 Facebook 人工智能团队已经创建并正在开放源代码 PyTorch Biggraph
Facebook 人工智能团队已经创建并正在开放源代码 PyTorch Biggraph
有效处理大规模图对于促进人工智能的研究和应用至关重要,但特别是在工业应用中的图,包含数十亿个节点和数万亿个边,这超出了现有嵌入系统的能力。
因此,Facebook 人工智能团队已经创建并正在开放源代码 PyTorch Biggraph(PBG)。
PBG 是一个用于学习大规模图嵌入的分布式系统,特别适用于处理具有多达数十亿实体和数万亿条边的大型网络交互图。它在 2019 年的 SysML 会议上发表的大规模图嵌入框架论文中提出。
PBG 比常用的嵌入软件更快,并在标准基准上生成与最先进模型质量相当的嵌入。有了这个新工具,任何人都可以用一台机器或多台机器并行地读取一个大图并快速生成高质量的嵌入。
PBG 对传统的多关系嵌入系统进行了多次修改,使其能够扩展到具有数十亿个实体和数万亿边的图。PBG 使用图分区来在单个机器或分布式环境中训练任意量级的嵌入。研究人员在通用基准测试中展示了与现有嵌入系统相当的性能,同时允许在多台机器上扩展到任意大的图和并行化。他们在几个大型社会网络图以及完整的 Freebase 数据集上训练和评估嵌入,其中包含超过 1 亿个实体和 20 亿条边。
具体而言,PBG 通过摄取图的边列表来训练输入图,每条边由其源实体和目标实体以及可能的关系类型进行标识。它为每个实体输出一个特征向量(嵌入),试图将相邻实体放置在向量空间中彼此靠近,同时将未连接的实体分开。因此,具有相似邻近分布的实体最终将位于附近位置。
可以使用在训练中学习的参数(如果有的话),用不同的方法配置每种关系类型来计算这个“接近度得分(proximity score)”,这允许在多个关系类型之间共享相同的基础实体嵌入。
其模型的通用性和可扩展性使得 PBG 能够从嵌入文献的知识图谱中训练出多种模型,包括 TransE、RESCAL、DistMult 和 ComplEx。
PBG 的设计考虑到了规模化,并通过以下方式实现:
图分区(graph partitioning),这样模型就不必完全加载到内存中;
每台机器上的多线程计算;
跨多台机器的分布式执行(可选),所有机器同时在图的不相交部分上运行;
批量负采样(batched negative sampling),允许处理的数据为> 100 万边/秒/机器。
作为一个示例,Facebook 还发布了包含 5000 万维基百科概念的 Wikidata 图的首次嵌入版本,该图用于 AI 研究社区中使用的结构化数据。这些嵌入是用 PBG 创建的,可以帮助其他研究人员在维基数据概念上执行机器学习任务。
需要注意的是,PBG不适用于小规模图上具有奇怪模型的模型探索,例如图网络、深度网络等。
安装步骤及更多信息,请参考 GitHub 相关介绍和 PyTorch-BigGraph 文档:
https://github.com/facebookresearch/PyTorch-BigGraph
https://torchbiggraph.readthedocs.io/en/latest/
建立数十亿个节点的嵌入图

图是表示多种数据类型的核心工具。它们可以用来对相关实体的网络进行编码,例如关于世界的事实。例如,像 Freebase 这样的知识库具有不同的实体(如“Stan Lee”和“New York City”),作为描述它们之间关系的节点和边(例如“出生于”)。
图嵌入方法通过优化目标来学习图中每个节点的向量表示,即具有边的节点对的嵌入比没有共享边的节点对更接近,这类似于 word2vec 等词嵌入在文本上的训练方式。
图嵌入是一种无监督学习,因为它们只使用图结构学习节点的表示,而不使用基于任务的节点“标签”。与文本嵌入一样,这些表示可用于各种下游任务。
超大规模图形嵌入
当前,超大规模图形有数十亿个节点和数万亿条边,而标准的图嵌入方法不能很好地扩展到对超大规模图的操作,这主要有两大挑战:首先,嵌入系统必须足够快,以便进行实际的研究和生产使用。例如,利用现有的方法,训练一个具有万亿条边的图可能需要几周甚至几年的时间。
另外,存储也是一大挑战。例如,嵌入每个节点具有 128 个浮点参数的 20 亿个节点,这需要 1TB 的数据,超过了商用服务器的内存容量。
PBG 使用图的块分区来克服图嵌入的内存限制。节点被随机划分为 P 分区,这些分区的大小可以使内存容纳两个分区。然后,根据边的源节点和目标节点,将边划分为 P2 簇(Buckets)。
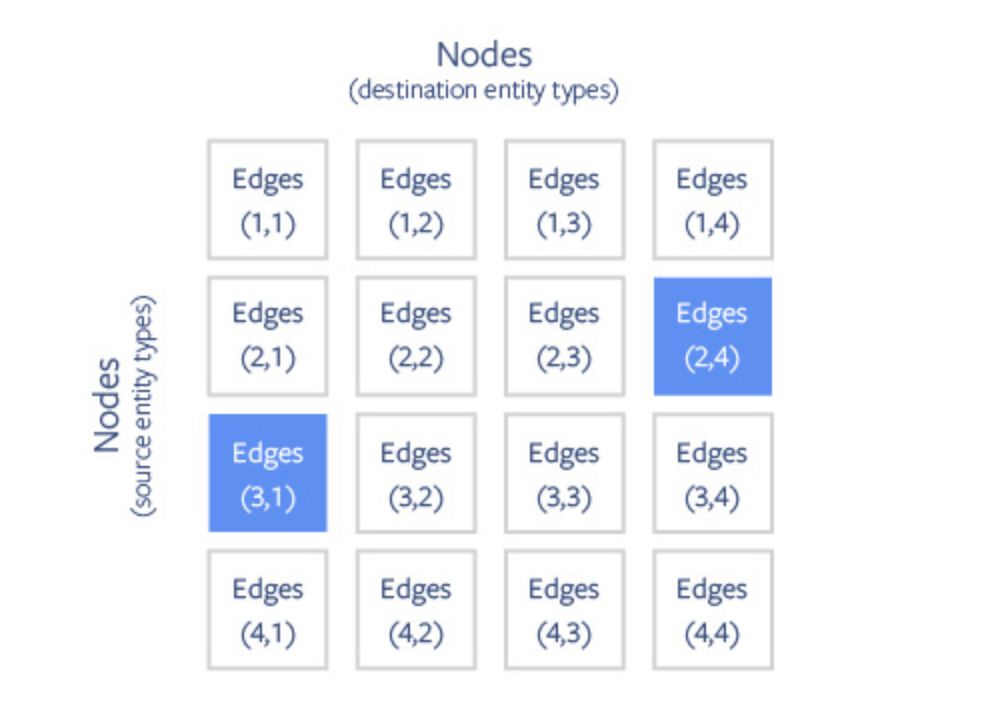
大规模图的 PBG 分区方案。节点被划分为 P 分区,分区大小适合内存。边根据其源节点和目标节点的分区划分为簇。在分布式模式下,可以并行执行具有非重叠分区的多个存储簇(如蓝色方块所示)。
节点和边进行分区之后,就可以一次在一个簇上执行训练。bucket(i,j)的训练只需要将节点分区 i 和 j 嵌入存储在内存中。
PBG 提供了两种方法来训练分区图数据的嵌入。在单机训练中,嵌入件和边在不使用时被交换到磁盘上。在分布式训练中,嵌入分布在多台机器的内存中。
分布式训练
PBG 使用 PyTorch 并行化原语(parallelization primitives)进行分布式训练。由于一个模型分区一次只能由一台机器调用,因此一次最多可以在 P/2 机器上训练嵌入。只有当机器需要切换到新的簇时,模型数据才会进行通信。对于分布式训练,我们使用经典参数服务器模型,同步表示不同类型边的共享参数。
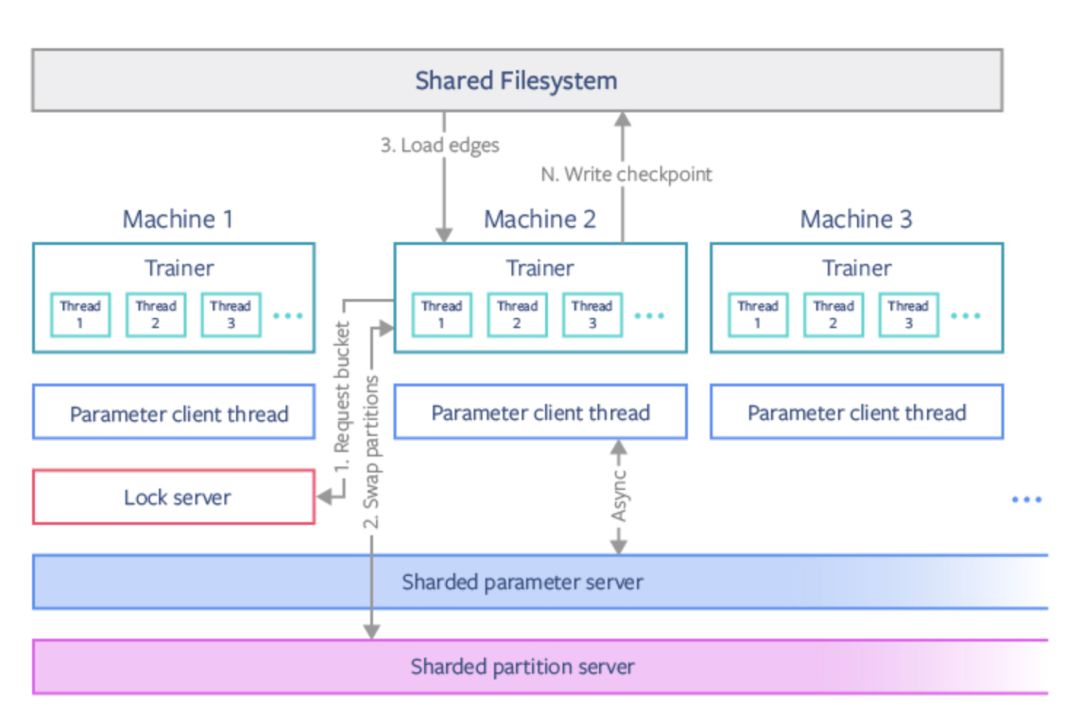
APBG 分布式训练体系结构。我们使用锁服务器协调机器在不相交的存储簇上进行训练。分区模型参数通过分片分区服务器交换,共享参数通过分片参数服务器异步更新。
负采样
图嵌入和文本嵌入相似,构造随机的“假”边与真正的边一起作为负训练样例。这大大加快了训练速度,因为每个新样本只需更新一小部分权重。通常,这些消极的例子是由随机源节点或目标节点的“腐蚀”真边构成的。然而,我们发现对标准负抽样的一些修改对于大规模图是必要的。
首先,我们注意到在传统的图嵌入方法中,几乎所有的训练时间都花在了负边上。我们利用函数形式的线性特点,重用一批 N 个随机节点,生成 N 个训练边的损坏负样本。与其他嵌入方法相比,此技术允许我们以很小的计算成本在每个真边上训练许多负示例。
我们还发现,为了生成在各种下游任务中有用的嵌入,一种有效的方法是破坏边,将 50% 的节点和另外 50% 的节点(根据其边数进行采样)混合在一起。
最后,我们引入了“实体类型”的概念,它限制了如何使用节点构造负样本。例如,考虑一个包含歌曲、艺术家和流派节点的图,并假设艺术家和歌曲之间存在“创作”关系。如果我们为这个关系统一抽样源实体,我们将绝大多数抽样歌曲(因为歌曲比艺术家多),但这些不是有效的潜在边(因为歌曲只能由艺术家制作)。PBG 可以基于关系的实体类型限制构造哪些负样本。
评估 PyTorch-BigGraph
为了评估 PBG 的性能,我们使用了公开的 Freebase 知识图,它包含超过 1.2 亿个节点和 27 亿条边。我们还使用了一个较小的 Freebase 图子集(FB15K),它包含 15000 个节点和 600000 条边,通常用作多关系嵌入方法的基准。

T-SNE 绘制的由 PBG 训练的 Freebase 知识图嵌入。国家、数字和科学期刊等实体也有类似的嵌入。
可以看出,对于 FB15k 数据集,PBG 和最新的嵌入方法性能相当。

图:FB15K 数据集的链路预测任务上嵌入方法的性能。PBG 使用其模型来匹配 transe 和复杂嵌入方法的性能。我们测量了 MRR,并在 FB15K 测试集上对链接预测进行 hit@10统计。Lacroix 等人使用非常大的嵌入维数实现更高的 MRR,我们可以在 PBG 中采用同样的方法,但这里暂不涉及。
下面,我们使用 PBG 对完整的 Freebase 图训练嵌入。现代服务器可以容纳这个规模的数据集 但 PGB 分区和分布式执行既节约了内存,也缩短了训练时间。我们发布了 Wikidata 的首次嵌入,这是一个相似数据中更新的知识图。

我们还评估了几个公开的社交图数据集的 PBG 嵌入,发现 PBG 优于其他竞争方法,并且分区和分布式执行减少了内存使用和培训时间。对于知识图、分区或分布式执行使得训练对超参数和建模选择更加敏感。然而对于社交图来说,嵌入质量似乎对分区和并行化选择并不敏感。
利用分布式训练的优势进行嵌入
PBG 允许 AI 社区为大规模图(包括知识图谱)以及其他如股票交易图、在线内容图和生物数据图训练嵌入,而无需专门的计算资源(如 GPU 或大量内存)。我们还希望 PBG 将成为小型公司和机构的有用工具,他们可能拥有大型图数据集,但没有将这些数据应用到其 ML 应用程序的工具。
虽然我们在 Freebase 等数据集上演示了 PBG,但 PBG 真正的设计意图是处理比此图大 10~100 倍的图。我们希望这能鼓励实践者发布和试验更大的数据集。计算机视觉(通过对标签的 Deep Learning 来改进图像识别质量)和自然语言处理(word2vec、BERT、Elmo)的最新突破是对海量数据集进行未知任务预训练的结果。我们希望通过对大规模图的无监督学习,最终能够得到更好的图结构化数据推理算法。
-
Facebook
+关注
关注
3文章
1428浏览量
54031 -
人工智能
+关注
关注
1776文章
43845浏览量
230596 -
开源
+关注
关注
3文章
2985浏览量
41718 -
pytorch
+关注
关注
2文章
761浏览量
12831
原文标题:Facebook开源图嵌入“神器”:无需GPU,高效处理数十亿级实体图形 | 极客头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论