 利用语音直接画出人脸,AI再添新能力
利用语音直接画出人脸,AI再添新能力
听声辨人,利用声纹进行解锁,这种技术已广泛应用,人类的声音含有该个体的一定特征,从而可以进行区分。那么仅通过声音,能否画出人像,并且尽可能地与讲话者相似呢?
近日,卡内基梅隆大学的Yandong Wen 等人,利用生成对抗网络模型(generative adversarial networks, GANs)首次对这一问题作出研究,利用讲话者的语音生成一些匹配原说话者面部特征的人脸,并用交叉模态匹配(cross-modal matching task)评估了模型表现,可谓是语音画像领域的一大突破。
模型框架
一个人的声音和骨骼结构、发声部位的形状等特征的确有关,但利用语音直接画出人脸,如何做到?
该由声音重建人脸的模型框架主要由四个卷积网络:语音嵌入模型(voice embedding network)、生成器(Generator)、判别器(Discriminator)、分类器(classifier)组成。
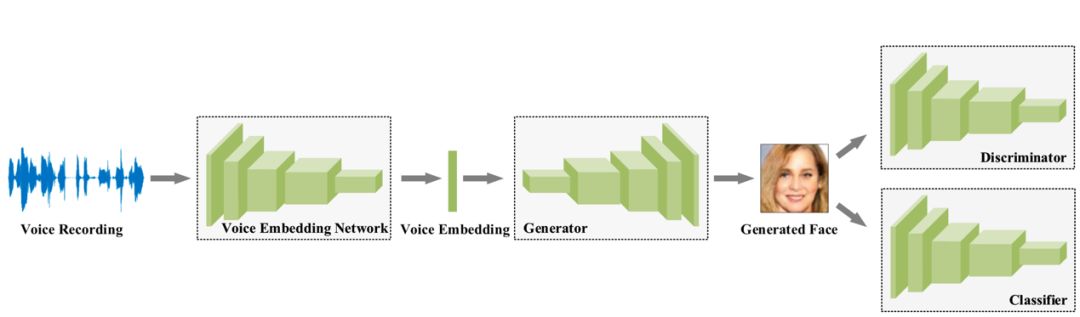
语音嵌入模型(voice embedding network)将输入的语音数据,梅尔倒频谱(log mel-spectrograms)转换为含有该声音特征的向量 e。该模型含有 5 层一维卷积神经网络,每一层均是经由卷积核为 3、步长为 2、padding 为 1 得到,并且都经过归一化层处理和 ReLU 单元激活,最后经过平均池化得到一个 64 维的向量。此模型是通过一个语音识别任务预先训练得到参数,并且参数在生成人脸的训练过程中保持不变。生成器(Generator)输入为语音嵌入模型产生的向量 e,输出是人脸 RGB 图像 f',由 6 层二维反卷积网络构成,激活函数采用 ReLU。
判别器(Discriminator)判断输入的图像 f(或 f')是生成器伪造的图像还是真实的人脸,如果判断为伪造图会加大损失 Ld。由 6 层激活单元为 Leaky ReLU 的二维卷积网络构成,最后经过全连接层得到人脸图像数据。
分类器(classifier)用来将人脸图像与说话者匹配,如果匹配错误会加大损失 Lc。该模型由 6 层二维卷积网络和一个全连接层组成。具体的结构如图表,其中 Conv 3/2,1代表卷积核尺寸为 3,步长为 2,padding 填充为 1。
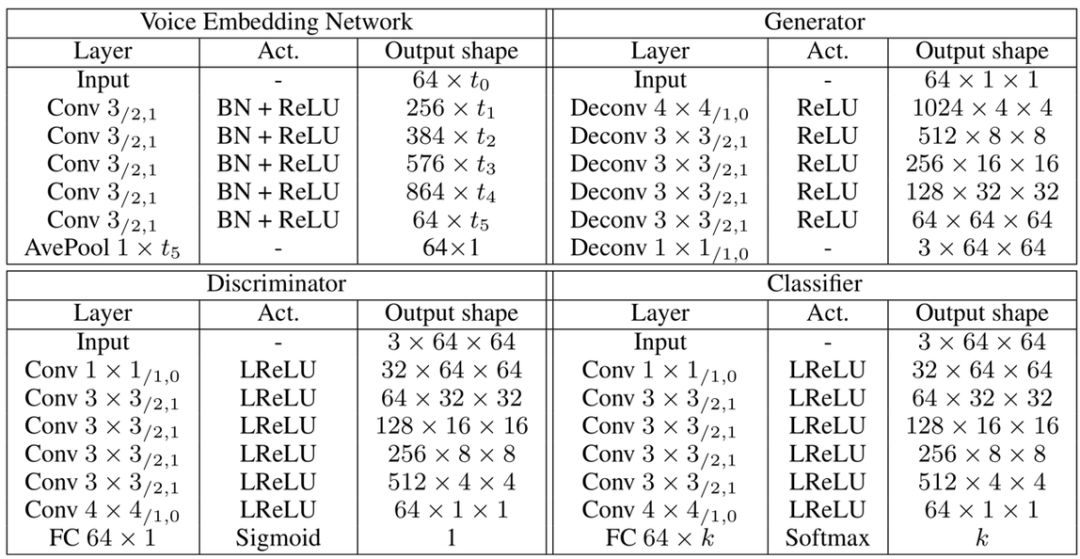
图 | 从声音重建人脸模型的具体结构。(来源:Yandong Wen, et al./CMU)模型通过最小化判别器与分类器的交叉熵损失 Ld 和 Lc 来训练,以期得到图像逼真且符合说话者特征的人脸。值得一提的是,此模型的测试集和训练集以及验证集相互独立,即测试时的声音是未听过的,人脸也未知。
模型表现
不特意挑选那些人脸和真实讲话者完美一致的结果,一般来讲,该模型的确能输出具有讲话者特征的人脸,即使不完全一模一样,从种族以及一些其他典型的面部特征来看,这个模型的确学习到了一些信息,输出结果和原讲话者非常像,并且语音时间越长,匹配的特征越多,两者越类似。
图 | 从不同时长的正常录音生成人脸的结果图,右侧Ref为真实讲话者的不同脸部照片,从上到下的 4 位 Speaker 分别是 Danica McKellar, Cindy Williams, Damian Lewis, and Eva Green. (来源:Yandong Wen, et al./CMU)当然,性别及年龄特征也可以很好地被学习到,左侧输出结果的年龄和性别与右侧真实人脸的年龄性别保持一致。在整个测试集上,生成图和真实讲话者性别相同的概率可以达到 96.5%。
图 | 从性别年龄的人脸重建,(a)是从老年声音生成的人脸;(b)是男性声音生成的人脸;(c)是女性声音生成的人脸。其中左侧为生成图,右侧为真实讲话者。(来源:Yandong Wen, et al./CMU)如果用同一个人的不同语音片段,推测产生的人脸会保持相同特征吗?模型结果告诉我们,是这样。选用同一个讲话者的 7 个不同语音片段,不特意挑选完美结果,模型所推测出的大概特征是十分一致的,这也侧面说明,模型的确可以从一个人的语音抽取出一些特征,映射成其脸部的某些特征。
图 | 利用一个人的 7 段不同语音重建人脸,左图(a)是重建的 7 张人脸图,右图(b)是对应的真实人脸在不同情况的照片(来源:Yandong Wen, et al./CMU)进一步来讲,如果从语音中学到的特征真的可以映射成面部的特征,那么生成人脸图必定和真实讲话者的脸部是对应匹配的。换句话说,声音中的特征可以被生成人脸中蕴含的特征替代,那么由声音重组人脸就变成了人脸识别问题,两张脸(生成的和真实的)匹配,那么计划可行,这个匹配率也就成了衡量模型表现的指标。在整个训练集和测试集上,该模型的匹配率分别是 96.83% 和 76.07%;将训练集和测试集按照性别分层,排除性别这一特征的助力,也就是直接比较同一性别上,生成的人脸和讲话者是否相像,匹配率在训练集和测试集上分别是 93.98%和 59.69%,这也证明了模型所学到的信息不仅仅是性别,还有其他更详细的面部特征。该模型表现不仅优于 DIMNets-G,同时,测试集表现不如训练集,说明模型还有很大提升空间。

图 | 不同模型在性别分层以及不分层的数据集上的表现。(来源:Yandong Wen, et al./CMU)
展望
该模型虽然表现尚佳,但仍有可提升的地方,比如头发和图像背景等与声音无关的特征,可以进行数据清洗将其去除,而有一些明显与发声有关的面部特征也可以加以利用,从而模型会更加精确。
总的来说,由音生貌,语音画像问题的一块空白得到了填补。
-
AI
+关注
关注
87文章
26430浏览量
264035 -
GaN
+关注
关注
19文章
1763浏览量
67948
原文标题:仅听声音就画出人脸,GAN再添新能力
文章出处:【微信号:deeptechchina,微信公众号:deeptechchina】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
李未可科技发布全新首款AI眼镜Chat,搭载自研AI大模型

stm32f0怎么不使用语音IC做合成语音?
语音数据集:推动AI语音技术的核心力量
各行各业如何使用语音 AI 满足消费者期望
【KV260视觉入门套件试用体验】五、VITis AI (人脸检测和人体检测)
人脸识别技术几个方面的内容

AI人脸识别测温一体机设计






 工商网监
工商网监
评论