类中心选择的算法。算法首先将所有对象作为一个大类,然后不断从对象
2017-11-20 10:03:232 为解决传统BIRCH算法对数据对象输入顺序敏感、聚类结果不稳定的问题,提出了一种改进的BIRCH算法。该算法将雷达信号侦察数据的脉冲载频、脉冲重复间隔和脉冲宽度分别进行聚类,根据工程应用中各参数
2017-11-10 15:52:181 为了提高WSN节点定位精度,针对测距误差对定位结果的影响,提出基于模糊C均值聚类的定位算法。算法首先利用多边定位算法得到若干个定位结果,利用模糊C均值聚类算法对定位结果进行聚类分析,然后,根据聚类
2017-11-09 17:47:1310 在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。本文提出了一种
2017-11-03 16:13:0512 马尔科夫聚类算法( Markov Cluster Algorithm,MCL)是一种快速且可扩展的无监督图聚类算法,Chameleon是一种新的层次聚类算法。但MCL由于过拟合会产生很多小聚类
2017-10-31 18:58:212 。提出一种基于优化粒子群算法的云存储中大数据优化聚类算法,进行了云存储大数据聚类的原理分析,在传统的模糊C均值聚类的基础上,采用粒子群聚类算法进行大数据聚类算法改进设计,把数据的分割转化为对空间的分割,得到
2017-10-28 12:46:531 聚类分析计算方法主要有如下几种:划分法、层次法、密度算法、图论聚类法、网格算法和模型算法。划分法(partitioning methods),给定一个有N个元组或者纪录的数据集,分裂法将构造K个分组,每一个分组就代表一个聚类,K《N。
2017-10-25 19:18:34165890 
鉴于主元分析法的降维特性和模糊C均值聚类算法良好的分类性能,本文在丙烯睛反应器操作参数的优化中,结合这两种方法,将主元分析处理后的数据作为新的样本输入,利用模糊C均值聚类算法进行优化操作。
2017-09-08 15:48:039 基于加速k均值的谱聚类图像分割算法改进_李昌兴
2017-03-19 19:25:560 基于改进K_means聚类的欠定盲分离算法_柴文标
2017-03-17 10:31:390 基于PCA的H_K聚类算法研究_何莹
2017-03-17 08:00:000 基于SVD的K_means聚类协同过滤算法_王伟
2017-03-17 08:00:000 基于改进K均值聚类的机械故障智能检测_费贤举
2017-02-08 01:57:370 特征加权和优化划分的模糊C均值聚类算法_肖林云
2017-01-07 21:39:440 混合细菌觅食和粒子群的k_means聚类算法_闫婷
2017-01-07 19:00:390 基于聚类中心优化的k_means最佳聚类数确定方法_贾瑞玉
2017-01-07 18:56:130 基于AutoEncoder的增量式聚类算法_原旭
2017-01-03 17:41:320 基于最小生成树的层次K_means聚类算法_贾瑞玉
2017-01-03 15:24:455 模糊C-均值聚类算法是一种无监督图像分割技术,但存在着初始隶属度矩阵随机选取的影响,可能收敛到局部最优解的缺点。提出了一种粒子群优化与模糊C-均值聚类相结合的图像分割算
2012-10-16 16:07:0621 介绍了K-means 聚类算法的目标函数、算法流程,并列举了一个实例,指出了数据子集的数目K、初始聚类中心选取、相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚
2012-05-07 14:09:1427 针对数据在性态和类属方面存在不确定性的特点,提出一种基于模糊C 均值聚类的数据流入侵检测算法,该算法首先利用增量聚类得到网络数据的概要信息和类数,然后利用模糊C均值聚
2012-03-20 10:29:2135 聚类算法及聚类融合算法研究首先对 聚类算法 的特点进行了分析,然后对聚类融合算法进行了挖掘。最后得出聚类融合算法比聚类算法更能得到很好的聚合效果。
2011-08-10 15:08:0233 传统无线传感网一般由大量密集的传感器节点构成,存在节点计算能力、能源和带宽都非常有限的缺点,为了有效节能、延长网络寿命,介绍了基于聚类的K均值算法。该算法通过生成的
2011-04-12 18:16:5449 该文针对聚类问题上缺乏骨架研究成果的现状,分析了聚类问题的近似骨架特征,设计并实现了近似骨架导向的归约聚类算法。该算法的基本思想是:首先利用现有的启发式聚类算
2010-02-10 11:48:095 该文针对K 均值聚类算法存在的缺点,提出一种改进的粒子群优化(PSO)和K 均值混合聚类算法。该算法在运行过程中通过引入小概率随机变异操作增强种群的多样性,提高了混合聚类
2010-02-09 14:21:2610 文本聚类是中文文本挖掘中的一种重要分析方法。K 均值聚类算法是目前最为常用的文本聚类算法之一。但此算法在处理高维、稀疏数据集等问题时存在一些不足,且对初始聚类
2010-01-15 14:24:4610 本文通过对常用动态聚类方法的分析,提出了基于“约简-优化”原理的两阶段动态聚类算法的框架,此方法克服了动态聚类搜索空间过大的问题,提高了聚类的精度和效率。
2010-01-09 11:31:1412 针对二叉树支持向量机在多类分类问题上存在的不足,利用粒子群算法对模糊C 均值聚类算法进行了改进,在此基础上,结合二叉树支持向量机,构建了偏二叉树多类分类算法。
2009-12-18 16:36:1612 聚类算法研究:对近年来聚类算法的研究现状与新进展进行归纳总结.一方面对近年来提出的较有代表性的聚类算法,从算法思想、关键技术和优缺点等方面进行分析概括;另一方面选择
2009-10-31 08:57:2414 基于关联规则与聚类算法的查询扩展算法:针对信息检索中查询关键词与文档用词不匹配的问题,提出一种基于关联规则与聚类算法的查询扩展算法。该算法在第1 阶段对初始查
2009-10-17 23:00:3312 针对模糊C-均值(FCM)算法不能很好地处理更新数据的缺点,提出基于FCM 的自适应增量式聚类算法AIFCM。该算法结合密度和集合的思想,给出一种自动确定聚类初始中心的方法,能在
2009-10-04 14:09:0911 Web文档聚类中k-means算法的改进
介绍了Web文档聚类中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空间模型和基于距离的相似性度量的局限性,从而
2009-09-19 09:17:03913 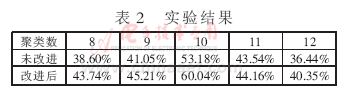
针对CRM 客户分类,提出模拟退火算法与K 均值算法相结合的聚类算法。利用模拟退火算法全局寻优能力改变k 均值算法易陷入局部极值的缺点。经标准数据集检验,证明算法有效
2009-09-15 16:16:378 目前应用最广泛的模糊聚类算法是基于目标函数的模糊k-均值算法,针对该算法存在的缺点,本文提出一种改进的聚类算法,利用遗传算法的全局优化的特点,在能够在正确获得
2009-09-07 15:35:428 提出了一种多密度网格聚类算法GDD。该算法主要采用密度阈值递减的多阶段聚类技术提取不同密度的聚类,使用边界点处理技术提高聚类精度,同时对聚类结果进行了人工干预。G
2009-08-27 14:35:5811 通过比较入侵检测和人工免疫两个系统间的相似性,提出了一种基于人工免疫原理的入侵检测系统模型。运用K均值算法对人工免疫系统中的抗原和抗体进行聚类,对该算法进行了
2009-08-04 09:33:0018 K-均值算法是一种基于样本间相似性度量的间接聚类方法。本文研究和探索K-均值方法在岩相识别中的应用。在求样本间的距离时,采用马氏(Mahalanobis)距离代替欧氏距离。关键词
2009-07-08 08:56:565 传统K均值算法对初始聚类中心敏感,聚类结果随不同的初始输入而波动,容易陷入局部最优值。针对上述问题,该文提出一种基于遗传算法的K均值聚类算法,将K均值算法的局部寻
2009-04-13 09:59:2222 提出了一种新的层次聚类算法,先对数据集进行采样,以采样点为中心吸收邻域内的数据点形成子簇,再根据子簇是否相交实现层次聚类。在层次聚类过程中,重新定义了簇与簇
2009-03-03 11:48:1919
 电子发烧友App
电子发烧友App









 工商网监
工商网监
评论